目录
1.概述
1.1 什么是TSNE
- TSNE是由T和SNE组成,T分布和随机近邻嵌入(Stochastic neighbor Embedding).
- TSNE是一种可视化工具,将高位数据降到2-3维,然后画成图。
- t-SNE是目前效果最好的数据降维和可视化方法
- t-SNE的缺点是:占用内存大,运行时间长。
1.2 TSNE原理
1.2.1入门的原理介绍
举一个例子,这是一个将二维数据降成一维的任务。我们要怎么实现?
首先,我们想到的最简单的方法就是舍弃一个维度的特征,将所有点映射到x轴上:
很明显,结果来看,蓝色和黄色的点交叠在一起,可是他们在二维上明明不属于一类
{kind=link}
TSNE就是计算某一个点到其他所有点的距离,然后映射到t分布上,效果就会好一些。
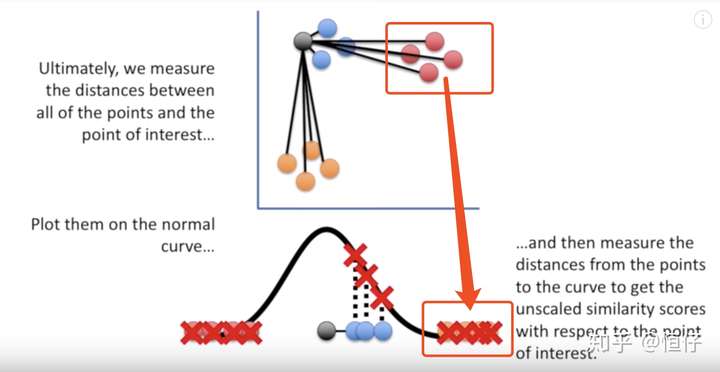{kind=link}
1.2.2进阶的原理介绍
- t-SNE的降维关键:把高纬度的数据点之间的距离转化为高斯分布概率。
1.2.2.1 高维距离表示
- 如果两个点在高维空间距离越近,那么这个概率值越大。
- 我们来看下面公式,两个公式的内容一致,只是写法不同。
[P_{j|i} = frac{e^{frac{-||x_i-x_j||^2}{2sigma_i^2}}}{sum_{i
ot=k}e^{frac{-||x_i-x_k||^2}{2sigma_i^2}}}
]
这个形式的公式,只是明显的展示这是高斯分布概率
[P_{j|i} = frac{exp(-||x_i-x_k||^2/(2sigma_i^2))}{sum_{i
ot=k}exp(-||x_i-x_k||^2/(2sigma_i^2))}
]
(||x_i-x_k||^2)是两个点之间的距离;
距离越大,(exp(-||x_i-x_k||^2/(2sigma_i^2)))越小;
距离越小,(exp(-||x_i-x_k||^2/(2sigma_i^2)))越大;
分母是一个常数,对于一个固定的点(x_i);
- 这个算法的创新点:(sigma_i)对于每一个(x_i)都是不同的,是由事先设定的困惑性影响,(sigma_i)是自动设定的。
现在我们能得到(p_{j|i}),然后计算联合分布
[P_{ij} = frac{P_{j|i}+P_{i|j}}{2N}
]
- 从上文中,我们用高斯分布概率来表示两个高维点之间的相似性,再次复述一次两个点越相似,(p_{ij})越大
1.2.2.2 低维相似度表示
- 在低纬度中,我们使用t分布来表示相似性。这里不探究为什么使用t分布而不是其他分布,具体内容可以看论文
[Q_{ij} = frac{(1+||y_i-y_j||^2)^{-1}}{sum_{k
ot=l}(1+||y_k-y_l||^2)^{-1}}
]
(y_i,y_j)是低纬度的点
1.2.2.3 惩罚函数
- 现在我们有方法衡量高纬度和低纬度的点的相似性,我们如何保证高纬度相似度高的点在低纬度相似度也高?
- t-SNE使用的是KL散度(Kullback-Leibler divergence)
[KL(P|Q) = sum_{i
ot=j}P_{ij}logfrac{P_{ij}}{Q_{ij}}
]
1.2.2.4 为什么是局部相似性
- 当(P_{ij})很大,(Q_{ij})很小(高维空间距离近,低维空间距离远)的惩罚很大,但是高维空间距离远,低维空间距离近的惩罚小。
1.2.2.5 为什么选择高斯和t分布
- 降维必然带来信息损失,TSNE保留局部信息必然牺牲全局信息,而因为t分布比 高斯分布更加长尾,可以一定程度减少这种损失。
2 python实现
函数参数表:
- parameters 描述
- n_components 嵌入空间的维度
- perpexity 混乱度,表示t-SNE优化过程中考虑邻近点的多少,默认为30,建议取值在5到50之间
- early_exaggeration 表示嵌入空间簇间距的大小,默认为12,该值越大,可视化后的簇间距越大
- learning_rate 学习率,表示梯度下降的快慢,默认为200,建议取值在10到1000之间
- n_iter 迭代次数,默认为1000,自定义设置时应保证大于250
- min_grad_norm 如果梯度小于该值,则停止优化。默认为1e-7
- metric 表示向量间距离度量的方式,默认是欧氏距离。如果是precomputed,则输入X是计算好的距离矩阵。也可以是自定义的距离度量函数。
- init 初始化,默认为random。取值为random为随机初始化,取值为pca为利用PCA进行初始化(常用),取值为numpy数组时必须shape=(n_samples, n_components)
- verbose 是否打印优化信息,取值0或1,默认为0=>不打印信息。打印的信息为:近邻点数量、耗时、σ
、KL散度、误差等 - random_state 随机数种子,整数或RandomState对象
- method 两种优化方法:barnets_hut和exact。第一种耗时O(NlogN),第二种耗时O(N^2)但是误差小,同时第二种方法不能用于百万级样本
- angle 当method=barnets_hut时,该参数有用,用于均衡效率与误差,默认值为0.5,该值越大,效率越高&误差越大,否则反之。当该值在0.2-0.8之间时,无变化。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import manifold,datsets
'''X是特征,不包含target;X_tsne是已经降维之后的特征'''
tsne = manifold.TSNE(n_components=2, init='pca', random_state=501)
X_tsne = tsne.fit_transform(X)
print("Org data dimension is {}.
Embedded data dimension is {}".format(X.shape[-1], X_tsne.shape[-1]))
'''嵌入空间可视化'''
x_min, x_max = X_tsne.min(0), X_tsne.max(0)
X_norm = (X_tsne - x_min) / (x_max - x_min) # 归一化
plt.figure(figsize=(8, 8))
for i in range(X_norm.shape[0]):
plt.text(X_norm[i, 0], X_norm[i, 1], str(y[i]), color=plt.cm.Set1(y[i]),
fontdict={'weight': 'bold', 'size': 9})
plt.xticks([])
plt.yticks([])
plt.show()