可以骂人吗???辛辛苦苦写了2个多小时搞到凌晨2点,点击保存草稿退回到了登录页面???登录成功草稿没了???喵喵喵???智障!!气!
很厉害,隔了30分钟,我的登录又失效了,草稿再次回滚,不客气了,***!
仔细想想,自动保存功能也挺可疑的,根据我半年的资深前端经验判断,内部实现大概是这样:
var id;
// *core event* window.addEventListener('keyup',function(){
if(id){clearTimout(id);} id = setTimeout(function(){ // user would be relieved to see this... $('#...').html('本地自动保存于' + (new Date()).toLocaleTimeString() + ',<a href="javascript:void(0);">查看</a>') },1000*Math.random()); });
如此智能的功能只能用这样优雅的代码实现了吧,社会社会!
重写。
上篇讲完了ArrayList,这篇继续补完LinkedList的内容。
首先上一张图来整体看一眼链表的结构(还好图在):
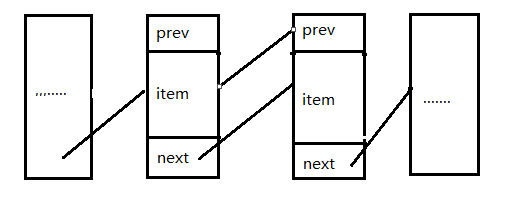
每一个大方块代表一个节点(Node),内部包含3部分内容:
1、前指针:指向上一个节点,头部元素指向null
2、数据:保存的数据内容
3、后指针:指向下一个节点,尾部元素指向null
Node是一个类,而且是一个私有+静态+内部类,buff齐全,看一眼实现:
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
非常简单暴力,3个变量,一个构造函数,没啥解释的。
老规矩,首先从变量开始看起。
变量
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable { transient int size = 0; transient Node<E> first; transient Node<E> last; }
3个变量,size代表当前链表长度,first与last分别指向头部与尾部节点。
构造函数
有两个构造函数:
public LinkedList() { } public LinkedList(Collection<? extends E> c) { this(); addAll(c); }
其中无参构造函数啥事也不做,另外一个构造函数允许以指定集合初始化链表。
这里的addAll只是一个重载版本
public boolean addAll(Collection<? extends E> c) { return addAll(size, c); }
指向真正的addAll,在指定的位置插入链表,初始化的话size为0
public boolean addAll(Collection<? extends E> c) { return addAll(size, c); }
直接看addAll的源码:
public boolean addAll(int index, Collection<? extends E> c) { checkPositionIndex(index); Object[] a = c.toArray(); int numNew = a.length; if (numNew == 0) return false; Node<E> pred, succ; if (index == size) { succ = null; pred = last; } else { succ = node(index); pred = succ.prev; } for (Object o : a) { @SuppressWarnings("unchecked") E e = (E) o; Node<E> newNode = new Node<>(pred, e, null); if (pred == null) first = newNode; else pred.next = newNode; pred = newNode; } if (succ == null) { last = pred; } else { pred.next = succ; succ.prev = pred; } size += numNew; modCount++; return true; }
函数比较长,主要分为4步:
1、索引合法性检测
2、将集合拆分为数组并检测长度,如果为0不做操作直接返回false
3、根据插入位置分情况做插入
4、插入操作
首先第一步,比较简单:
private void checkPositionIndex(int index) { if (!isPositionIndex(index)) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); }
private boolean isPositionIndex(int index) { return index >= 0 && index <= size; }
判断插入索引是否在允许范围内,抛异常。
第二步的插入分两种:
1、尾部插入
2、其他
先看尾部插入的情况,即size==index:
succ = null; pred = last;for (Object o : a) { @SuppressWarnings("unchecked") E e = (E) o; Node<E> newNode = new Node<>(pred, e, null); if (pred == null) first = newNode; else pred.next = newNode; pred = newNode; } if (succ == null) { last = pred; } else { pred.next = succ; succ.prev = pred; }
在for循环中,每次都会生成一个新的Node,前指针指向pred(第一个为链表尾元素),数据为类型转换后的集合元素。
然后将pred的尾指针指向新生成的节点,最后将pred置为该节点。
依次插入集合元素后,由于是尾部插入,所以last应该是最后插入的元素,即last=pred。
第二种情况是中间插入,详细过程就不写了,心情有点糟糕。
方法
有了addAll,其他的方法就很简单了。
getFirst/Last
public E getFirst() { final Node<E> f = first; if (f == null) throw new NoSuchElementException(); return f.item; } public E getLast() { final Node<E> l = last; if (l == null) throw new NoSuchElementException(); return l.item; }
两个get方法分别返回链表的头部与尾部元素,判断是否存在并返回对应的item。
remove
public E removeFirst() { final Node<E> f = first; if (f == null) throw new NoSuchElementException(); return unlinkFirst(f); } public E removeLast() { final Node<E> l = last; if (l == null) throw new NoSuchElementException(); return unlinkLast(l); }
两个删除方法也分别移除头部与尾部元素,方法就看一下unlinkFirst够了。
private E unlinkFirst(Node<E> f) { final E element = f.item; final Node<E> next = f.next; f.item = null; f.next = null; // help GC first = next; if (next == null) last = null; else next.prev = null; size--; modCount++; return element; }
这里将头部数据先缓存起来,然后将头部元素移除,将首元素设置为第二个节点,将第二个节点的prev置null。
如果第二个节点为null,说明链表中没有元素了,于是last也置null。
getIndex
最后看一下获取指定索引的数据
Node<E> node(int index) { if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }
这里不是单纯的从头遍历,而是做了一个小判断,如果索引在前半截,则从头往后遍历,否则相反。这样就将时间复杂度降低到o(n/2),但是只有双向链表才有。
剩余的方法都没有什么营养,有兴趣的可以自行研究,画画图简单的很。
最后总结一下ArrayList与LinkedList。
1、两者都是基本的容器,可以按顺序存储元素而且不用担心容器大小
2、搜索上ArrayList由于底层是数组,所以时间复杂度为o(1),而LinkedList为o(2/n)
3、插入元素时,ArrayList需要考虑扩容、变动索引后面元素,而链表最多只需要变动2个节点
4、虽然总体看起来ArrayList更弱,但是链表Node本身的复杂度也不容忽视,如果只为了读取还是尽量用ArrayList。