node的源码分析还挺多的,不过像我这样愣头完全平铺源码做解析的貌似还没有,所以开个先例,从一个API来了解node的调用链。
首先上一张整体的图,网上翻到的,自己懒得画:
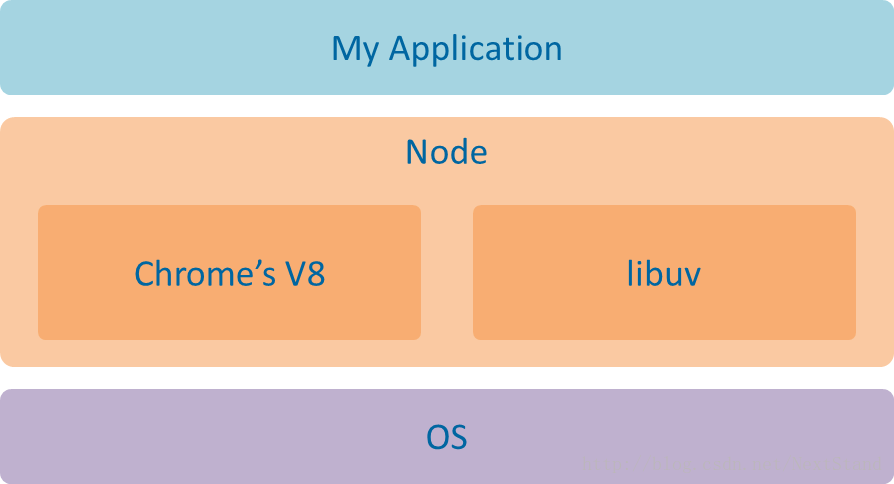
这里的层次结构十分的清晰,从上到下如果翻译成语言层面,依次是JS、C++、windows(UNIX)的系统API。
最高层也就是我们自己写的JS代码,node会首先通过V8引擎进行编译解析成C++,随后将其分发给libuv,libuv根据操作系统的类型来分别调用底层的系统API。
下面通过fs.stat这个API来一步步探索整个过程。
JS => require('fs')
这个方法的调用从开发者的角度讲,只需要两行代码:
const fs = require('fs'); fs.stat(path, [options], callback);
其中第一步,是获取内置模块fs,第二步,就是调用对应的方法。
其实两个可以合一起讲了,弄懂了模块来源,对应的api也就简单了。
在前面几章,只是很模糊和浅显的讲了一个注册内置模块的过程,其实在node的目录,有一个本地的JS库,简单的处理了参数:
// node/lib/fs.js fs.stat = function(path, callback) { callback = makeStatsCallback(callback); path = getPathFromURL(path); validatePath(path); const req = new FSReqWrap(); req.oncomplete = callback; // const binding = process.binding('fs'); binding.stat(pathModule.toNamespacedPath(path), req); };
这是方法的源码,需要注意的只有最后一行,通过binding.stat来调用下层的C++代码,而这个binding是来源于process对象。
在之前内置模块初探的时候,我提到过一个代码包装,就是对于require的JS文件的外层有一个简单的wrap:
NativeModule.wrapper = [ '(function (exports, require, module, process) {', ' });' ]; NativeModule.wrap = function(script) { return NativeModule.wrapper[0] + script + NativeModule.wrapper[1]; }; source = NativeModule.wrap(source);
这里的script对应的就是JS文件字符串,实际上最后生成的其实是一个自调用匿名函数。
node => process.binding
隐去了V8引擎编译JS代码的过程(主要这一步很恶心,暂时不想讲),直接进入C++模块。
这个方法在内置模块引入时也提到过,就是GetBinding方法:
static void GetBinding(const FunctionCallbackInfo<Value>& args) { // ... // 找到对应的模块节点 node_module* mod = get_builtin_module(*module_v); Local<Object> exports; if (mod != nullptr) { // 初始化并返回一个对象 exports = InitModule(env, mod, module); } // ... }
需要关注的代码只有get_builtin_module和InitModule两个。
在前面的某一章我讲过,node初始化会通过NODE_BUILTIN_MODULES宏将所有内置模块的相关信息整理成一个链表,通过一个静态指针进行引用。
所以,这里就通过那个指针,找到对应名字的内置模块,代码如下:
node_module* get_builtin_module(const char* name) { // modlist_builtin就是那个静态指针 return FindModule(modlist_builtin, name, NM_F_BUILTIN); } inline struct node_module* FindModule(struct node_module* list,const char* name,int flag) { struct node_module* mp; // 遍历链表找到符合的模块信息 for (mp = list; mp != nullptr; mp = mp->nm_link) { if (strcmp(mp->nm_modname, name) == 0) break; } // 没找到的话mp就是nullptr CHECK(mp == nullptr || (mp->nm_flags & flag) != 0); return mp; }
这里传入的字符串是fs,而每一个模块信息节点的nm_modname代表模块名,所以直接进行字符串匹配就行了。
返回后只是第一步,第二步就开始真正的加载了:
static Local<Object> InitModule(Environment* env, node_module* mod, Local<String> module) { // 生成一个新对象作为fs Local<Object> exports = Object::New(env->isolate()); // ... mod->nm_context_register_func(exports, unused, env->context(), mod->nm_priv); return exports; }
这里调用的是模块内部的一个方法,从名字来看也很直白,即带有上下文的模块注册函数。
在前面生成模块链表的方法,有这么一段注释:
// This is used to load built-in modules. Instead of using // __attribute__((constructor)), we call the _register_<modname> // function for each built-in modules explicitly in // node::RegisterBuiltinModules(). This is only forward declaration. // The definitions are in each module's implementation when calling // the NODE_BUILTIN_MODULE_CONTEXT_AWARE. #define V(modname) void _register_##modname(); NODE_BUILTIN_MODULES(V) #undef V
从最后面一行可以看出,注册方法时来源于另外一个宏,如下:
#define NODE_BUILTIN_MODULE_CONTEXT_AWARE(modname, regfunc) NODE_MODULE_CONTEXT_AWARE_CPP(modname, regfunc, nullptr, NM_F_BUILTIN)
这个宏会在每一个单独的模块C++文件的末尾调用,形式大同小异,以fs模块为例:
NODE_BUILTIN_MODULE_CONTEXT_AWARE(fs, node::fs::Initialize)
这里的第一个参数fs是模块名,而第二个是初始化方法,一般来说负责初始化一个对象,然后给对象添加一些方法。
当然,以fs为例,看一下初始化的内容:
void Initialize(Local<Object> target, Local<Value> unused, Local<Context> context, void* priv) { Environment* env = Environment::GetCurrent(context); // ...大量SetMethod env->SetMethod(target, "mkdir", MKDir); env->SetMethod(target, "readdir", ReadDir); env->SetMethod(target, "stat", Stat); env->SetMethod(target, "lstat", LStat); env->SetMethod(target, "fstat", FStat); env->SetMethod(target, "stat", Stat); // ...还有大量代码 }
可见,初始化就是给传入的对象设置一些属性,属性名就是那些熟悉的api了。
这里只看stat,本地方法对应Stat,简化后如下:
static void Stat(const FunctionCallbackInfo<Value>& args) { Environment* env = Environment::GetCurrent(args); // 参数检测 options是可选的 const int argc = args.Length(); CHECK_GE(argc, 2); // 第一个参数必定是路径 BufferValue path(env->isolate(), args[0]); CHECK_NE(*path, nullptr); // 这玩意不管 FSReqBase* req_wrap_async = GetReqWrap(env, args[1]); if (req_wrap_async != nullptr) { // stat(path, req) // 注意倒数第二个参数!!! AsyncCall(env, req_wrap_async, args, "stat", UTF8, AfterStat, uv_fs_stat, *path); } else { // stat(path, undefined, ctx) // ... // 注意倒数第二个参数!!! int err = SyncCall(env, args[2], &req_wrap_sync, "stat", uv_fs_stat, *path); // ... } } // AsyncCall => AsyncDestCall template <typename Func, typename... Args> inline FSReqBase* AsyncDestCall(/*很多参数*/, Func fn, Args... fn_args) { // ... int err = fn(env->event_loop(), req_wrap->req(), fn_args..., after); // ... } template <typename Func, typename... Args> inline int SyncCall(/*很多参数*/, Func fn, Args... args) { // ... int err = fn(env->event_loop(), &(req_wrap->req), args..., nullptr); // ... }
省略了很多很多(大家都不想看)的代码,浓缩出了核心的调用,就是uv_fs_stat。
这里的if、else主要是区别同步和异步调用,那个after就是代表有没有callback,简单了解下就OK了。
libuv => uv_fs_stat
至此,正式进入第三阶段,libuv层级。
这个框架的代码十分清爽,给你们看一下:
int uv_fs_stat(uv_loop_t* loop, uv_fs_t* req, const char* path, uv_fs_cb cb) { int err; // 初始化一些信息 INIT(UV_FS_STAT); // 处理路径参数 err = fs__capture_path(req, path, NULL, cb != NULL); if (err) { return uv_translate_sys_error(err); } // 实际操作 POST; }
完全不用省略任何代码,每一步都很清晰,INIT宏的参数是一个枚举,该枚举类包含所有文件操作的枚举值。
这里首先是初始化stat相关的一些信息,如下:
#define INIT(subtype) do { if (req == NULL) return UV_EINVAL; uv_fs_req_init(loop, req, subtype, cb); } while (0) INLINE static void uv_fs_req_init(uv_loop_t* loop, uv_fs_t* req, uv_fs_type fs_type, const uv_fs_cb cb) { uv__once_init(); UV_REQ_INIT(req, UV_FS); req->loop = loop; req->flags = 0; // 只有这一步是类型相关的 req->fs_type = fs_type; req->result = 0; req->ptr = NULL; req->path = NULL; req->cb = cb; memset(&req->fs, 0, sizeof(req->fs)); }
因为代码比较简单直白,所以就懒得省略了。
这里的宏是一个公共宏,所有文件操作相关的调用都要经过这个宏来进行初始化。在参数上,loop(事件轮询)、req(文件操作的相关对象)、cb(回调函数)都基本上不会变,所以实际上唯一区别操作类型的只有subtype。
第二步是对路径的处理,我觉得应该不会有人想知道内容是什么。
所以直接进入最后一步,POST。这个框架也真是可以的,所有的文件操作都通过三件套批量处理了。
这个宏如下:
#define POST do { if (cb != NULL) { uv__req_register(loop, req); uv__work_submit(loop, &req->work_req, uv__fs_work, uv__fs_done); return 0; } else { uv__fs_work(&req->work_req); return req->result; } } while (0)
cb来源于node调用中的最后一个参数,同步情况下传的是一个Undefined,并不需要一个回调函数。
对于开发者来说同步异步可能只是书写流程的小变化,但是对于libuv来说却不太一样,因为框架本身同时掌控着事件轮询,在异步情况下,这里的处理需要单独开一个线程进行处理,随后通过观察者模式通知异步调用结束,需要执行回调函数。
另外一个不同点是,同步调用直接返回一个结果,异步调用会包装结果作为回调函数的参数然后进行调用,通过上面的if、else结构也能看出来。
windowsAPI
这里的处理分同步和异步。
先看同步:
static void uv__fs_work(struct uv__work* w) { uv_fs_t* req; // ... #define XX(uc, lc) case UV_FS_##uc: fs__##lc(req); break; // 枚举值为UV_FS_STAT switch (req->fs_type) { // ... XX(CLOSE, close) XX(READ, read) XX(WRITE, write) XX(FSTAT, fstat) // ... default: assert(!"bad uv_fs_type"); } }
这个地方,上面的那个枚举值终于起了作用,省略了一些无关代码,最终的结果通过宏,指向了一个叫fs__fstat函数。
static void fs__fstat(uv_fs_t* req) { int fd = req->file.fd; HANDLE handle; VERIFY_FD(fd, req); // 保证可以获取到对应的文件句柄 handle = uv__get_osfhandle(fd); // 错误处理 if (handle == INVALID_HANDLE_VALUE) { SET_REQ_WIN32_ERROR(req, ERROR_INVALID_HANDLE); return; } // 这里进行变量赋值 if (fs__stat_handle(handle, &req->statbuf, 0) != 0) { SET_REQ_WIN32_ERROR(req, GetLastError()); return; } req->ptr = &req->statbuf; // 返回0 req->result = 0; }
这里有两个方法需要注意:
1、uv__get_osfhandle 获取文件句柄
2、fs__stat_handle 获取文件信息
源码如下:
INLINE static HANDLE uv__get_osfhandle(int fd) { HANDLE handle; UV_BEGIN_DISABLE_CRT_ASSERT(); // windowsAPI 根据文件描述符获取文件句柄 handle = (HANDLE) _get_osfhandle(fd); UV_END_DISABLE_CRT_ASSERT(); return handle; } INLINE static int fs__stat_handle(HANDLE handle, uv_stat_t* statbuf, int do_lstat) { // ... // windowsAPI nt_status = pNtQueryInformationFile(handle, &io_status, &file_info, sizeof file_info, FileAllInformation); /* Buffer overflow (a warning status code) is expected here. */ if (NT_ERROR(nt_status)) { SetLastError(pRtlNtStatusToDosError(nt_status)); return -1; } // windowsAPI nt_status = pNtQueryVolumeInformationFile(handle, &io_status, &volume_info, sizeof volume_info, FileFsVolumeInformation); // ...文件信息对象的处理 }
可以看出,最后的底层调用了windows的API来获取对应的文件句柄,然后继续获取对应句柄的文件信息,将信息处理后弄到req->ptr上,而node中对于同步处理的结果代码如下:
Local<Value> arr = node::FillGlobalStatsArray(env, static_cast<const uv_stat_t*>(req_wrap_sync.req.ptr)); args.GetReturnValue().Set(arr);
这里的req_wrap_sync.req.ptr就是上面通过windowAPI获取到的文件信息内容。
异步情况如下:
void uv__work_submit(uv_loop_t* loop, struct uv__work* w, void (*work)(struct uv__work* w), void (*done)(struct uv__work* w, int status)) { uv_once(&once, init_once); w->loop = loop; w->work = work; w->done = done; post(&w->wq); }
先看那个奇怪的post:
static void post(QUEUE* q) { // 上锁 uv_mutex_lock(&mutex); // 关于QUEUE的分析可见https://www.jianshu.com/p/6373de1e117d // 知道是个队列就行了 QUEUE_INSERT_TAIL(&wq, q); if (idle_threads > 0) uv_cond_signal(&cond); // 解锁 uv_mutex_unlock(&mutex); }
由于异步涉及到事件轮询,所以代码实质上要稍微复杂一点,但是总体来说并不需要关心那么多。
这里有一个空闲线程的判断,不管,直接看那个处理方法:
void uv_cond_signal(uv_cond_t* cond) { if (HAVE_CONDVAR_API()) uv_cond_condvar_signal(cond); else // 初始化一个状态变量防止线程的竞争情况 // 反正也是个windowsAPI uv_cond_fallback_signal(cond); } static void uv_cond_condvar_signal(uv_cond_t* cond) { // windowsAPI pWakeConditionVariable(&cond->cond_var); }
你会发现,这只是防止线程竞态而需要生成一个状态变量。
其实这个地方已经涉及到libuv中事件轮询的控制了,每次loop会从handle中取一个req,然后执行work,然后通知node完成,可以执行回调函数done了。
暂时不需要知道那么多,在uv__work_submit方法中,对应的赋值是这4个参数:
uv__work_submit(loop, &req->work_req, uv__fs_work, uv__fs_done);
其中第三个参数就是刚才同步获取文件信息的方法,而第四个就是在获取完毕会回调函数的调用:
static void uv__fs_done(struct uv__work* w, int status) { uv_fs_t* req; req = container_of(w, uv_fs_t, work_req); uv__req_unregister(req->loop, req); if (status == UV_ECANCELED) { assert(req->result == 0); req->result = UV_ECANCELED; } // 执行回调 req->cb(req); }
异步调用因为在回调函数带了结果,所以返回值不能跟同步一样,最后的处理有些许不一样:
template <typename Func, typename... Args> inline FSReqBase* AsyncDestCall(/*很多参数*/) { // ... if (err < 0) { // ... } else { req_wrap->SetReturnValue(args); } // 返回另外的值 return req_wrap; } void FSReqWrap::SetReturnValue(const FunctionCallbackInfo<Value>& args) { // 设成undefined args.GetReturnValue().SetUndefined(); }
简单讲,fs.statSync返回一个Stat对象,而fs.stat返回undefined。这个可以很简单的测试得到结果,我这里就不贴图了,已经够长了。