实验3 Spark读取文件系统的数据
1.在spark-shell中读取Linux系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数

2.在spark-shell中读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数
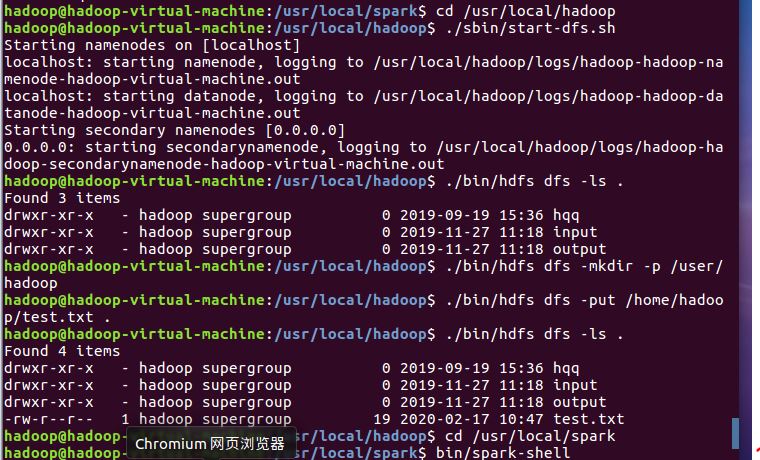

3.编写独立应用程序,读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;通过sbt工具将整个应用程序编译打包成 JAR包,并将生成的JAR包通过 spark-submit 提交到 Spark 中运行命令。

