半朴素贝叶斯分类器
朴素贝叶斯采用了“属性条件独立性假设”,但这个假设的确是有些草率了。因为往往属性之间包含着各种依赖。于是,人们尝试对这个假设进行一定程度的放松,由此产生了“半朴素贝叶斯分类器”。半朴素贝叶斯分类器的基本想法是适当考虑一部分属性间的相互依赖信息。独依赖估计是半朴素贝叶斯分类器最常用的一种策略。顾名思义,独依赖是假设每个属性在类别之外最多依赖一个其他属性。

其中,paj 为属性 xi 所依赖的属性,称为 xi 的父属性。假设父属性 paj 已知,那么可以使用下面的公式估计
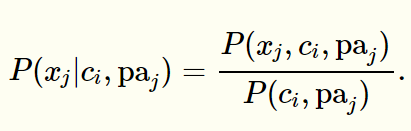
于是,问题的关键变成了如何确定每个属性的父属性。不同的做法产生了不同的独依赖分类器
-
SPODE(Super-Parent ODE)假设所有的属性都依赖于同一个属性,称为超父。
-
TAN(Tree Augmented naive Bayes)则在最大带权生成树算法的基础上发展的一种方法。
-
AODE(Averaged ODE)是一种集成学习的方法,尝试将每个属性作为超父来构建SPODE,与随机森林的方法有所相似。
TAN
1.计算任意属性之间的条件互信息

2.以属性为节点构建完全图,节点间的权重设为相应的互信息;
3.构建此完全图的最大带权生成树,挑选根变量,将边置为有向;
4.加入类别结点yy,增加从yy到每个属性的有向边。
容易看出,条件互信息 I(xi,xj|y) 刻画了属性 xi 和 xj 在已知类别情况下的相关性。因此,通过最大生成树算法,TAN实际上仅保留了强相关属性之间的依赖性。
在这里,我们通过将属性条件独立性假设放松为独立依赖假设,获得了泛化性能的提升。那么如果更进一步,考虑属性间的高阶依赖,能否可以进一步提升泛化性能呢?
也就是说,将第一个公式中的 paj 扩展为包含kk个属性的集合 paj ,从而将 ODE 拓展为 kDE 。需要注意的是,随着 k 的增加,准确地估计概率 P(xj|ci,paj) 所需的训练样本数量将以指数级增加。
因此,若训练数据非常充分,泛化性能有可能提升;但在有限样本的条件下,则会陷入估计高阶联合概率的泥沼。