0x00 scrapy爬虫框架
scrapy库的安装:
可以直接使用pip install scrapy来安装,如果IDE是pycharm的话参考之前requests库的安装
scrapy爬虫框架结构:
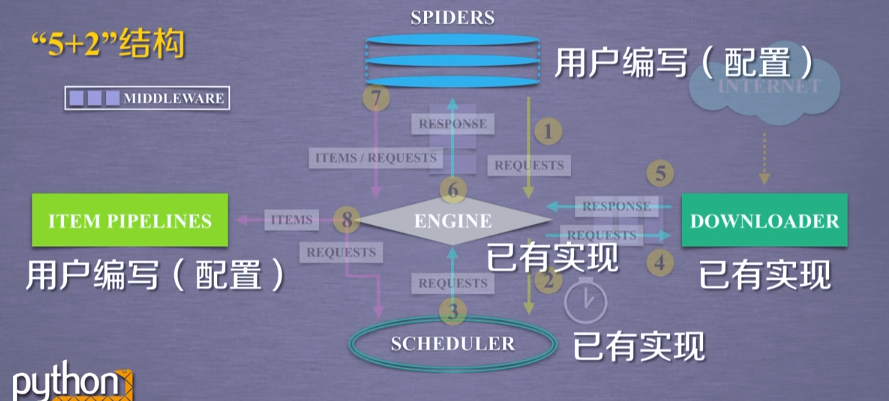
scrapy采用5+2的结构,五个主要模块加上两个中间键
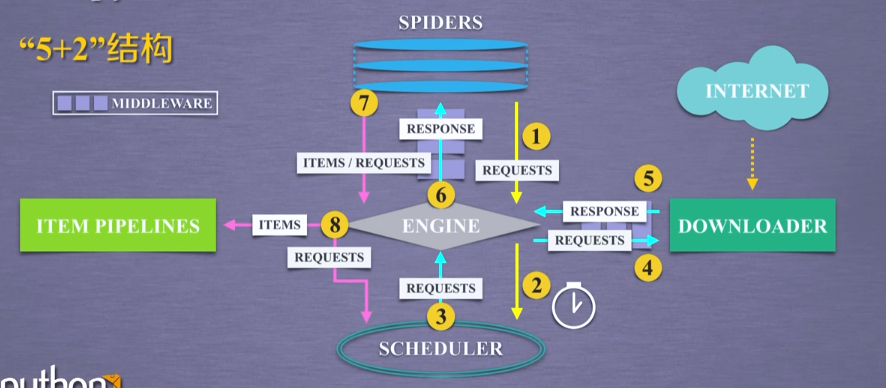
详细介绍一下各个组件:
- 引擎(Engine)
用来处理整个系统的数据流, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
这里需要用户去编写的是spider模块和pipeline模块,前者作为一个爬虫数据的入口,后者则是数据的出口
scrapy命令行格式:

命令:

0x01 scrapy爬虫框架实例
首先在cmd命令中新建一个scrapy的项目

这行命令就是在D盘的pycode文件夹中新建python123demo项目 ,接着可以直接导入pycharm中
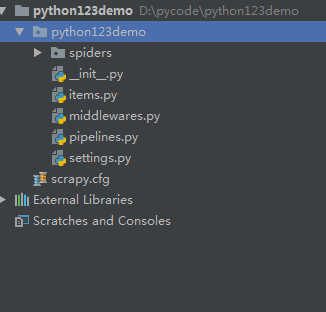
这里可以清楚地看到项目中已经给了我们一些文件

现在项目里都是空的,所以需要我们生成一个爬虫

这一段的意思就是生成一个名为demo的爬虫,爬取的网站是python123.io
回到pycharm中,我们发现spiders文件夹下生成了一个demo.py的文件

接下来就是要配置爬虫,修改demo.py文件,这段代码实现一个网页的下载
import scrapy class DemoSpider(scrapy.Spider): name = 'demo' #allowed_domains = ['python123.io'] start_urls = ['http://python123.io/ws/demo.html'] def parse(self, response): fname = response.url.split('/')[-1] with open(fname, 'wb') as f: f.write(response.body) self.log('Saved file %s.' % fname)
接着去cmd中执行命令运行爬虫

这里可能会报错,解决办法:ModuleNotFoundError: No module named 'win32api'

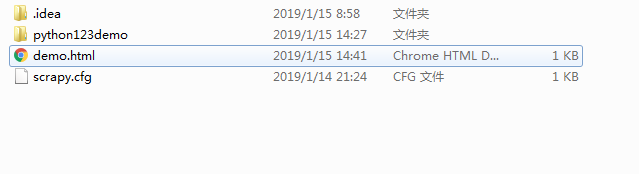
安装成功后执行原来的命令,成功在当前目录下生成demo.html文件
0x01 scrapy爬虫使用
yield关键字的使用:

举个例子:要遍历连续自然数的平方可以用一下代码实现:

第一段代码使用生成器的写法,gen()函数中每次执行yield命令时,i被冻结直到下一次调用该函数,而第二种方法首先将结果全部存入列表中,当数据量过大时会严重占用存储空间,增加代码运行时间。第一种方法每次进行一次调用,当数据量大的时候速度有明显优势。
scrapy爬虫的使用:
步骤1:创建一个工程和spider模板
步骤2:编写spider
步骤3:编写item pipeline
步骤4:优化配置策略
爬虫的数据类型:
①request类:像网络上提交请求的内容。
②response类:从网络上爬取内容的封装类。
③item类:由spider产生的信息封装的类

request的属性和方法:


response类的属性和方法:


scrapy爬虫提取信息的方法:

css selector的使用
