手写数字数据集
# 导入手写数据集 from sklearn.datasets import load_digits data = load_digits() print(data)
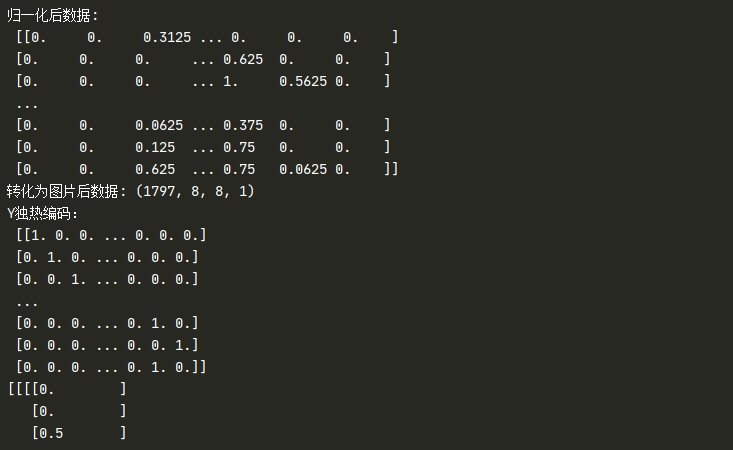
图片数据预处理
- x:归一化MinMaxScaler()
- y:独热编码OneHotEncoder()或to_categorical
- 训练集测试集划分
- 张量结构
"""
@author Rakers
"""
import numpy as np
# 导入手写数据集
from sklearn.datasets import load_digits
# 图片数据预处理 --归一化
from sklearn.preprocessing import MinMaxScaler
# OneHotEncoder独热编码
from sklearn.preprocessing import OneHotEncoder
# 切分数据集
from sklearn.model_selection import train_test_split
data = load_digits()
# x:归一化MinMaxScaler()
X_data = data['data'].astype(np.float32)
scaler = MinMaxScaler()
X_data = scaler.fit_transform(X_data)
print("归一化后数据:
",X_data)
# 转化为图片的格式
X=X_data.reshape(-1, 8, 8, 1)
print("转化为图片后数据:", X.shape)
# y:独热编码OneHotEncoder()
y = data['target'].astype(np.float32).reshape(-1, 1) # 将Y_data变为一列
Y = OneHotEncoder().fit_transform(y).todense() # 张量结构todense
print("Y独热编码:
", Y)
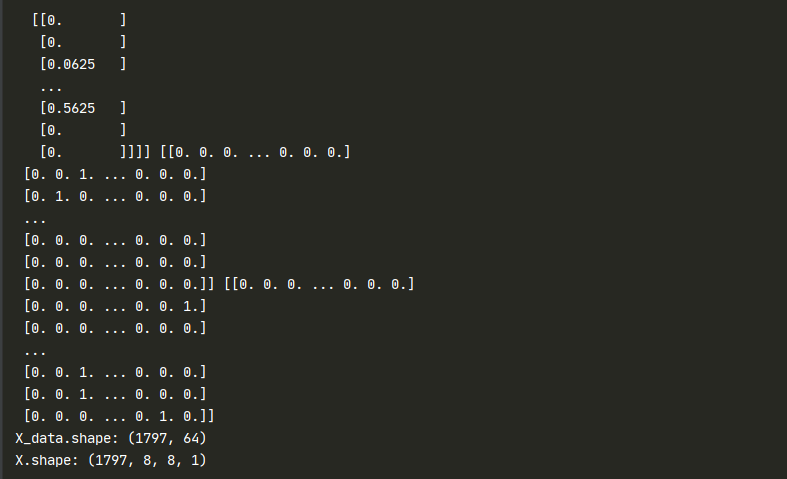
X_train,X_test,y_train,y_test = train_test_split(X, Y, test_size=0.2, random_state=0, stratify=Y)
print(X_train,X_test,y_train,y_test)
print("X_data.shape:",X_data.shape)
print("X.shape:",X.shape)
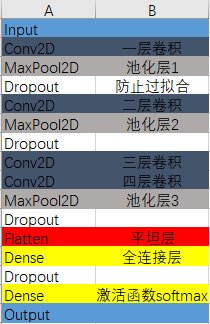
设计卷积神经网络结构
绘制模型结构图,设计依据。
"""
@author Rakers
"""
import numpy as np
# 导入手写数据集
from sklearn.datasets import load_digits
# 图片数据预处理 --归一化
from sklearn.preprocessing import MinMaxScaler
# OneHotEncoder独热编码
from sklearn.preprocessing import OneHotEncoder
# 切分数据集
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Dropout,Conv2D,MaxPool2D,Flatten
def buildModel(isPrintSummary=True, X_train=None):
"""
# 建立模型
:param isPrintSummary: 是否打印Summary信息
:return: 返回构建的模型
"""
model = Sequential()
ks = (3, 3) # 卷积核的大小
input_shape = X_train.shape[1:]
# 一层卷积,padding='same',tensorflow会对输入自动补0
model.add(Conv2D(filters=16, kernel_size=ks, padding='same', input_shape=input_shape, activation='relu'))
# 池化层1
model.add(MaxPool2D(pool_size=(2, 2)))
# 防止过拟合,随机丢掉连接
model.add(Dropout(0.25))
# 二层卷积
model.add(Conv2D(filters=32, kernel_size=ks, padding='same', activation='relu'))
# 池化层2
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 三层卷积
model.add(Conv2D(filters=64, kernel_size=ks, padding='same', activation='relu'))
# 四层卷积
model.add(Conv2D(filters=128, kernel_size=ks, padding='same', activation='relu'))
# 池化层3
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 平坦层
model.add(Flatten())
# 全连接层
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.25))
# 激活函数softmax
model.add(Dense(10, activation='softmax'))
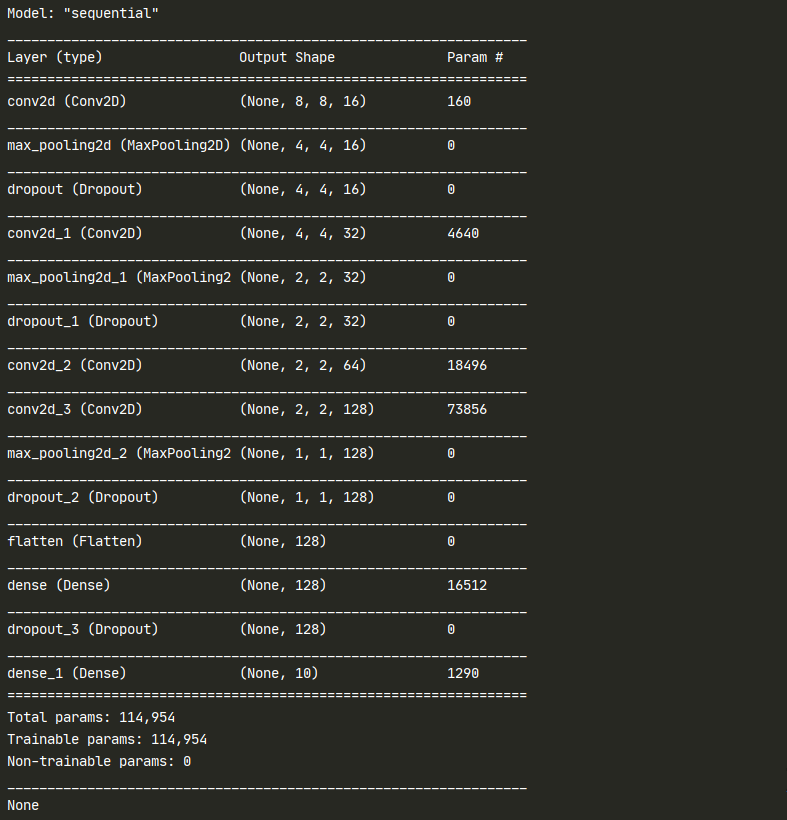
if isPrintSummary:
print(model.summary())
return model
if __name__ == "__main__":
data = load_digits()
# x:归一化MinMaxScaler()
X_data = data['data'].astype(np.float32)
scaler = MinMaxScaler()
X_data = scaler.fit_transform(X_data)
# print("归一化后数据:
", X_data)
# 转化为图片的格式
X = X_data.reshape(-1, 8, 8, 1)
# print("转化为图片后数据:", X.shape)
# y:独热编码OneHotEncoder()
y = data['target'].astype(np.float32).reshape(-1, 1) # 将Y_data变为一列
Y = OneHotEncoder().fit_transform(y).todense() # 张量结构todense
# print("Y独热编码:
", Y)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=0, stratify=Y)
print(X_train, X_test, y_train, y_test)
# print("X_data.shape:", X_data.shape)
# print("X.shape:", X.shape)
model = buildModel(X_train=X_train)
模型训练
"""
@author Rakers
"""
import numpy as np
import matplotlib.pyplot as plt
# 导入手写数据集
from sklearn.datasets import load_digits
# 图片数据预处理 --归一化
from sklearn.preprocessing import MinMaxScaler
# OneHotEncoder独热编码
from sklearn.preprocessing import OneHotEncoder
# 切分数据集
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Dropout,Conv2D,MaxPool2D,Flatten
def buildModel(isPrintSummary=True, X_train=None):
"""
# 建立模型
:param isPrintSummary: 是否打印Summary信息
:return: 返回构建的模型
"""
model = Sequential()
ks = (3, 3) # 卷积核的大小
input_shape = X_train.shape[1:]
# 一层卷积,padding='same',tensorflow会对输入自动补0
model.add(Conv2D(filters=16, kernel_size=ks, padding='same', input_shape=input_shape, activation='relu'))
# 池化层1
model.add(MaxPool2D(pool_size=(2, 2)))
# 防止过拟合,随机丢掉连接
model.add(Dropout(0.25))
# 二层卷积
model.add(Conv2D(filters=32, kernel_size=ks, padding='same', activation='relu'))
# 池化层2
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 三层卷积
model.add(Conv2D(filters=64, kernel_size=ks, padding='same', activation='relu'))
# 四层卷积
model.add(Conv2D(filters=128, kernel_size=ks, padding='same', activation='relu'))
# 池化层3
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 平坦层
model.add(Flatten())
# 全连接层
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.25))
# 激活函数softmax
model.add(Dense(10, activation='softmax'))
if isPrintSummary:
print(model.summary())
return model
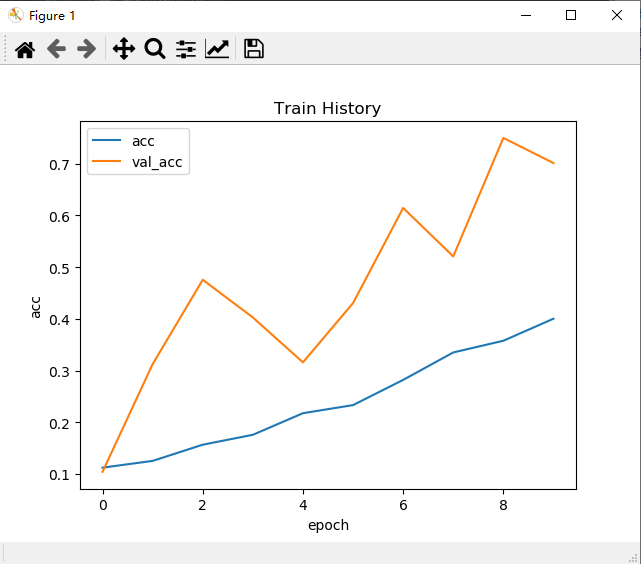
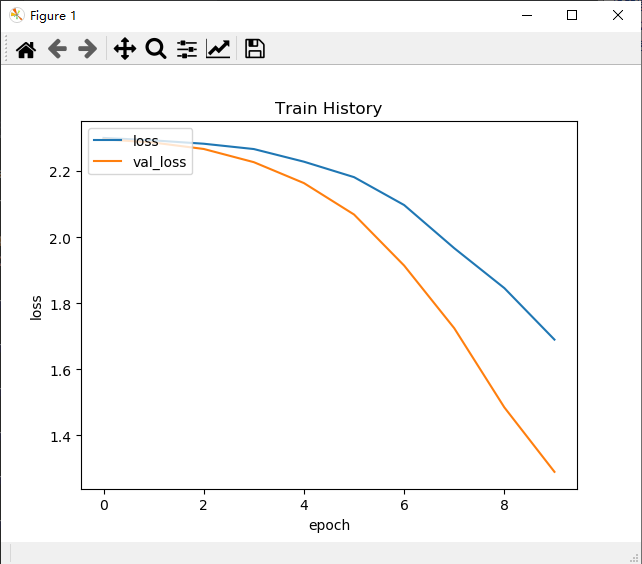
# 画Train History图
def show_train_history(train_history, train, validation):
"""
@author Rakers
:param train_history:
:param train:
:param validation:
:return:
"""
if train in train_history.history:
plt.plot(train_history.history[train])
if validation in train_history.history:
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel('train')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()
if __name__ == "__main__":
data = load_digits()
# x:归一化MinMaxScaler()
X_data = data['data'].astype(np.float32)
scaler = MinMaxScaler()
X_data = scaler.fit_transform(X_data)
# print("归一化后数据:
", X_data)
# 转化为图片的格式
X = X_data.reshape(-1, 8, 8, 1)
# print("转化为图片后数据:", X.shape)
# y:独热编码OneHotEncoder()
y = data['target'].astype(np.float32).reshape(-1, 1) # 将Y_data变为一列
Y = OneHotEncoder().fit_transform(y).todense() # 张量结构todense
# print("Y独热编码:
", Y)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=0, stratify=Y)
print(X_train, X_test, y_train, y_test)
# print("X_data.shape:", X_data.shape)
# print("X.shape:", X.shape)
model = buildModel(X_train=X_train)
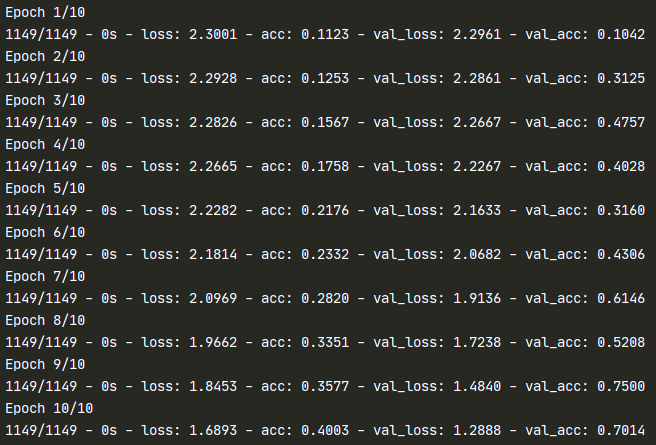
# 模型训练
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
train_history = model.fit(x=X_train, y=y_train, validation_split=0.2, batch_size=300, epochs=10, verbose=2)
# 准确率
show_train_history(train_history, 'acc', 'val_acc')
# 损失率
show_train_history(train_history, 'loss', 'val_loss')
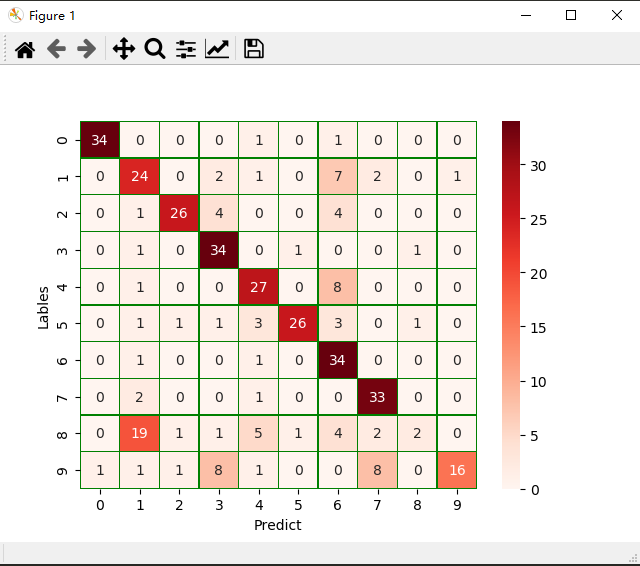
模型评价
- model.evaluate()
- 交叉表与交叉矩阵
- pandas.crosstab
- seaborn.heatmap
"""
@author Rakers
"""
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 导入手写数据集
from sklearn.datasets import load_digits
# 图片数据预处理 --归一化
from sklearn.preprocessing import MinMaxScaler
# OneHotEncoder独热编码
from sklearn.preprocessing import OneHotEncoder
# 切分数据集
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Dropout,Conv2D,MaxPool2D,Flatten
def buildModel(isPrintSummary=True, X_train=None):
"""
# 建立模型
:param isPrintSummary: 是否打印Summary信息
:return: 返回构建的模型
"""
model = Sequential()
ks = (3, 3) # 卷积核的大小
input_shape = X_train.shape[1:]
# 一层卷积,padding='same',tensorflow会对输入自动补0
model.add(Conv2D(filters=16, kernel_size=ks, padding='same', input_shape=input_shape, activation='relu'))
# 池化层1
model.add(MaxPool2D(pool_size=(2, 2)))
# 防止过拟合,随机丢掉连接
model.add(Dropout(0.25))
# 二层卷积
model.add(Conv2D(filters=32, kernel_size=ks, padding='same', activation='relu'))
# 池化层2
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 三层卷积
model.add(Conv2D(filters=64, kernel_size=ks, padding='same', activation='relu'))
# 四层卷积
model.add(Conv2D(filters=128, kernel_size=ks, padding='same', activation='relu'))
# 池化层3
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 平坦层
model.add(Flatten())
# 全连接层
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.25))
# 激活函数softmax
model.add(Dense(10, activation='softmax'))
if isPrintSummary:
print(model.summary())
return model
# 画Train History图
def show_train_history(train_history, train, validation):
"""
@author Rakers
:param train_history:
:param train:
:param validation:
:return:
"""
if train in train_history.history:
plt.plot(train_history.history[train])
if validation in train_history.history:
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('epoch')
plt.legend([train, validation], loc='upper left')
plt.show()
if __name__ == "__main__":
data = load_digits()
# x:归一化MinMaxScaler()
X_data = data['data'].astype(np.float32)
scaler = MinMaxScaler()
X_data = scaler.fit_transform(X_data)
# print("归一化后数据:
", X_data)
# 转化为图片的格式
X = X_data.reshape(-1, 8, 8, 1)
# print("转化为图片后数据:", X.shape)
# y:独热编码OneHotEncoder()
y = data['target'].astype(np.float32).reshape(-1, 1) # 将Y_data变为一列
Y = OneHotEncoder().fit_transform(y).todense() # 张量结构todense
# print("Y独热编码:
", Y)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=0, stratify=Y)
print(X_train, X_test, y_train, y_test)
# print("X_data.shape:", X_data.shape)
# print("X.shape:", X.shape)
model = buildModel(X_train=X_train)
# 模型训练
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
train_history = model.fit(x=X_train, y=y_train, validation_split=0.2, batch_size=300, epochs=10, verbose=2)
# 准确率
show_train_history(train_history, 'acc', 'val_acc')
# 损失率
show_train_history(train_history, 'loss', 'val_loss')
# 模型评价
score = model.evaluate(X_test, y_test)
print('score:', score)
# 预测值
y_pred = model.predict_classes(X_test)
print('y_pred:', y_pred[:10])
# 交叉表与交叉矩阵
y_test1 = np.argmax(y_test, axis=1).reshape(-1)
y_true = np.array(y_test1)[0]
# 交叉表查看预测数据与原数据对比
# pandas.crosstab
pd.crosstab(y_true, y_pred, rownames=['true'], colnames=['predict'])
# 交叉矩阵
# seaborn.heatmap
y_test1 = y_test1.tolist()[0]
a = pd.crosstab(np.array(y_test1), y_pred, rownames=['Lables'], colnames=['Predict'])
# 转换成属dataframe
df = pd.DataFrame(a)
sns.heatmap(df, annot=True, cmap="Reds", linewidths=0.2, linecolor='G')
plt.show()