团队名称、团队成员介绍、任务分配,团队成员课程设计博客链接
| 姓名 | 成员介绍 | 任务分配 | 课程设计博客地址 |
|---|---|---|---|
| 谢晓淞(组长) | 团队输出主力 | 爬虫功能实现,Web前端设计及其后端衔接 | 爬虫:https://www.cnblogs.com/Rasang/p/12169420.html |
| 前端设计:https://www.cnblogs.com/Rasang/p/12169449.html | |||
| 康友煌 | 团队智力担当 | Elasticsearch后台功能实现 | https://www.cnblogs.com/xycm/p/12168554.html |
| 闫栩宁 | 团队颜值担当 | GUI版搜索引擎实现 | https://www.cnblogs.com/20000519yxn/p/12169954.html |
项目简介,涉及技术
基于学院网站的搜索引擎,能够对学院网站的文章进行全文检索,时间范围检索,具有关键词联想功能。
项目前身:https://www.cnblogs.com/dycsy/p/8351584.html (借鉴16学长们的课设进行重做)
涉及技术:
- Jsoup
- HttpClient
- HTML+CSS
- Javascript/Jquery
- Elasticsearch
- IK analyzer
- Java Swing
- JSP
- 多线程
- Web
- Linux
项目git地址
https://github.com/rasang/searchEngine
项目git提交记录截图
前期调查
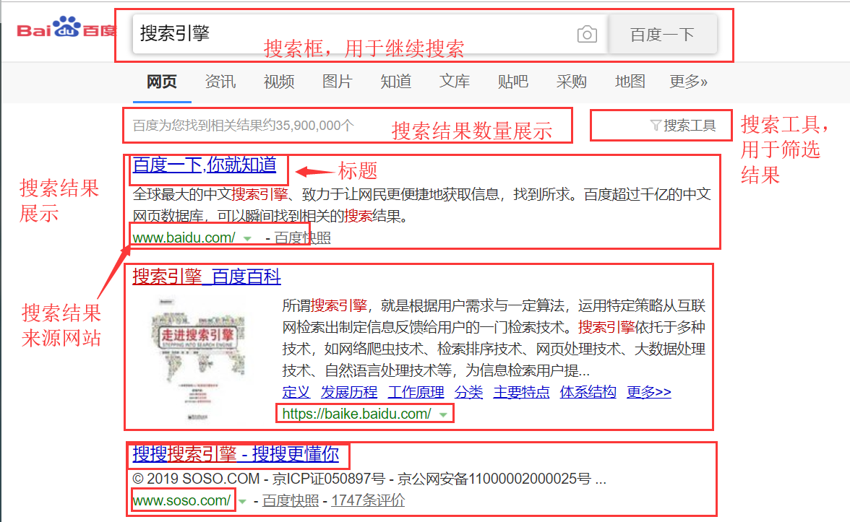
搜索主页界面

搜索结果界面
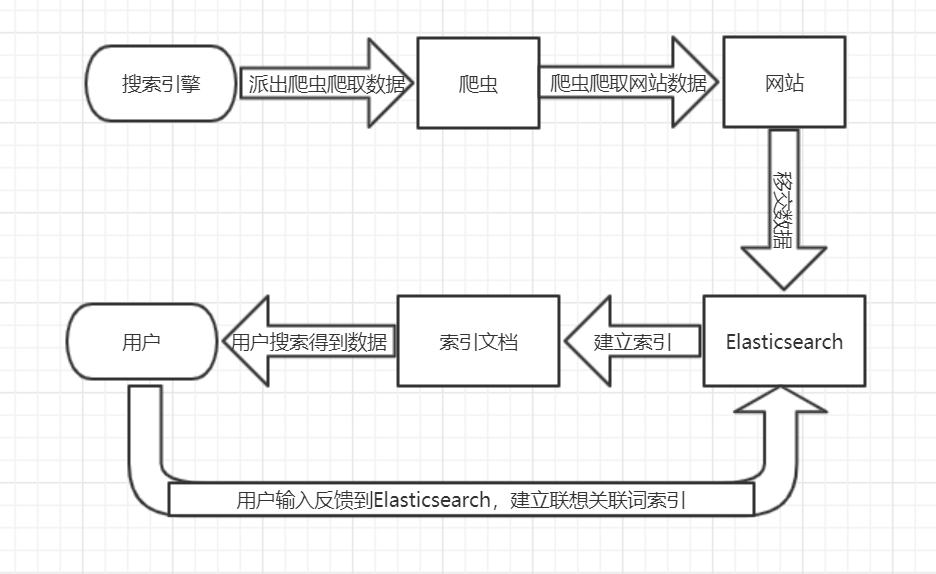
项目功能架构图、主要功能流程图
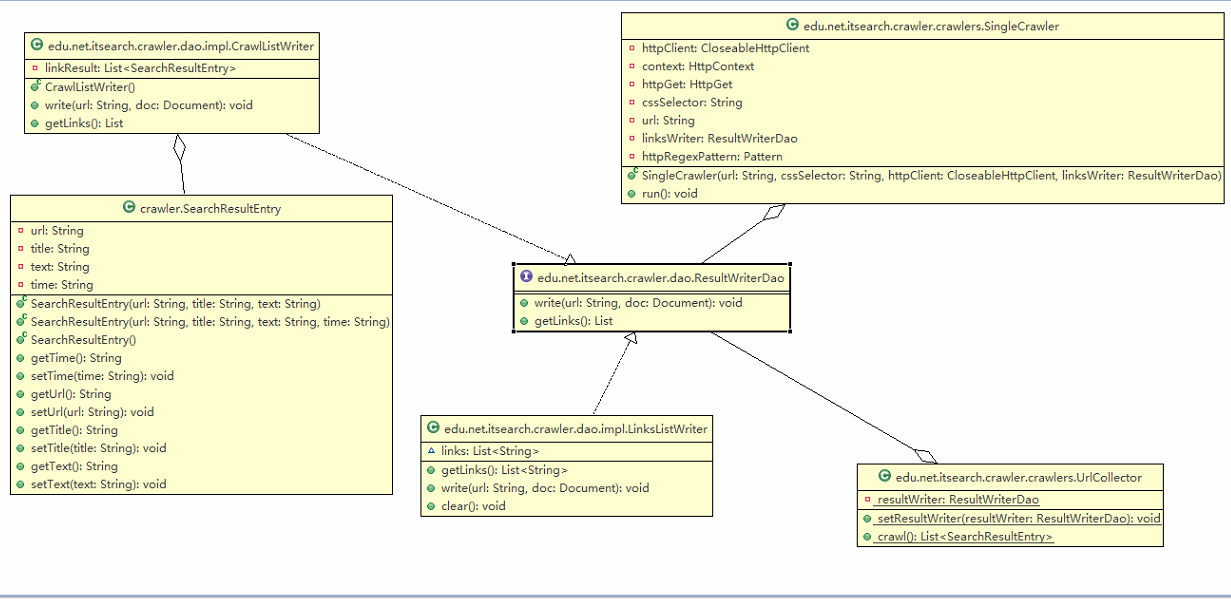
面向对象设计类图
爬虫类图
Elasticsearch类图
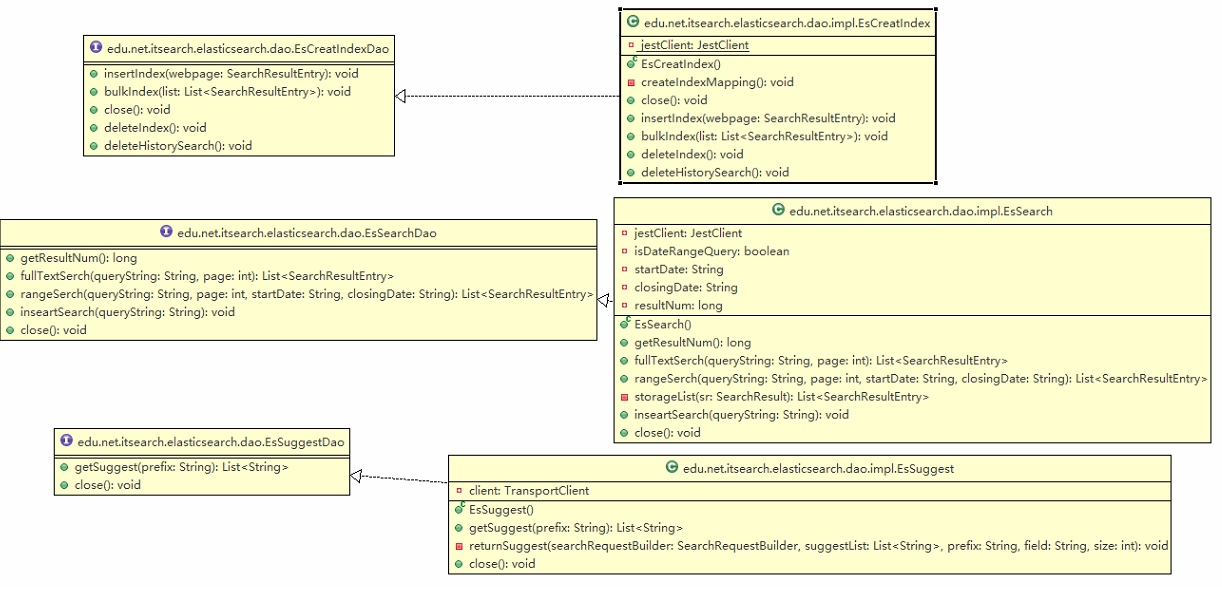
GUI类图

项目运行截图或屏幕录制
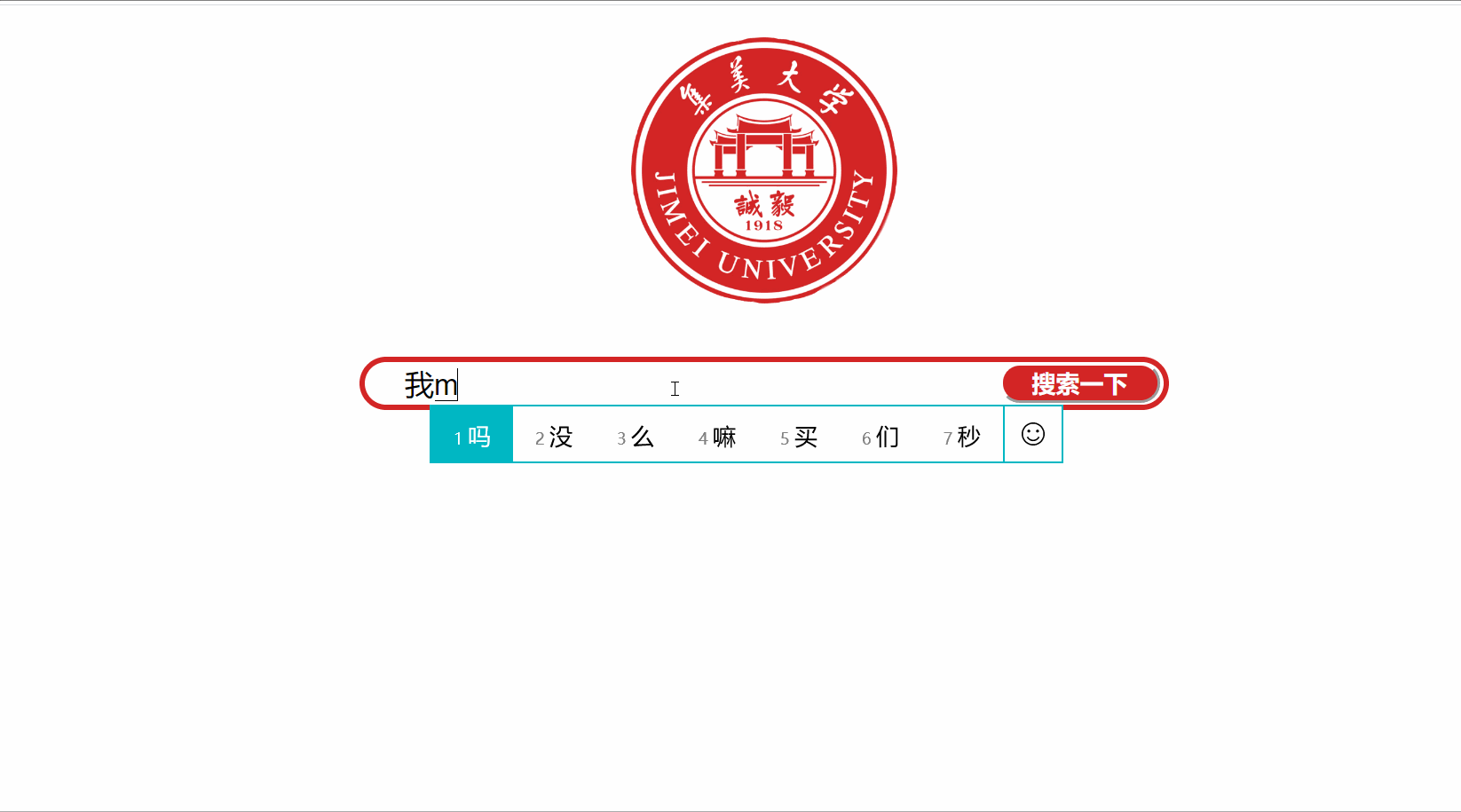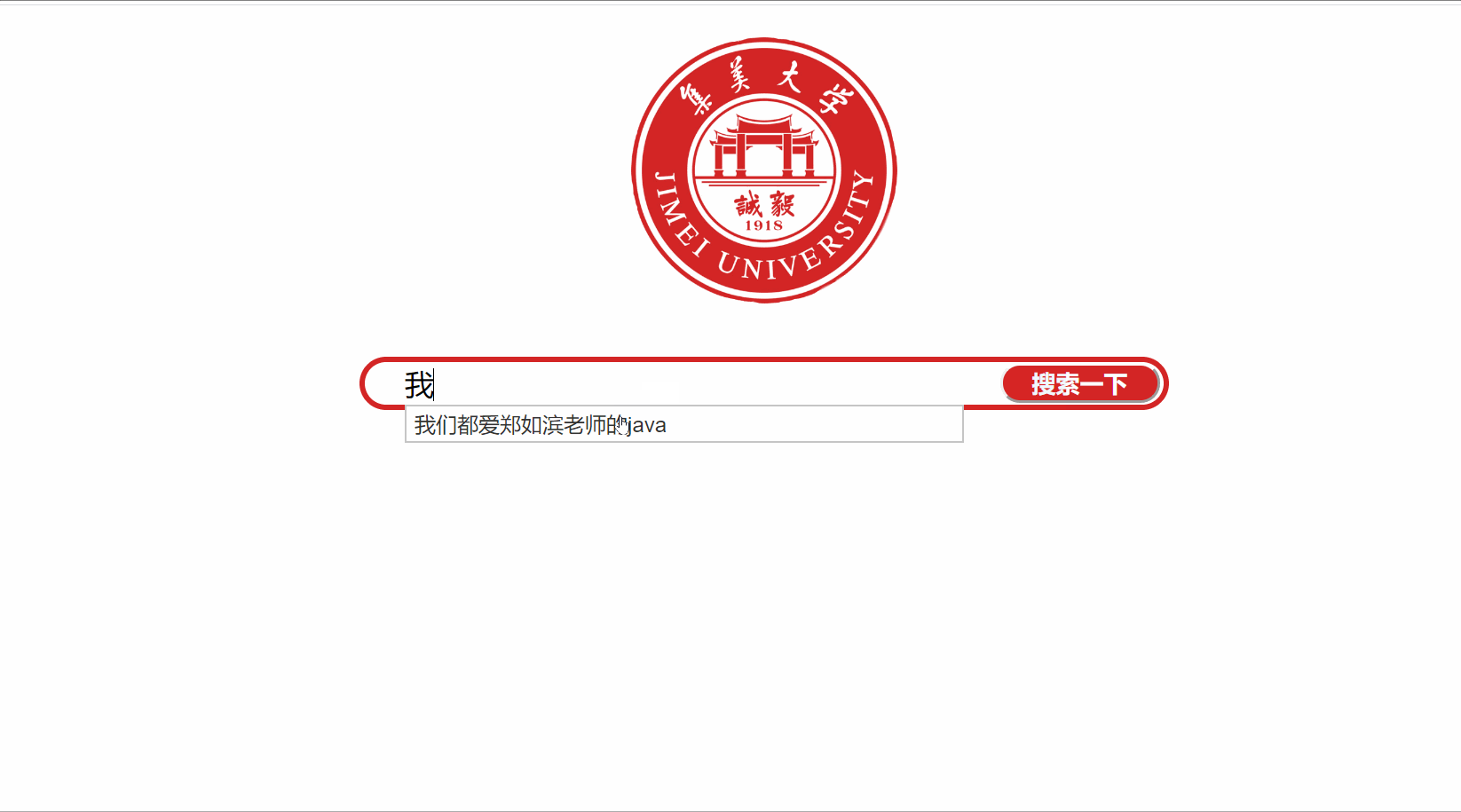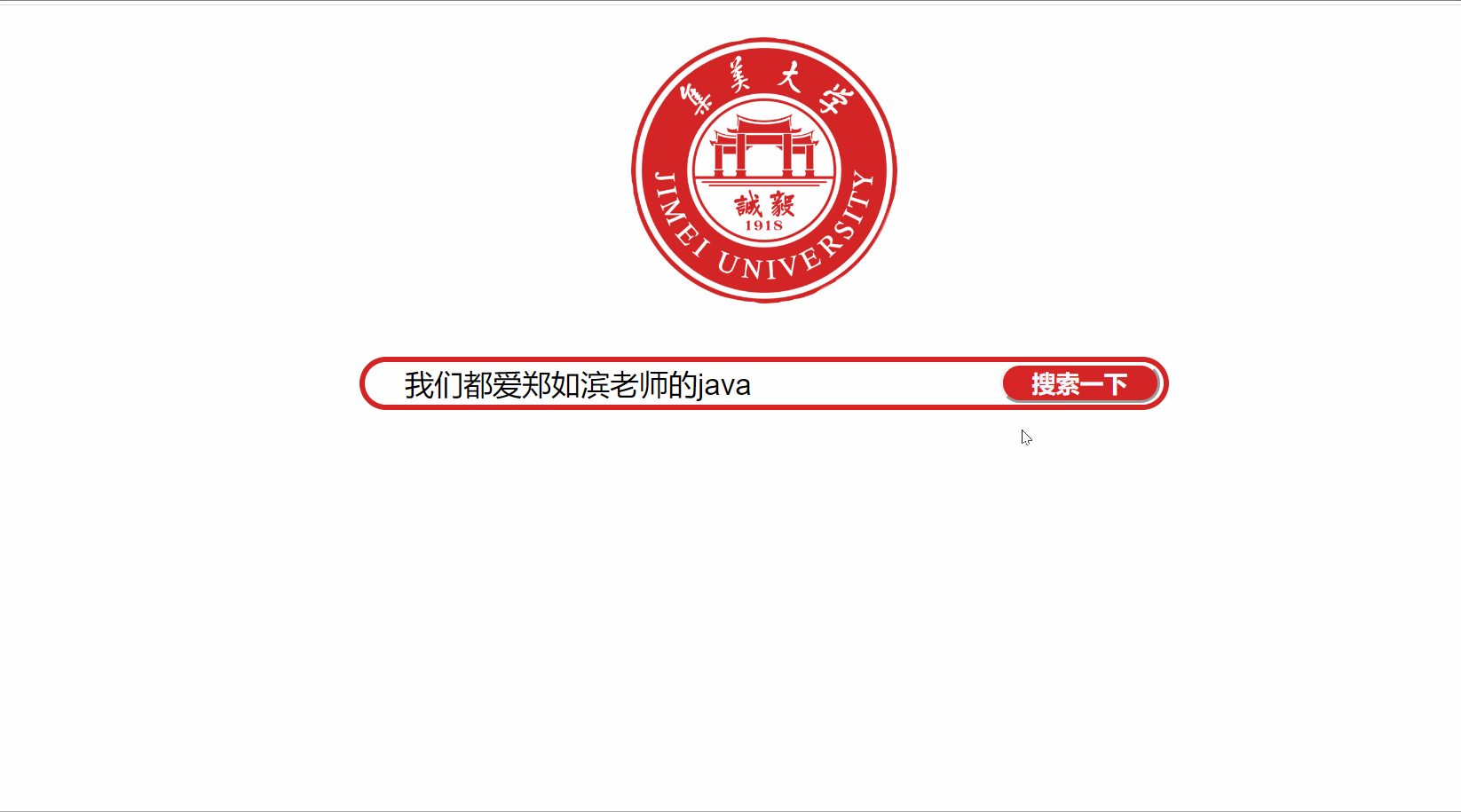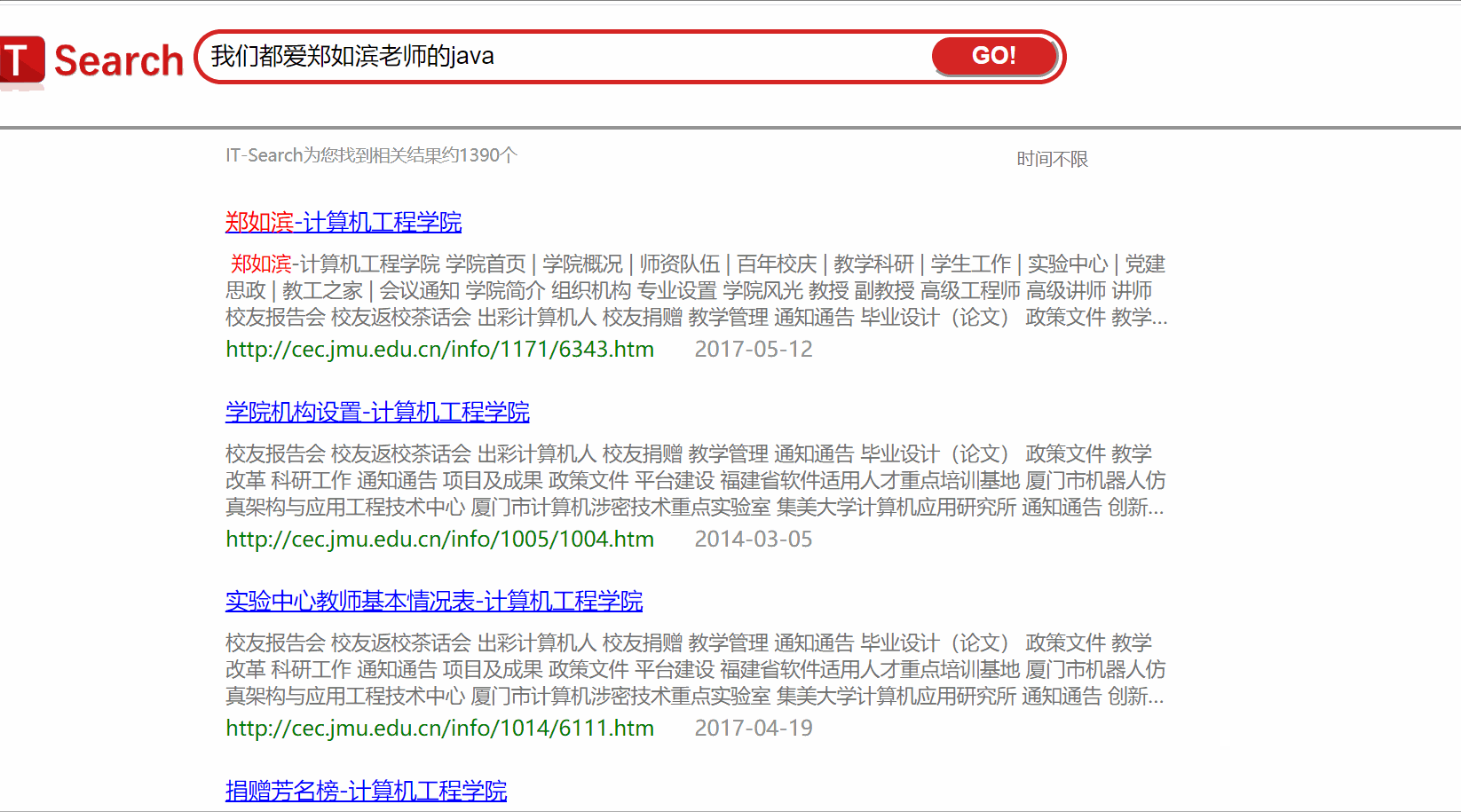
项目关键代码:模块名称-文字说明-关键代码
爬虫模块
SingleCrawler.java : 对单个页面进行爬取,并使用linksWriter进行数据保存
for (Element link : links) {
String newHref = link.attr("href");
String httpPattern = "^http";
Pattern p = Pattern.compile(httpPattern);
Matcher m = p.matcher(newHref);
if(m.find()){
continue;
}
String newUrl = null;
/**
* 判断href是相对路径还是决定路径,以及是否是传参
*/
if(newHref.length()>=1 && newHref.charAt(0)=='?') {
newUrl = this.url.substring(0, this.url.indexOf('?')) + newHref;
}
else if(newHref.length()>=1 && newHref.charAt(0)=='/') {
Matcher matcher = httpRegexPattern.matcher(this.url);
if(matcher.find()) {
String rootUrl = matcher.group(0);
newUrl = rootUrl + newHref.substring(1);
}
else {
continue;
}
}
else if(newHref.length()>=1 && newHref.charAt(0)!='/'){
Matcher matcher = httpRegexPattern.matcher(this.url);
if(matcher.find()) {
String rootUrl = matcher.group(0);
newUrl = rootUrl + newHref;
}
else {
continue;
}
}
else {
continue;
}
this.linksWriter.write(newUrl, doc);
}
UrlCollector.java :
爬取菜单URL
String url = "http://cec.jmu.edu.cn/";
String cssSelector = "a[href~=\.jsp\?urltype=tree\.TreeTempUrl&wbtreeid=[0-9]+]";
List<String> menu = null;
List<String> list = null;
PoolingHttpClientConnectionManager cm = new PoolingHttpClientConnectionManager();
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(cm).build();
LinksListWriter tempListWriter = new LinksListWriter();
/**
* 1. 第一层是Menu,先把Menu的href爬取下来
*/
SingleCrawler menuCrawler = new SingleCrawler(url, cssSelector, httpClient, tempListWriter);
menuCrawler.start();
try {
menuCrawler.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
menu = new ArrayList<String>(tempListWriter.getLinks());
爬取文章URL
SingleCrawler[] listCrawler = new SingleCrawler[menu.size()];
for (int i = 0; i < listCrawler.length; i++) {
String menuUrl = menu.get(i);
if(menuUrl.contains("?")) {
istCrawler[i] = new SingleCrawler(menu.get(i)+"&a3c=1000000&a2c=10000000", "a[href~=^info/[0-9]+/[0-9]+\.htm]", httpClient, tempListWriter);
listCrawler[i].start();
}
else {
listCrawler[i] = null;
}
}
爬取文章内容
SingleCrawler[] documentCrawler = new SingleCrawler[list.size()];
for (int i = 0; i < documentCrawler.length; i++) {
documentCrawler[i] = new SingleCrawler(list.get(i), "", httpClient, resultWriter);
documentCrawler[i].start();
}
Web前端
自动补全JS代码,监听search-input的input标签,当用户输入时会自动异步请求suggest.jsp页面,然后将返回的结果通过autocomplete呈现
$(function() {
$(".search-input").keyup(function(event) {
var jsonData = "";
$.ajax({
type : "get",
url : "suggest.jsp?term=" + document.getElementById("input").value,
datatype : "json",
async : true,
error : function() {
console.error("Load recommand data failed!");
},
success : function(data) {
data = JSON.parse(data);
$(".search-input").autocomplete({
source : data
});
}
});
})
});
JS实现翻页功能,主要是获取点击事件的元素,然后判断innerHTML的值:
function turnPage(e) {
page = e.innerHTML;
if (page == "«") {
var currentPage = GetQueryString("page");
//无page传参
if (currentPage == null) {
AddParamVal("page", 1);
}
//有page传参
else {
currentPage = parseInt(currentPage) - 1;
if (currentPage <= 0) currentPage = 1;
replaceParamVal("page", currentPage);
}
} else if (page == "»") {
var currentPage = GetQueryString("page");
//无page传参
if (currentPage == null) {
AddParamVal("page", 2);
}
//有page传参
else {
currentPage = parseInt(currentPage) + 1;
//if(currentPage<=0) currentPage=1;
replaceParamVal("page", currentPage);
}
} else {
var currentPage = GetQueryString("page");
//无page传参
if (currentPage == null) {
AddParamVal("page", parseInt(e.innerHTML));
}
//有page传参
else {
replaceParamVal("page", parseInt(e.innerHTML));
}
}
}
设置JQuery日期选择插件
$(function(){
if(GetQueryString("timeLimit")!=null){
var option=GetQueryString("timeLimit");
document.getElementById("test6").setAttribute("placeholder",option);
}
})
获得关键词并根据条件进行检索
String keyword = request.getParameter("keyword");
if(keyword!=null){
int pageCount = request.getParameter("page")==null?1:Integer.parseInt(request.getParameter("page"));
search = new EsSearch();
search.inseartSearch(keyword);
String timeLimit = request.getParameter("timeLimit");
if(timeLimit==null){
result = search.fullTextSerch(keyword,pageCount);
}
else{
String[] time = timeLimit.split(" - ");
result = search.rangeSerch(keyword, pageCount, time[0], time[1]);
}
}
打印搜索结果
if(result!=null){
for(int i=0;i<result.size();i++){
out.println("<div class="result-container">");
out.println("<a href=""+result.get(i).getUrl()+"" target="_blank" class="title">"+result.get(i).getTitle()+"</a>");
int index = result.get(i).getText().indexOf("<span style="color:red;">");
out.println("<div class="text">"+result.get(i).getText()+"</div>");
out.println("<div style="float: left;" class="url">"+result.get(i).getUrl()+"</div>");
out.println("<div style="float: left;color: grey;margin-left: 30px;margin-top: 4px;">"+result.get(i).getTime()+"</div>");
out.println("</div>");
out.println("<div class="clear"></div>");
}
}
Elasticsearch模块
jest API连接elasticsearch
public static JestClient getJestClient() {
if(jestClient==null) {
JestClientFactory factory = new JestClientFactory();
factory.setHttpClientConfig(new HttpClientConfig
.Builder("http://127.0.0.1:9200")
//.gson(new GsonBuilder().setDateFormat("yyyy-MM-dd HH:mm").create())
.multiThreaded(true)
.readTimeout(10000)
.build());
jestClient=factory.getObject();
}
return jestClient;
}
索引的创建与mapping的写入
public EsCreatIndex() {
jestClient =EsClient.getJestClient();
try {
jestClient.execute(new CreateIndex.Builder(EsClient.indexName).build());
jestClient.execute(new CreateIndex.Builder(EsClient.suggestName).build());
} catch (IOException e) {
e.printStackTrace();
}
this.createIndexMapping();
}
private void createIndexMapping() {
String sourceIndex="{"" + EsClient.typeName + "":{"properties":{"
+""title":{"type":"text","analyzer":"ik_max_word","search_analyzer":"ik_smart""
+ ","fields":{"suggest":{"type":"completion","analyzer":"ik_max_word","search_analyzer":"ik_smart"}}}"
+","text":{"type":"text","index":"true","analyzer":"ik_max_word","search_analyzer":"ik_smart"}"
+","url":{"type":"keyword"}"
+","time":{"type":"date"}"
+ "}}}";
PutMapping putMappingIndex=new PutMapping.Builder(EsClient.indexName, EsClient.typeName, sourceIndex).build();
String sourceSuggest="{"" + EsClient.typeName + "":{"properties":{"
+""text":{"type":"completion","analyzer":"ik_max_word","search_analyzer":"ik_smart"}"
+ "}}}";
PutMapping putMappingSuggest=new PutMapping.Builder(EsClient.suggestName, EsClient.typeName, sourceSuggest).build();
try {
jestClient.execute(putMappingIndex);
jestClient.execute(putMappingSuggest);
} catch (IOException e) {
e.printStackTrace();
}
}
插入数据
public void bulkIndex(List<SearchResultEntry> list) throws IOException {
Bulk.Builder bulk=new Bulk.Builder();
for(SearchResultEntry e:list) {
Index index=new Index.Builder(e).index(EsClient.indexName).type(EsClient.typeName).build();
bulk.addAction(index);
}
jestClient.execute(bulk.build());
}
public void insertIndex(SearchResultEntry webpage) throws IOException {
Index index=new Index.Builder(webpage).index(EsClient.indexName).type(EsClient.typeName).build();
jestClient.execute(index);
}
删除数据
public void deleteIndex() throws IOException {
jestClient.execute(new DeleteIndex.Builder(EsClient.indexName).build());
}
根据页数进行全文检索
public List<SearchResultEntry> fullTextSerch(String queryString,int page) {
//声明一个搜索请求体
SearchSourceBuilder searchSourceBuilder=new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder=QueryBuilders.boolQuery();
boolQueryBuilder.must(QueryBuilders.queryStringQuery(queryString));
if(this.isDateRangeQuery) {
QueryBuilder queryBuilder = QueryBuilders
.rangeQuery("time")
.gte(this.startDate)
.lte(this.closingDate)
.includeLower(true)
.includeUpper(true);
/**区间查询*/
boolQueryBuilder=boolQueryBuilder.filter(queryBuilder);
}
searchSourceBuilder.query(boolQueryBuilder);
//设置高亮字段
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.field("text");
highlightBuilder.preTags("<span style="color:red;">").postTags("</span>");
highlightBuilder.fragmentSize(200);
searchSourceBuilder.highlighter(highlightBuilder);
//设置分页
searchSourceBuilder.from((page-1)*10);
searchSourceBuilder.size(10);
//构建Search对象
Search search=new Search.Builder(searchSourceBuilder.toString())
.addIndex(EsClient.indexName)
.addType(EsClient.typeName)
.build();
SearchResult searchResult = null;
try {
searchResult = jestClient.execute(search);
} catch (IOException e) {
e.printStackTrace();
}
resultNum=searchResult.getTotal();
return this.storageList(searchResult);
}
根据日期进行检索
public List<SearchResultEntry> rangeSerch(String queryString,int page,String startDate,String closingDate){
this.isDateRangeQuery=true;
this.startDate=startDate;
this.closingDate=closingDate;
List<SearchResultEntry> list=this.fullTextSerch(queryString,page);
this.isDateRangeQuery=false;
return list;
}
GUI模块
根据页数刷新页面
private void displayResult(){
resultJpanel.removeAll();
resultJpanel.setLayout(new GridLayout(2, 1));
resultJpanel.add(resultList.get(currentPage*2-2));
if(currentPage+currentPage <= resultNum){
resultJpanel.add(resultList.get(currentPage*2-1));
}
resultJpanel.revalidate();
resultJpanel.repaint();
page.setText(currentPage+"/"+pageNum);
}
显示出结果后,点击跳转按钮可以用默认浏览器打开原网页
public void actionPerformed(ActionEvent e) {
if(Desktop.isDesktopSupported()){
try {
URI uri=URI.create(url);
Desktop dp=Desktop.getDesktop();
if(dp.isSupported(Desktop.Action.BROWSE)){
dp.browse(uri);
}
} catch (Exception o) {
o.printStackTrace();
}
}
}
用List保存结果页面
private List<JPanel> getJpanelList(List<SearchResultEntry> list) {
List<JPanel> resultList = new ArrayList<>();
for(SearchResultEntry e:list){
JPanel jPanel=new SearchLook(e);
resultList.add(jPanel);
}
return resultList;
}
项目代码扫描结果及改正
扫描结果

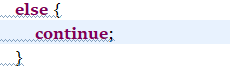
1.对if-else添加完整的大括号,更正前:

更正后:
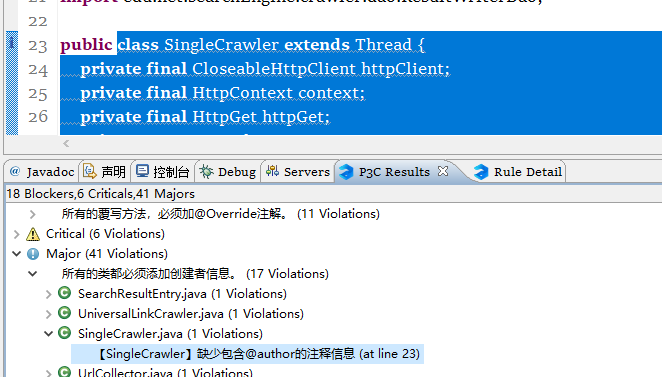
2.没有添加作者,更正前:
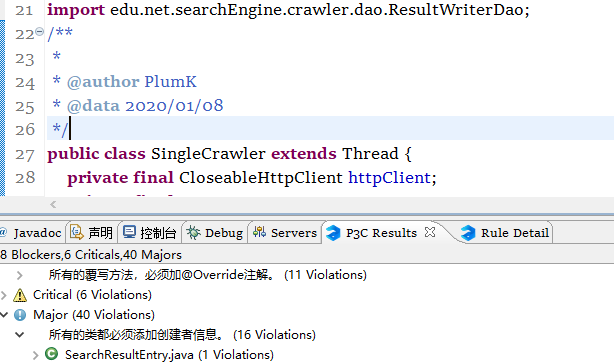
更正后:
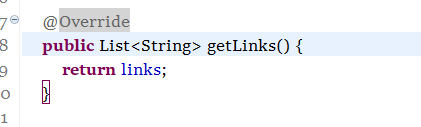
3.覆盖方法没有进行注解,更正前:

更正后:
项目总结
又是一年的课程设计,通过这次课程设计,学到了很多知识,Elasticsearch,JS,GUI,无一不强化了我们的编程技能。可惜的是关键词模糊推荐的功能还不是很好用,没能优化好这个功能。Web页面没有对手机进行适应,GUI也略有不足,希望将来如果有学弟学妹继续这个项目的时候能优化这些缺憾。