1 基础名词解释
1.1 概率: 已知模型和参数,预测出现某个结果的概率。
1.2 统计:已知大量数据,利用数据去预测模型及其参数。
1.3 先验概率: 根据以往经验和分析得到的概率,如抛硬币,我们抛之前,就认为硬币向上概率为0.5.
1.4 后验概率: 事情已发生,判断事情发生由那个原因引起的概率。(由果溯因)
1.5 P(x|θ): x表示一个具体数据,θ表示模型参数;x确定,表示为似然函数;θ确定,表示为概率函数。
1.6 极大似然估计(MLE):已知一组样本数据,假定该数据满足某种模型,依据数据对模型的参数进行估计。
2 过滤网站恶意留言
朴素贝叶斯分类:
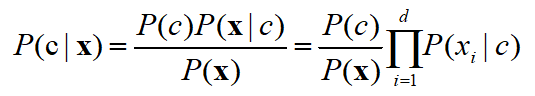
关于该公式的几点说明:
- 该公式用于预测,c为分类的类别,可以有c1、c2、····ci等等若干种,下例中只有两种,即是否侮辱性词汇。
- X为属性向量,即总有d个属性,xi为第i个属性所对应的值。
- P(xi|c)根据训练数据集求出。
- 朴素贝叶斯分类的一个关键点是:属性条件独立性假设,即假设所有属性间相互独立,所有属性独立对分类结果产生影响。
- P(x)不会影响判断结果,故并不需要知道。
例子:关于一个输入文本,判断其是否含有侮辱性言论语言
思路剖一下:
- 需要数据:待测文本,已经带有标签的数据样本(即已标出是否为侮辱性)
- 建立词汇库,将所有出现的词语不重复放入库中,此即属性
- 将每条样本与词汇库比对,即建立属性值矩阵
- 根据样本集求出相关概率值,p1,p2,pc
- 比较待测数据两种情况下的概率,概率大的则为判断结果
代码如下:
1 from numpy import * 2 3 # 创建实验样本 4 def loadDataSet(): 5 postingList=[['my','dog','has','flea','problems','help','please'], 6 ['maybe','not','take','him','to','dog','park','stupid'], 7 ['my','dalmation','is','so','cute','I','love','him'], 8 ['stop','posting','stupid','worthless','garbage'], 9 ['mr','licks','ate','my','steak','how','to','stop','him'], 10 ['quit','buying','worthless','dog','food','stupid']] 11 classVec=[0,1,0,1,0,1] 12 return postingList,classVec 13 14 # 创建一个在所有文档中出现的不重复词的列表 15 def createVocabList(dataSet): 16 vocabSet=set([]) 17 #set()函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等(set之间)。 18 for document in dataSet: 19 vocabSet=vocabSet|set(document) 20 return list(vocabSet) 21 22 # 判断输入文档中词是否在词汇表中出现,输出一个向量表(0或1) 23 def setOfWords2Vec(vocabList,inputSet): 24 returnVec=[0]*len(vocabList) #创建一个与词汇表等长的初始0向量 25 for word in inputSet: 26 if word in vocabList: 27 returnVec[vocabList.index(word)]=1 28 else: 29 print("the word: %s is not in my Vocabulary!"%word) 30 return returnVec 31 32 # 朴素贝叶斯分类器训练函数 33 def trainNB0(trainMatrix,trainCategory): 34 numTrainDocs=len(trainMatrix) #计算训练样本总数,即训练个数 35 numWords=len(trainMatrix[0]) #计算样本种类数,即词汇个数 36 pAbusive=sum(trainCategory)/float(numTrainDocs) #计算是侮辱性样本占比 37 p0Num=ones(numWords) #初始化p0num,p1num为0向量 38 p1Num=ones(numWords) 39 p0Denom=2.0 40 p1Denom=2.0 41 # 从第一个样本到最后一个样本依次检查,如果该样本的标签是1(即为侮辱性), 42 # 则将该样本数据加入p1num中,否则放入p0num中,p1denom表示的是放入p1num的样本1总和 43 for i in range(numTrainDocs): 44 if trainCategory[i]==1: 45 p1Num+=trainMatrix[i] 46 p1Denom+=sum(trainMatrix[i]) 47 else: 48 p0Num+=trainMatrix[i] 49 p0Denom+=sum(trainMatrix[i]) 50 p1Vect=log(p1Num/p1Denom) 51 p0Vect=log(p0Num/p0Denom) 52 return p0Vect,p1Vect,pAbusive 53 54 # 朴素贝叶斯分类函数 55 def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1): 56 p1=sum(vec2Classify*p1Vec)+log(pClass1) 57 p0=sum(vec2Classify*p0Vec)+log(1.0-pClass1) 58 if p1>p0: 59 return 1 60 else: 61 return 0 62 63 def testingNB(): 64 listOPosts,listClasses=loadDataSet() 65 myVolcabList=createVocabList(listOPosts) 66 trainMat=[] 67 for postinDoc in listOPosts: 68 trainMat.append(setOfWords2Vec(myVolcabList,postinDoc)) 69 p0v,p1v,pAb=trainNB0(array(trainMat),array(listClasses)) 70 testEntry=['love','my','dalmation'] 71 thisDoc=array(setOfWords2Vec(myVolcabList,testEntry)) 72 print(testEntry ,'classified as: ',classifyNB(thisDoc,p0v,p1v,pAb)) 73 testEntry=['stupid','garbage'] 74 thisDoc=array(setOfWords2Vec(myVolcabList,testEntry)) 75 print(testEntry,' classified as: ',classifyNB(thisDoc,p0v,p1v,pAb)) 76 77 testingNB()
结果如下:

3 过滤垃圾邮件
内容介绍:
- 两个文件夹各取25个邮件,spam装着垃圾邮件,ham则是有用邮件。
- 以上50个邮件均属带标签,即均可做训练样本,随机抽取其中10个样本作为测试集,即可验证分类精度。
- 运用上例中的诸多函数。
主程序如下:


1 # 将一个大字符串解析为字符列表,并去掉小于两个字符的字符串,转换为小写 2 def textParse(bigString): 3 import re 4 listOfTokens=re.split(r'w*',bigString) 5 return [tok.lower() for tok in listOfTokens if len(tok)>2] 6 7 # 垃圾文件测试 8 def spamTest(): 9 docList=[];classList=[];fullText=[] 10 # 两个文件夹中共50个文件,spam25个垃圾,ham25个有用邮件 11 for i in range(1,26): 12 wordList=textParse(open('email/spam/%d.txt'%i).read()) 13 docList.append(wordList) 14 classList.append(1) 15 wordList=textParse(open('email/ham/%d.txt'%i).read()) 16 docList.append(wordList) 17 fullText.extend(wordList) 18 classList.append(0) 19 vocabList=createVocabList(docList) 20 trainingSet=range(50) #存0-49个整数 21 testSet=[] 22 # 留存交叉验证:随机选出10个样本,将其作为测试集,其余40作训练集,计算错误率 23 for i in range(10): 24 randIndex=int(random.uniform(0,len(trainingSet))) #生成0-50间的随机数 25 testSet.append(trainingSet[randIndex]) 26 del(trainingSet[randIndex]) 27 trainMat=[] 28 trainClasses=[] 29 for docIndex in trainingSet: 30 trainMat.append(setOfWords2Vec(vocabList,docList[docIndex])) 31 trainClasses.append(classList[docIndex]) 32 p0V,p1V,pSpam=trainNB0(array(trainMat),array(trainClasses)) 33 errorCount=0 34 for docIndex in testSet: 35 wordVector=setOfWords2Vec(vocabList,docList[docIndex]) 36 if classifyNB(array(wordVector),p0V,p1V,pSpam)!=classList[docIndex]: 37 errorCount+=1 38 print('the error rate is: ',float(errorCount)/len(testSet))
4 获取区域倾向
内容介绍:
- 使用RSS源作为数据集来源。
- 两个来源即为两个标签。
- 如上例一样可以进行分类,但分类之前需要取出词汇,但一小部分高频词汇是对分类精度有影响的(常用词汇,辅助词汇等)。
- 最后还对两个不同源的高频词汇进行分析。
- 本文中的rss源不可用,可使用其他源。
1 # RSS源分类器及高频词去除函数 2 # 找出排前三十的高频词汇 3 def calcMostFreq(vocabList,fullText): 4 import operator 5 freqDict={} 6 for token in vocabList: 7 freqDict[token]=fullText.count(token) 8 sortedFreq=sorted(freqDict.iteritems(),key=operator.itemgetter(1),reverse=True) 9 # sorted对可迭代的对象进行排序操作,iteritems()使字典变为可迭代对象,operator.itemgetter(1)使数目为比较元素,true降序 10 return sortedFreq[:30]#输出是一个列表n*2,第一列单词,第二列次数 11 12 # 几乎和上例一模一样,访问为rss源,而不是文件,且获得排序最高100的单词并将他们移除 13 def localWords(feed1,feed0): 14 import feedparser 15 docList=[];classList=[];fullText=[] 16 minLen=min(len(feed1['entries']),len(feed0['entries']))#取两个源中项目数量最少的 17 for i in range(minLen): 18 wordList=textParse(feed1['entries'][i]['summary'])# 每篇的摘要 19 # append添加一个整体对象,extend将每个元素逐个添加 20 docList.append(wordList) 21 fullText.extend(wordList) 22 classList.append(1) 23 wordList=textParse(feed0['entries'][i]['summary']) 24 docList.append(wordList) 25 fullText.extend(wordList) 26 classList.append(0) 27 vocabList=createVocabList(docList)# 创建字库 28 # 去除高频词汇三十个(会影响分类错误率) 29 top30Words=calcMostFreq(vocabList,fullText) 30 for pairW in top30Words: 31 if pairW[0] in vocabList: 32 vocabList.remove(pairW[0]) 33 trainingSet=range(2*minLen) 34 testSet=[] 35 for i in range(20): 36 randIndex=int(random.uniform(0,len(trainingSet))) 37 testSet.append(trainingSet[randIndex]) 38 del(trainingSet[randIndex]) 39 trainMat=[] 40 trainClasses=[] 41 for docIndex in trainingSet: 42 trainMat.append(setOfWords2Vec(vocabList,docList[docIndex])) 43 trainClasses.append(classList[docIndex]) 44 p0V,p1V,pSpam=trainNB0(array(trainMat),array(trainClasses)) 45 errorCount=0 46 for docIndex in testSet: 47 wordVector=setOfWords2Vec(vocabList,docList[docIndex]) 48 if classifyNB(array(wordVector),p0V,p1V,pSpam)!=classList[docIndex]: 49 errorCount+=1 50 print('the error rate is: ',float(errorCount)/len(testSet)) 51 return vocabList,p0V,p1V 52 53 # 显示最具表征性的词汇 54 def getTopWords(feed0,feed1): 55 import operator 56 vocabList,p0V,p1V=localWords(feed1,feed0) 57 topfeed1=[] 58 topfeed0=[] 59 for i in range(len(p0V)): 60 if p0V[i]>-6.0: 61 topfeed0.append((volcabList[i],p0V[i])) 62 if p1V[i]>-6.0: 63 topfeed1.append((volcabList[i],p0V[i])) 64 sortedFeed0=sorted(topfeed0,key=lambda pair:pair[1],reverse=True) 65 for item in sortedFeed0: 66 print(item[0]) 67 sortedFeed1=sorted(topfeed1,key=lambda pair:pair[1],reverse=True) 68 for item in sortedFeed1: 69 print(item[0])
5 总结
后两例是对第一例的扩展理解,理解第一例即可对朴素贝叶斯分类的原理有很好的认识。主要参考书为周志华《机器学习》以及peter《python机器学习实战》。