心路历程
刚看到题目的时候,我第一反应是。。。这数独游戏是啥玩意= =。然后看了下题目介绍,这时候才第一次了解它。我一开始想说用dfs来解决,这个数独游戏的生成我想跟8皇后问题是类似的。但是仔细再看了看题目要求,然后我去玩了几盘这游戏,我又想了想,或许我也可以使用比较投机取巧的方法(Z班的一个同学告诉我他们跟K班的作业要求更新以后,测试数据在1-1000000)。我想,这作业的评分标准应该是一样的,所以这时脑子完全被“投机取巧”的想法占据了,1000000的话并不需要老老实实的去做递归回溯(在这边我通过百度发现大部分都使用着dfs来解决这问题),我想对于解决一个问题的方法的好坏,应当是针对该问题的方法各方面恰到好处。我觉得用dfs的话在时间复杂度上会比我投机取巧的方法大,对于1000000的数据有点大材小用了吧= =。下面介绍我那投机取巧的方法。(其实后来做性能测试时我发现算法的时间复杂度跟文件输出的时间比起来,根本不值一提的,不过投机取巧还是比较快)
解题思路
- 进行理论推导
- 我首先猜测,如果我已经构建出了一个数独 A1 后,那么,对于 A1 的每行每列每个小九宫格的数字都会遵照数独的性质,所以如果我调换某两个不同数字时,这个方式可以产生一个新的数独 A2 。同时地,对于每3行(或3列),如果我以3行(列)为单位的调换的话,我一样可以得到一个新的数独 A3 ,与此同时,对于每3行(列)里的每一小行,我一样可以通过交换的方式,又得到一个新的数独 A3 。下面用图片展示这个过程:
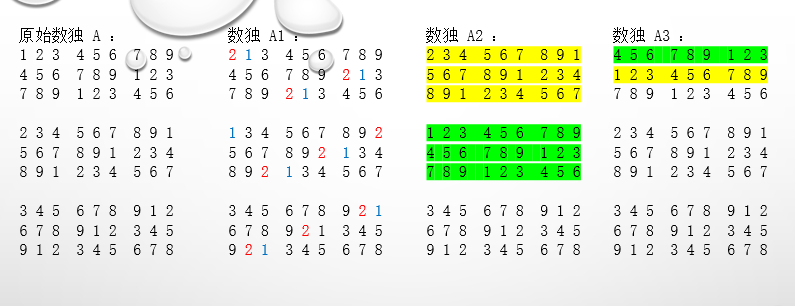
- 观察 A ,这个数独存在着很强的规律性

将第一行的 9 个数作为“源”,那么第二行则是在第一行的基础上左移3个单位,第三行则是在第二行的基础上左移3个单位;第四行是第一行左移1个单位,第五行是第二行左移1个单位,第六行是第三行左移1个单位;第七行是第四行左移1个单位。。。。。。。
也就是说,只要第一行确定了,那么后面的行是可以通过移动来生成数独的。并且,只要第一行的序列不同,生成的数独也将不同。
第2、3行的生成代码:map[i][j] = map[i][j] = map[i - 1][(N + j + n) % N]; (N = 9, n = 3)
第4 - 9行的生成代码:map[i][j] = map[i - n][(j + 1) % N]; - 回到我说猜测的那部分,我首先提到的方法是调换两个不同的数字,也就是对第一行的2个不同的数字进行调换,但是调换 != 排列组合,需要得到用这方法的最大数量的数独,那便是对第一行进行全排列(这边出了点小纠结。。。因为K、Z要求第一个数固定,,后来我顺便就固定了吧)。那么扣除第一个数,对于第一行而言,可以得到 8! 个不同的排列组合。也就是目前得到了 8! 个不同的数独。(8! < 1000000,远远不够,所以继续深入)这里推荐一个C++函数:next_permutation
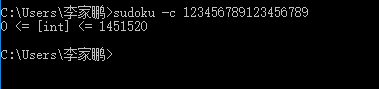
- 考虑到会重复的问题,因此在使用行(列)交换时,只使用 A3 的方法(也不要把行交换和列交换同时使用)。第一行已经固定了,因此目前能参与交换的只有2 - 9行,这边只使用4 - 6, 7 - 9进行 A3 方法行交换。同样的这边实际上是对4 - 6进行行排列,7 - 9进行行排列。则4 - 6,7 - 9各有6种不同的排列组合。也就是说对于4 - 9,可以得到6 * 6 = 36种不同的组合。那么对于一个数独而言,这36种是不同的,则对于 8! 个不同的数独,便得到了 8! * 36 = 1451520 > 1000000
- 我首先猜测,如果我已经构建出了一个数独 A1 后,那么,对于 A1 的每行每列每个小九宫格的数字都会遵照数独的性质,所以如果我调换某两个不同数字时,这个方式可以产生一个新的数独 A2 。同时地,对于每3行(或3列),如果我以3行(列)为单位的调换的话,我一样可以得到一个新的数独 A3 ,与此同时,对于每3行(列)里的每一小行,我一样可以通过交换的方式,又得到一个新的数独 A3 。下面用图片展示这个过程:
设计实现
- 推理结束,接下来进行程序设计。。因为这里我一开始真没想过运行时间几乎全在输出上(1000000的数据,平均花费时间在16秒,然后扣除输出时间,剩余的在0.5秒以内。。。),所以我就尽量的让它能直接输出的就不再去存放在数组里面,然后再输出这个9 * 9的数组了。还是以图片展示各个函数。

代码
void Generator::sudoku() // 最大值 8! * 36 = 1451520
{
if (num != 0)
{
int list[N] = { 7, 1, 2, 3, 4, 5, 6, 8, 9 }; // 第一行的初始值
memcpy(map[0], list, N * sizeof(int));
do
{
map_generate();
if (num <= 1000) // 在 n <= 1000 时选择此方法
{
print();
}
else
{
row_exchange(); // 进行行排列
}
} while (next_permutation(map[0] + 1, map[0] + N)); // 对第一行除了第一个数以外,其他数的全排列, 8!
}
}
void Generator::map_generate() // 生成 2-9 行
{
int i, j;
for (i = 1; i < N; ++i)
{
for (j = 0; j < N; ++j)
{
if (i < n) // 第 2、3 行为上一行的元素左移 3 个单位
{
map[i][j] = map[i - 1][(N + j + n) % N];
}
else // 第 4-9 行为上一个大行中(3行为一大行)左移 1 个单位
{
map[i][j] = map[i - n][(j + 1) % N];
}
}
}
}
void Generator::row_exchange() // 大行排列,可产生 36 种变形
{
int i, j;
// order 说明:表示 4-6 行的所有排列组合次序
int order[6][3] = { { 4, 5, 6 },
{ 4, 6, 5 },
{ 5, 4, 6 },
{ 5, 6, 4 },
{ 6, 4, 5 },
{ 6, 5, 4 } };
for (i = 0; i < 6; ++i)
{
for (j = 0; j < 6; ++j)
{
if (num-- > 0)
{
row_print(order[0], -3); // 1 - 3
row_print(order[i], 0); // 4 - 6
row_print(order[j], 3); // 7 - 9
if (num != 0)
{
putchar('
');
}
}
else
{
exit(0);
}
}
}
}
几点说明:要查看完整代码请访问Github,第一行初始值是根据K、Z的要求来的。。。
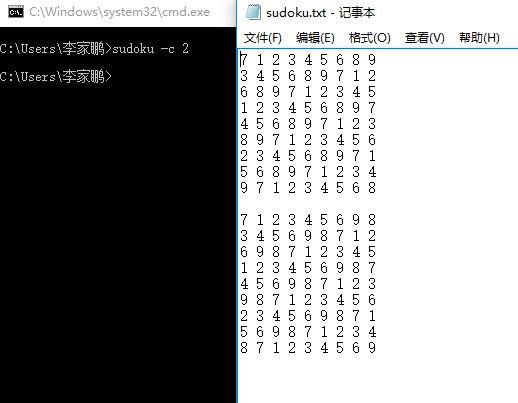
测试运行


性能分析
这边在输出方面采用了字符输出进行优化(putchar()),emmn。。。提速非常明显。这里展示优化以后的当N = 1000000 时的性能分析图
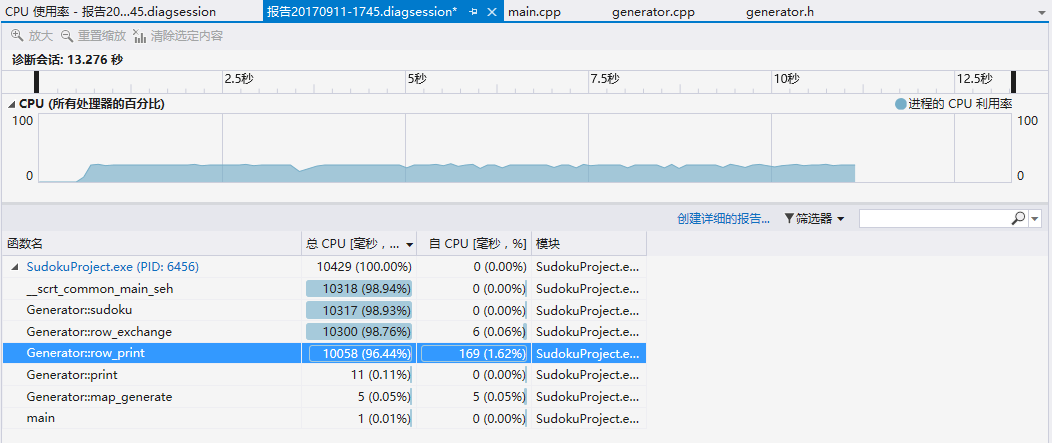
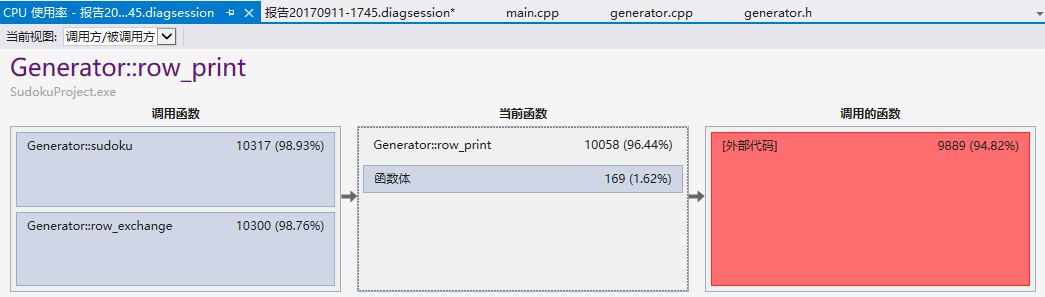
可以发现时间几乎花在在输出上(row_print & print),现在想不出在好点的方法了。因为对于1000000的数据是需要进行大量行排列的,所以row_print所占用时间自然比print多。
总结与PSP
-
总结
- 在确定方法写代码的之后,由于放假在家的话我都只有晚上才用电脑,还有时玩游戏,外加遇上停电一天,突然想起思政报告没写- -,还拖拉了几天,然后就各种拖延了进度,浪费了大量的时间然后所以进度就没法太快。下次还是要控制下自己= =,对于附加题的话,在这博客写完后我打算抓紧时间做,尽量在13号截止前做完,如果没有的话,那也还是继续做下去吧。以后还是,,,给自己先定个小计划,不去一直拖着。另外感谢助教对我那各种无厘头的问题的解释hh,,,emmn,,,,在群里匿名帮人的感觉也挺有趣- -。
-
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 60 |
| Development | 开发 | 390 | 400 |
| · Analysis | · 需求分析 (包括学习新技术) | 40 | 50 |
| · Design Spec | · 生成设计文档 | 40 | 60 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 50 | 60 |
| · Design | · 具体设计 | 60 | 70 |
| · Coding | · 具体编码 | 60 | 50 |
| · Code Review | · 代码复审 | 30 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 80 | 60 |
| Reporting | 报告 | 80 | 60 |
| · Test Report | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 30 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 500 | 520 |
附加题
- 在前面的基础上,增加了对数独的挖空和检测数独的唯一性。比较遗憾的是,对于数独唯一性的检测现在我还没能很好的实现代码,有一点BUG,,还在找。等找到了(或者重新想个方法)再修改git上面的代码。待我周末的第一次补考后再继续了= =(以后考试不要浪。。。)
- 简单介绍下检测唯一解的思路:
- 首先对一个数独进行挖空,使用随机选择挖哪个。对此,我有一个假设:如果说我每一挖一次后,检测到这个空挖完以后产生的是唯一解,然后下一次我在挖另外一个空,假设该位置数字为 A ,如果这个空也能具有唯一解的话,则除了 A 以外,先检查这个 A 所在的小九宫格所缺少的数字 Ni (事实上我每次确定可挖以后,便把这个A保存进入 Ni (i为所在小九宫格的序号),这样明显我就不需要每次都检测一次),如果 存在唯一解,那么也就满足 Ni 不可以填充在 A 的位置。
- 对于检测是否满足,采用方式是检测该位置的行与列是否存在重复,而对于处在该行(列)的空,重复上诉方法。也就是使用递归回溯法。
- 发现有几个问题,因为是随机挖空,不能保证我可以挖到我预先设定的 cnt 个空格,这里 cnt 满足 cnt_max<64(参考),当然。还要符合题目要求
- 附上几个界面截图