一、GitHub传送门
二、结对成员
- 陈甘霖(031502604)
- 李家鹏(031502615)
三、问题描述
-
提供输入包括:
-
20个部门
- 部门编号(唯一值)
- 各部门需要学生数的要求的上限(单个,数值,在[0,15]内);
- 部门的特点标签(多个,字符);
- 各部门的常规活动时间段(多个,字符/日期);
-
300个学生
- 学号(唯一值);
- 学生绩点信息(单个,数值);
- 学生部门意愿(部门意愿不多于5个且不能空缺);
- 学生空闲时间段(多个,字符/日期);
-
-
实现一个智能自动分配算法,根据输入信息,输出部门和学生间的匹配信息(一个学生可以确认多个他所申请的部门,一个部门可以分配少于等于其要求的学生数的学生) 及 未被分配到学生的部门 和 未被部门选中的学生。
-
“数据生成"程序的原理以及所考虑的因素
- 最“好”的数据(学生300 部门20)
- 考虑的因素——部门
- 部门名称统一命名:采取D+xxx方式(D012)
- 人数限制:从[10,15]中随机随机取一个数
- 部门活动时间设定
- 数量为每周[2,4]个,每次时间为2小时,一天至多有一次活动
- 时间段选择:每天起始时间为8-10,14-16,19-21 时
- 部门标签:一个部门不应该有太多标签,因此设定[2,3]个
- 考虑的因素——学生
- 学生学号统一命名:采取福大学号编制方式
- 学生绩点
- 对于老生而言,绩点为[1,5]
- 对于新生,采取高考标准分方式 这里也是为了新生对加入比老生具有优先权
- 学生空闲时间设定
- 一周的每一天的每个时段(早上、中午、下午)学生都可能有空
- 扣除休息时间,每天起始时间为8-10,14-16,19-21 时,每次时长2小时
- 学生兴趣:一个学生可以有[2,4]个兴趣爱好
- 学生意愿部门:对于学生意愿部门而言,不可以出现多个意愿部门的活动时间发生冲突的情形
- 程序原理
- 先设定兴趣、时间数组
string hobbies[15] = { "dancing", "singsing", "playing football", "playing basketball",
"playing table tennis", "playing the violin", "playing computer",
"playing the piano", "drawing", "reading books", "speaking English",
"writing the code", "playing cards", "play badminton", "swimming" };
string date[7] = { "Mon.", "Tues.", "Wed.", "Thur.", "Fri.", "Sat.", "Sun." };
string hour[15] = { "08:00", "09:00", "10:00", "11:00", "12:00", "14:00","15:00", "16:00",
"17:00", "18:00", "19:00", "20:00", "21:00", "22:00", "23:00"};
-
-
- 对于兴趣或标签而言,采取随机取出n个的兴趣
- 对于时间设定,采取以下方式

-
四、团队分工
- 陈甘霖:json的输入与输出,协助完成匹配程序生成
- 李家鹏:负责数据生成、匹配程序
五、心路历程
- 看到作业纠结了老半天要使用JSON还是数据库还是普通的文本文件,,,不过嘛后来跟那2604(听说他在吐槽我)大腿商量一下,想想还是用JSON。一是JSON的数据结构明显,另外按百度说的(虽然不太相信百度)JSON数据在传输上比较轻巧。然后这关于JSON的输入输出的问题就扔给2604了。之后在选择编程语言上,最后选择C++(别信2604说我威胁他,一开始拒绝JAVA的还是他emmm。。。)
- 说实话DEBUG是个非常痛苦的过程,在输出结果的时候,意外发现这string用json输出的字符串好像非常不友好,竟然用queue弹出的string会出现字符串的前缀为空串标识,搞到最后我还是只能去修改部分queue数据类型成vector。
- 关于更多痛苦的debug过程请看后文。。
五、算法分析
-
关于rapidjson(以下是官方架构截图)


-
关于匹配
-
匹配原则:
- 首先保证志愿优先原则,则分5轮进行,在此条件下新生优先,之后未选中任何一个部门的学生优先。
- 另外设定的优先级具有7种。二进制数字位数上为1表示此处具有优先。3个位分别对应为绩点、兴趣、时间,并且可以混合匹配原则
- 并且可以单独为每个部门设置各自的匹配原则
- 在选中相同部门并相同的优先级下的两个学生,采取随机选择学生方式
-
流程图
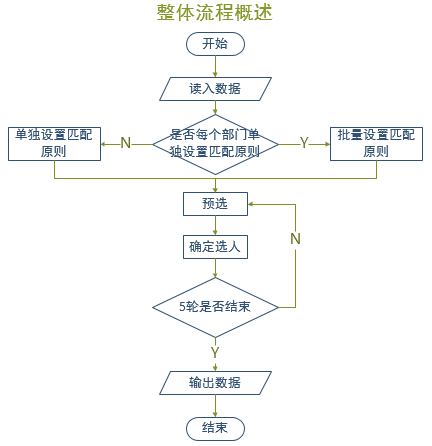
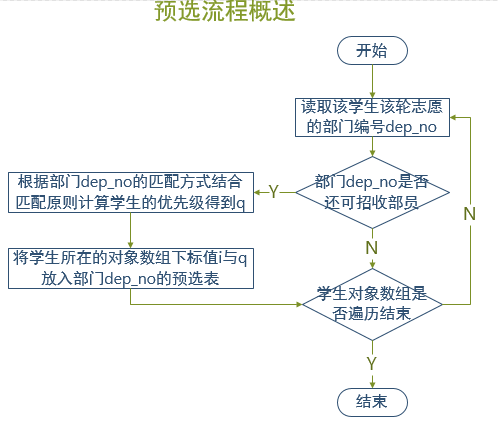

-
实现代码
-
// 函数:预选部员
void Match::select(Student *s, Department *d, int stu_num, int dep_num)
{
int i, j;
vector <int> v;
for (i = 0; i < stu_num; ++i)
{
if (!s[i].dep.empty()) // 如果该学生还有意愿部门
{
v.clear();
v.push_back(i); // 放入学生的所在对象数组的下标
j = s[i].dep.front(); // 得到这个学生志愿的部门编号
if (d[j].limit != 0) // 如果该部门还可招收学生
{
v.push_back(Match::priority(s + i, d + j)); // 得到优先级数值
d[j].stu.push_back(v); // 放入对应部门的部员预选表
}
s[i].dep.pop();
}
}
}
// 函数:返回优先等级
int Match::priority(vector <string> &v1, vector <string> &v2)
{
int p_num = 0;
unsigned int i, j;
for (i = 0; i < v1.size(); ++i) // 对v1、v2中的值进行匹配操作
{
for (j = 0; j < v2.size(); ++j)
{
if (v1.at(i) == v2.at(j))
{
p_num++;
}
}
}
return p_num;
}
// 函数:学生选部门时的优先级设定 数值越小越优先
int Match::priority(Student *s, Department *d)
{
int p_num = 0, flag = d->priority;
if (flag & 1) // 绩点优先
{
p_num += int(-s->score * 1000) - s->state * 1000; // 优先还未选中部门的学生
}
if (flag & 2) // 兴趣优先
{
p_num += Match::priority(s->tags, d->tags);
}
if (flag & 4) // 时间优先
{
p_num += Match::priority(s->free, d->schedules);
}
return p_num + s->state * 1000; // 优先还未选中部门的学生
}
// 函数:sort重新定义排序方式
bool cmp(const vector <int> &a, const vector <int> &b)
{
return a.at(1) < b.at(1);
}
// 函数:添加部员
void Match::depADDstu(Student *s, Department *d, int dep_num)
{
int i;
unsigned int j;
for (i = 0; i < dep_num; ++i)
{
if (d[i].limit != 0) // 如果该部门还可招收学生
{
sort(d[i].stu.begin(), d[i].stu.end(), cmp);
for (j = 0; d[i].limit != 0 && j < d[i].stu.size(); ++j)
{
d[i].stu_no.push_back(s[d[i].stu.at(j)[0]].no); // 将学生编号放入对应部门的部员表
s[d[i].stu.at(j)[0]].dep_no.push(d[i].no); // 将部门编号放入对应学生的部门表
s[d[i].stu.at(j)[0]].state++; // 学生所加入的 部门数 +1
d[i].limit--; // 部门的 人数限制 -1
}
d[i].stu.clear(); // 清空该部门的部员预选表
}
}
}
六、代码规范
这次结对作业双方对编码做了些规范:
每个独立功能使用一个函数
类名首字母发泄
函数名使用小写
变量名大小写混搭,尽可能表达清楚变量的意义
代码使用注释,应该说使用大量的注释,这个非常重要,既为了自己Debug方便,也为了搭档阅读方便


七、算法测试报告与结果分析评价
| 输入 | 优先条件 | 匹配学生个数 | 未匹配学生个数 | 实际耗时 | 输出文件路径 |
|---|---|---|---|---|---|
| 1 | 绩点 | 243 | 57 | 0.449 | output_condition1.txt |
| 2 | 兴趣 | 255 | 45 | 0.481 | output_condition2.txt |
| 3 | 绩点+兴趣 | 242 | 58 | 0.503 | output_condition3.txt |
| 4 | 时间 | 257 | 43 | 0.486 | output_condition4.txt |
| 5 | 绩点+时间 | 243 | 57 | 0.595 | output_condition5.txt |
| 6 | 兴趣+时间 | 250 | 50 | 0.573 | output_condition6.txt |
| 7 | 绩点+兴趣+时间 | 243 | 57 | 0.623 | output_condition7.txt |
| 2 | 兴趣 | 1272 | 1728 | 0.912 | output_condition8.txt |
| 2 | 兴趣 | 3776 | 1224 | 1.096 | output_condition9.txt |
- 结果分析
- 对于前7组数据,都是学生300 部门20的情况。从结果上看,选中部门的人数均在250左右,符合人数区间[200,300]的中间值,而部门全部招满人,这符合事先的设定
- 对于第8组数据,学生3000,部门100,选中部门的人数符合人数区间[1000,1500]的中间值
- 对于第9组数据,学生5000,部门300,选中部门的人数符合人数区间[3000,4500]的中间值
- 测试结果均符合最初构想,即首先在人数足够的情况下部门都会满员,此时 选中的人数/最大容纳人数=0.8
八、关于欢快的DEBUG
- 一开始为了观察一些有趣的数据,在类的析构函数里头加了几句代码,于是乎就获得了意外收获。本来我函数为了简单都采取传值的方式,一时马虎在函数中修改对象成员使用传值类对象,然后,,运行时满屏的都是我析构函数的输出,算是瞎猫碰上死耗子,之后果断的将所有传参方式改成传址,也还顺便节省时间。
- 虽然说接下来这是个warning,不过感觉也非常有趣。对于一个vector ,使用for(i = 0; i < vector.size(); ++i);遍历时,竟然因为这出现'<'标识符警告(当然还有一堆其他类似问题)。。重新看了,才发现应该是unsigned int 。如果要是我int i = vector.size();那怕是又要炸了。
- rapidJson对queue真的是非常不友好,跟2604想了半天为啥输出了空字符串(一开始没想到说是queue的原因),试了各种方法,后来还是写了个小代码,才发现如果json输出queue弹出的string就会出现前缀为空串的情况。没法,最后还是只能把queue换掉,还好功能细分后各模块函数独立,所以也很快。
- 说个有意思点的。。在函数内部别别别去动态开辟一个你在外部声明的指针= =。感觉这时候犯这错误太糟糕了。用汇编来说就是在外部声明的栈地址为a,调用函数后,栈地址为b,然后开辟c,d,e....,结果函数返回时,esp回到a位置(讲错的话来纠正下),然后你在函数里面开辟的动态数组、赋值操作就都白做了。。出现这问题是在读取文件时,因为这边要开辟Student、Department的对象数组,然后关于“多大”的问题只能在读取文件时才知道,又为了把读文件操作独立出来,所以这问题就随之而来了。最后的这个问题的解决方法是在函数外部声明document,然后读取函数将json转换出来的document返回,此时也已知道数组大小,于是开辟空间,然后再新的函数中赋值。相当于把读取跟赋值分成两件事。具体可以看github代码。
九、结对感受
- 全程抱紧2604,最后让给他舍友
- 找个大腿做队友还是很必要的,,emmm。。。json的输入与输出基本上都是他在弄(虽然等了8天emmm。。。)
- 事先好像我们没沟通好他写的json的输入输出怎么弄进来匹配程序中,就是对象成员赋值或输出问题没想好。然后嘛我写了4个函数,想说他的输入输出得到参数按函数要求传递就行(好像说得很不清楚这意思),他也写了2个函数想说让我去用就行。。于是乎我写的他对应不了,他写的我对应不了= =。最后是直接在他的输入输出函数中直接对对象成员操作,代码嘛显得非常冗长。
- 闪光点
- 考虑到或许在实际中,部门可能会提出一个新的匹配(比如擅长的技术等等),所以采取二进制的某位上的1表示某一个优先级是否激活。
- 我觉得为程序的输入输出数据进行检测并设置错误提醒还是很有必要的,,,结果大概如下。可自行去运行下(命令行运行)

