利用Python中的requests库爬取视频的图片
一、总结
一句话总结:
可以用requests的get方法获取图片响应数据,因为是二进制,所以用response的content属性获取图片二进制数据,然后用python文件操作把图片存下来就可以了
import requests headers = { "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36", } url ="https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1594286367651&di=7f176da3578634bc67e5f38e24438b0c&imgtype=0&src=http%3A%2F%2Fbpic.588ku.com%2Felement_origin_min_pic%2F16%2F07%2F10%2F205782447d16b2a.jpg%2521%2Ffwfh%2F804x804%2Fquality%2F90%2Funsharp%2Ftrue%2Fcompress%2Ftrue" response = requests.get(url,headers=headers) print(response.status_code) # print(response.text) # print(response.content) with open("test.jpg","wb") as f: f.write(response.content)
二、利用Python中的requests库爬取视频的图片
转自或参考:爬虫--利用Python中的requests库爬取一个视频、图片
https://blog.csdn.net/yong_zi/article/details/82079680
爬取图片还是比较简单的,这里说一下:
首先获取图片的url链接。
在百度上搜索图片,如下:
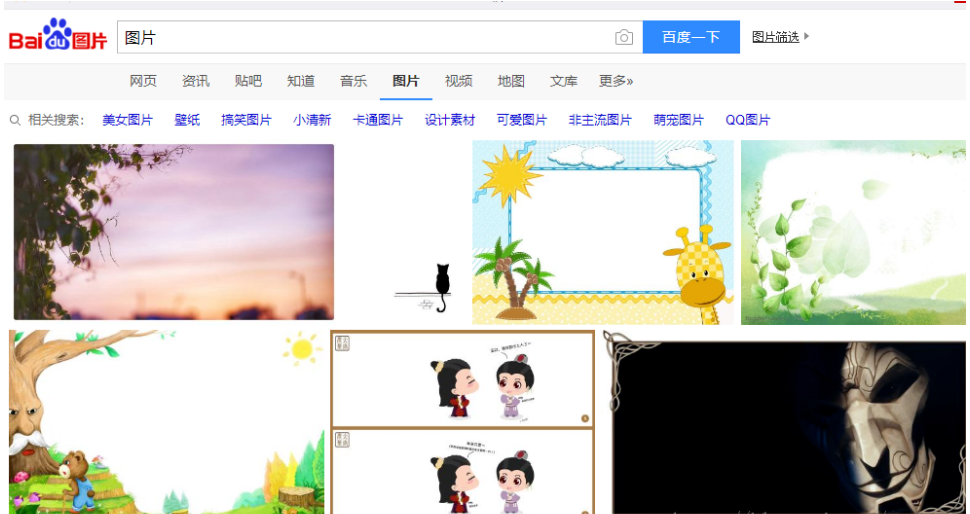
随便点击一个,然后右键->复制图片地址
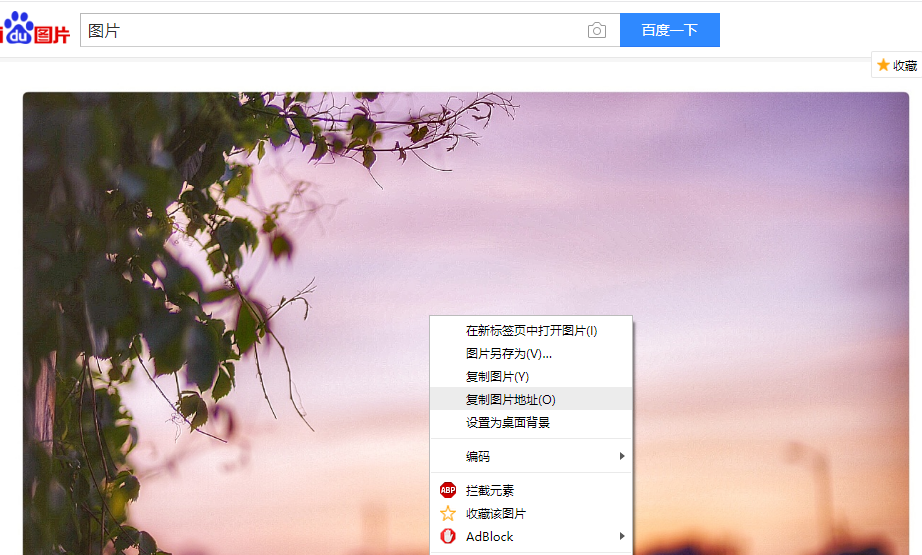
好了我们就获取到了,该图片的url链接了,为了验证我们得到的链接是否正确,可以在浏览器里输入这个地址来验证。
程序最后展示,下面在说下爬取视频的方法,爬取视频其实跟爬取图片的步骤其实是一样的。
以http://www.pearvideo.com/category_9这个网站为例,像图片一样随便点开个视频,然后右键查看网页源代码,搜索mp4,得到视频的url。
好了开始爬取吧,程序如下:
import requests
import os
#url = "https://wx3.sinaimg.cn/mw690/0064wDqKgy1fulqkev62bj30b40gowg4.jpg"
url="http://video.pearvideo.com/mp4/adshort/20180825/cont-1420328-12741912_adpkg-ad_hd.mp4"
root = "D://pics//"
path = root+url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
r.raise_for_status()
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件保存成功")
except:
print("爬取失败")
程序还是比较容易理解的,这里就不多说了。