卷积实例
一、总结
一句话总结:
卷积连续定义:$$( f * g ) ( n ) = int _ { - infty } ^ { infty } f ( au ) g ( n - au ) d au$$
卷积离散定义:$$( f * g ) ( n ) = sum _ { au = - infty } ^ { infty } f ( au ) g ( n - au )$$
1、反向传播形象例子?
A、几个人站成一排第一个人看一幅画(输入数据),描述给第二个人(隐层)……依此类推,到最后一个人(输出)的时候,画出来的画肯定不能看了(误差较大)。
B、反向传播就是,把画拿给最后一个人看(求取误差),然后最后一个人就会告诉前面的人下次描述时需要注意哪里(权值修正)
2、卷积是一种运算理解?
加减乘除是运算,卷积也是一种运算,f和g对应位置相乘再相加
3、AdamOptimizer?
①、Adam 这个名字来源于adaptive moment estimation,自适应矩估计,
②、如果一个随机变量 X 服从某个分布,X 的一阶矩是 E(X),也就是样本平均值,X 的二阶矩就是 E(X^2),也就是样本平方的平均值。
③、Adam 算法根据损失函数对每个参数的梯度的一阶矩估计和二阶矩估计动态调整针对于每个参数的学习速率。
二、内容在总结中
转自或参考:15-TensorFlow高级
https://www.jianshu.com/p/a58981a27334
一.反向传播
几个人站成一排第一个人看一幅画(输入数据),描述给第二个人(隐层)……依此类推,到最后一个人(输出)的时候,画出来的画肯定不能看了(误差较大)。
反向传播就是,把画拿给最后一个人看(求取误差),然后最后一个人就会告诉前面的人下次描述时需要注意哪里(权值修正)
二.什么是卷积:convolution
已有运算:加减乘除,幂运算指数运算
卷积:卷积是一种运算
卷积运算: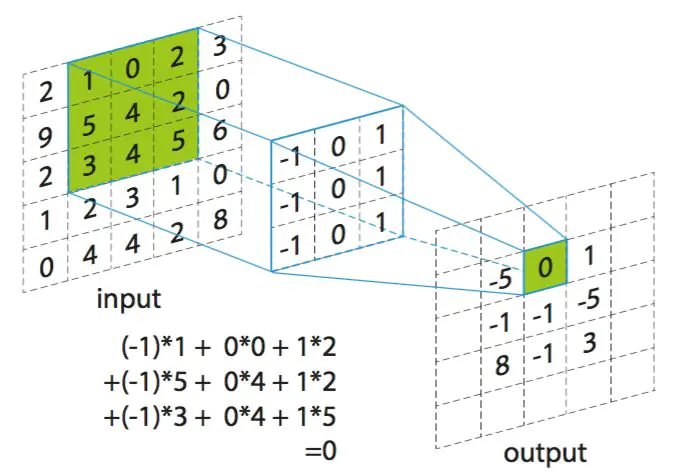 卷积运算.png
卷积运算.png
卷积操作是使用一个二维的卷积核在一个批处理的图片上进行不断扫描。具体操作是将一个卷积核在每张图片上按照一个合适的尺寸在每个通道上面进行扫描
卷积的过程:如下图所示,用一个33的卷积核在55的图像上做卷积的过程,动图展示效果:
卷积过程.gif
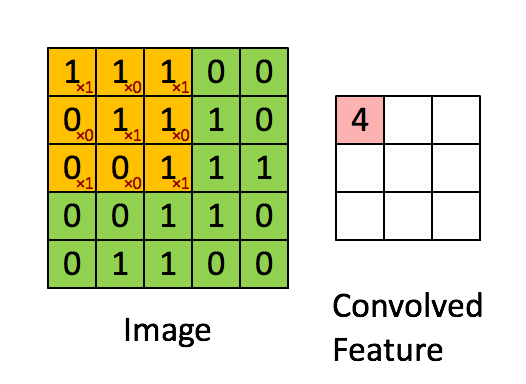
在三通道图像上的卷积过程,动图展示效果如下:
三通道图像上的卷积过程.gif
计算步骤如下:
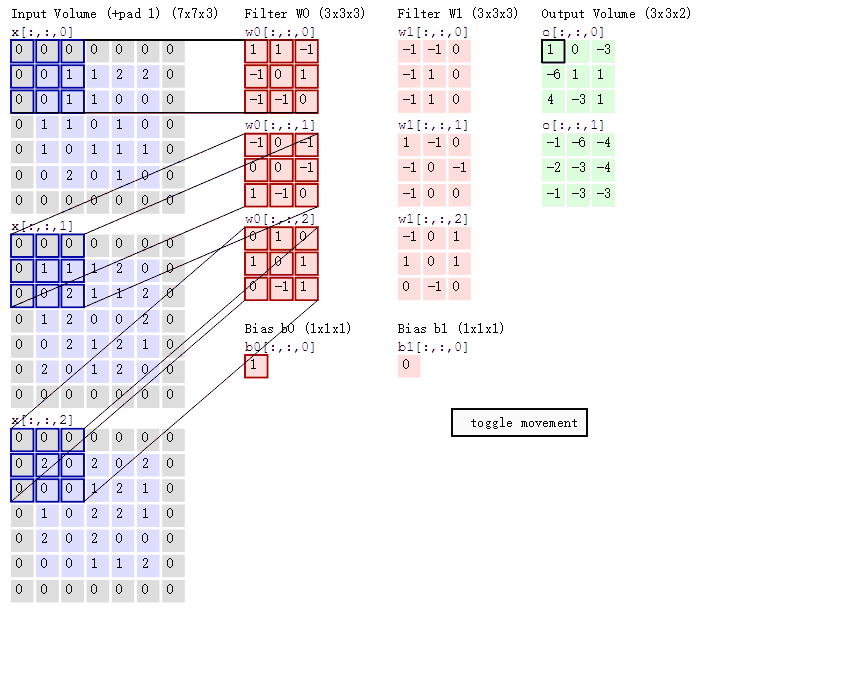
计算步骤解释如下,原图大小为77,通道数为3:,卷积核大小为33,Input Volume中的蓝色方框和Filter W0中红色方框的对应位置元素相乘再求和得到res(即,下图中的步骤1.res的计算),再把res和Bias b0进行相加(即,下图中的步骤2),得到最终的Output Volume
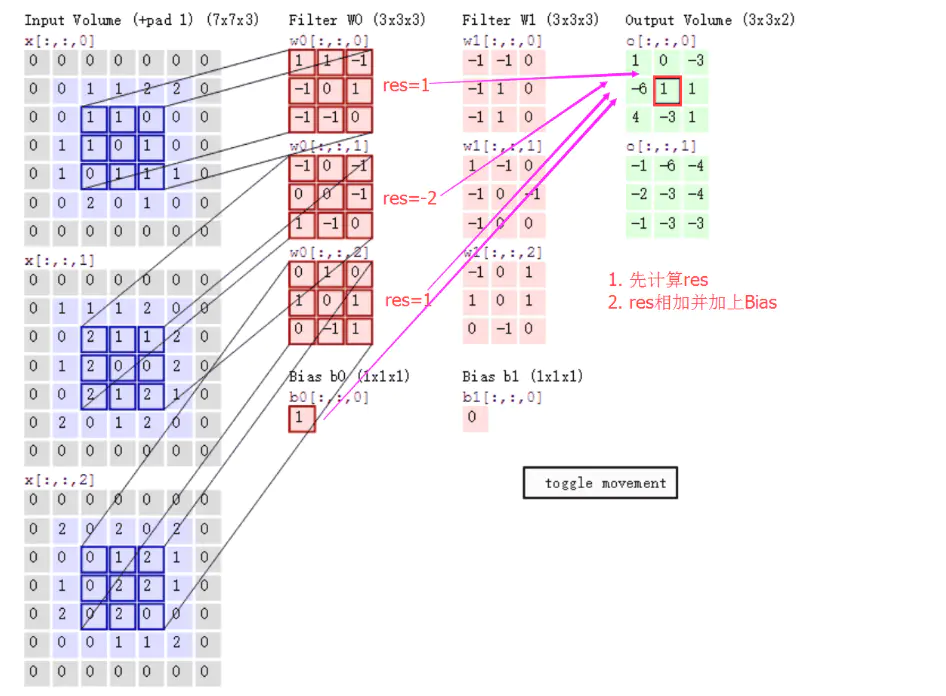 卷积计算图.png
卷积计算图.png
卷积函数如下:卷积函数tf.nn.conv2d
- 第一个参数:input
input就是需要做卷积的图像(这里要求用Tensor来表示输入图像,并且Tensor(一个4维的Tensor,要求类型为float32)的shape为[batch, in_height, in_width, in_channels]具体含义[训练时一个batch图像的数量,图像高度,图像宽度, 图像通道数])第二个参数:filter
filter就是卷积核(这里要求用Tensor来表示卷积核,并且Tensor(一个4维的Tensor,要求类型与input相同)的shape为[filter_height, filter_width, in_channels, out_channels]具体含义[卷积核高度,卷积核宽度,图像通道数,卷积核个数],这里的图片通道数也就input中的图像通道数,二者相同。)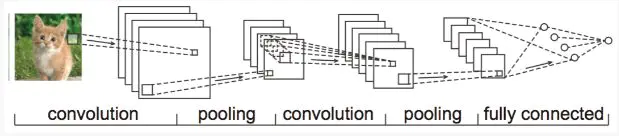
图1.png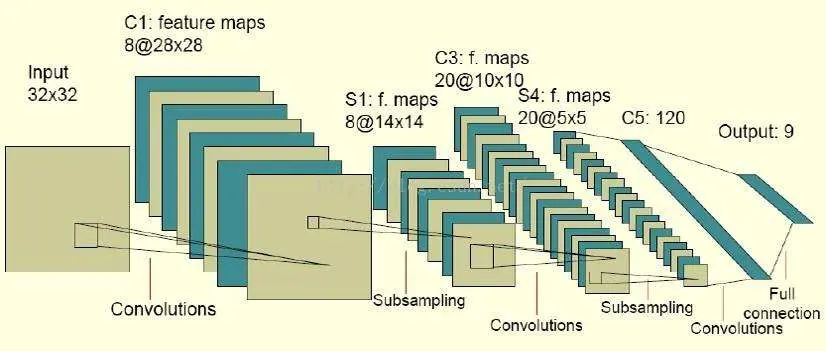
图2.png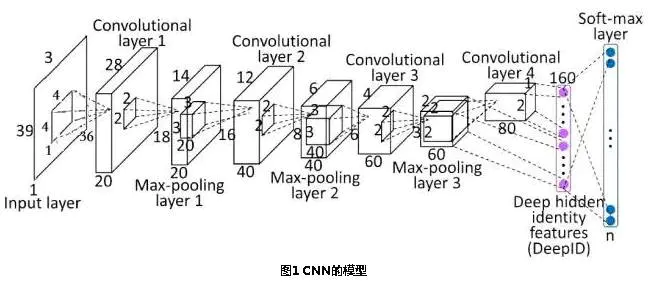
图3.png- 第三个参数:strides
strides就是卷积操作时在图像每一维的步长,strides是一个长度为4的一维向量- 第四个参数:padding
padding是一个string类型的变量,只能是 "SAME" 或者 "VALID",决定了两种不同的卷积方式。下面我们来介绍 "SAME" 和 "VALID" 的卷积方式,如下图我们使用单通道的图像,图像大小为55,卷积核用33- 第五个参数:use_cudnn_on_gpu
- 第六个参数:data_format
data_format: An optionalstringfrom:"NHWC", "NCHW". Defaults to"NHWC".
Specify the data format of the input and output data. With the
default format "NHWC", the data is stored in the order of:
[batch, height, width, channels].
Alternatively, the format could be "NCHW", the data storage order of:
[batch, channels, height, width]
data_format就是input的Tensor格式,一般默认就可以了。都采用NHWC- 第七个参数:name
<span style="font-size:18px;">name: A name for the operation (optional).</span>
就是用以指定该操作的name,仅此而已
三.使用convolution处理图片
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
pic = plt.imread('./欧式.jpg')
pic2 = pic.reshape([1, 582, 1024, 3]).transpose([3,1,2,0])
# 平滑均值滤波
# filter_arg = np.full(shape=[3, 3, 1, 1], fill_value=1 / 9)
# # 高斯平滑滤波
filter_arg = np.array([[1/16,2/16,1/16],[2/16,4/16,2/16],[1/16,2/16,1/16]]).reshape([3,3,1,1])
pic3 = tf.constant(pic2, dtype=tf.float32)
filter_arg = tf.constant(filter_arg, dtype=tf.float32)
# 卷积
pic_cnn = tf.nn.conv2d(pic3, filter=filter_arg, strides=[1, 1, 1, 1], padding='SAME')
plt.imshow(pic)
plt.show()
with tf.Session() as sess:
pic4 = sess.run(pic_cnn)
print(pic4.shape)
plt.imshow(pic4.transpose([3,1,2,0]).reshape([582,1024,3]).astype(np.uint8)/255)
# 图片灰度化处理
plt.imshow(pic4.transpose([3,1,2,0]).reshape((582,1024,3)).mean(axis = -1).astype(np.uint8)/255,cmap = 'gray')
plt.show()
-
平滑均值滤波
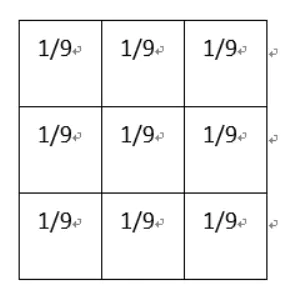 平滑均值滤波.png
平滑均值滤波.png
该卷积核的作用在于取九个值的平均值代替中间像素值,所以起到的平滑的效果

均值滤波原图.png
均值滤波卷积图.png
-
高斯平滑
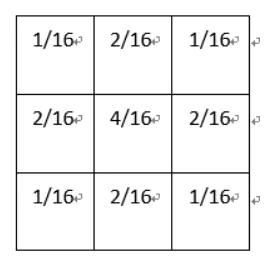 高斯平滑.png
高斯平滑.png
高斯平滑水平和垂直方向呈现高斯分布,更突出了中心点在像素平滑后的权重,相比于均值滤波而言,有着更好的平滑效果
高斯原图.png
高斯平滑图.png
四.卷积构造方法
- 激活函数:
在神经网络中,激活函数的作用是能够给神经网络加入一些非线性因素,使得神经网络可以更好地解决较为复杂的问题.
在神经网络中,我们有很多的非线性函数来作为激活函数,比如连续的平滑非线性函数(sigmoid,tanh和softplus),连续但不平滑的非线性函数(relu,relu6和relu_x)和随机正则化函数(dropout).
所有的激活函数都是单独应用在每个元素上面的,并且输出张量的维度和输入张量的维度一样.
tf.nn.relu(features, name = None):这个函数的作用是计算激活函数relu,即max(features, 0)
import tensorflow as tf a = tf.constant([-1.0, 2.0]) with tf.Session() as sess: b = tf.nn.relu(a) print(sess.run(b)) 输出:[0. 2.]rule.png
tf.nn.relu6(features, name = None):这个函数的作用是计算激活函数relu6,即min(max(features, 0), 6)
import tensorflow as tf a = tf.constant([-1.0, 12.0]) with tf.Session() as sess: b = tf.nn.relu6(a) print(sess.run(b)) 输出:[0. 6.]rule6.png
tf.nn.softplus(features, name = None):这个函数的作用是计算激活函数softplus,即log( exp( features ) + 1)
import tensorflow as tf a = tf.constant([-1.0, 12.0]) with tf.Session() as sess: b = tf.nn.softplus(a) print(sess.run(b)) 输出:[ 0.31326166 12.000006 ]softplus.png
tf.sigmoid(x, name = None):这个函数的作用是计算 x 的 sigmoid 函数。具体计算公式为 y = 1 / (1 + exp(-x))
这个操作你可以看做是 tf.add 的一个特例,其中 bias 必须是一维的。该API支持广播形式,因此 value 可以有任何维度。但是,该API又不像 tf.add ,可以让 bias 的维度和 value 的最后一维不同。具体看使用例子 import tensorflow as tf a = tf.constant([[1.0, 2.0], [1.0, 2.0], [1.0, 2.0]]) sess = tf.Session() print(sess.run(tf.sigmoid(a))) 输出: [[0.7310586 0.880797 ] [0.7310586 0.880797 ] [0.7310586 0.880797 ]]sigmoid.png
tf.tanh(x, name = None):这个函数的作用是计算 x 的 tanh 函数。具体计算公式为 ( exp(x) - exp(-x) ) / ( exp(x) + exp(-x) )
这个操作你可以看做是 tf.add 的一个特例,其中 bias 必须是一维的。该API支持广播形式,因此 value 可以有任何维度。但是,该API又不像 tf.add ,可以让 bias 的维度和 value 的最后一维不同。具体看使用例子 import tensorflow as tf a = tf.constant([[1.0, 2.0],[1.0, 2.0],[1.0, 2.0]]) sess = tf.Session() print(sess.run(tf.tanh(a))) 输出: [[0.7615942 0.9640276] [0.7615942 0.9640276] [0.7615942 0.9640276]]tanh.png
- Dropout
当训练数据量比较小时,可能会出现因为追求最小差值导致训练出来的模型极度符合训练集,但是缺乏普适性,不能表达训练数据之外的数据;
本来有普适性的模型被训练成了具有训练集特殊性.png
以至于对于真实的数据产生了错误.png
解决方案:
tf.nn.dropout(x, keep_prob, noise_shape = None, seed = None, name = None)这个函数的作用是计算神经网络层的dropout。 一个神经元将以概率keep_prob决定是否放电,如果不放电,那么该神经元的输出将是0,如果该神经元放电,那么该神经元的输出值将被放大到原来的1/keep_prob倍。这里的放大操作是为了保持神经元输出总个数不变。比如,神经元的值为[1, 2],keep_prob的值是0.5,并且是第一个神经元是放电的,第二个神经元不放电,那么神经元输出的结果是[2, 0],也就是相当于,第一个神经元被当做了1/keep_prob个输出,即2个。这样保证了总和2个神经元保持不变 tf.nn.dropout是TensorFlow里面为了防止或减轻过拟合而使用的函数,它一般用在全连接层。 Dropout就是在不同的训练过程中随机扔掉一部分神经元。也就是让某个神经元的激活值以一定的概率p,让其停止工作,这次训练过程中不更新权值,也不参加神经网络的计算。但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了 import tensorflow as tf a = tf.constant([[[[-1.0, 2.0, 3.0, 4.0,5.0,2]]],[[[2,2,2,3,3,4]]]]) print(a.shape) with tf.Session() as sess: b = tf.nn.dropout(a, 0.5) print(sess.run(b)) b = tf.nn.dropout(a, 0.5) print(sess.run(b)) 输出: [[[[-2. 0. 6. 0. 0. 4.]]] [[[ 0. 0. 4. 0. 0. 8.]]]] [[[[-0. 4. 0. 8. 0. 4.]]] [[[ 4. 0. 0. 0. 0. 8.]]]]dropout.png
- 卷积层
卷积操作是使用一个二维的卷积核在一个批处理的图片上进行不断扫描。具体操作是将一个卷积核在每张图片上按照一个合适的尺寸在每个通道上面进行扫描;
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)
这个函数的作用是对一个四维的输入数据 input 和四维的卷积核 filter 进行操作,然后对输入数据进行一个二维的卷积操作,最后得到卷积之后的结果;
tf.nn.bias_add(value, bias, name = None):这个函数的作用是将偏差项 bias 加到 value 上面;这个操作你可以看做是 tf.add 的一个特例,其中 bias 必须是一维的。该API支持广播形式,因此 value 可以有任何维度。但是,该API又不像 tf.add ,可以让 bias 的维度和 value 的最后一维不同。具体看使用例子 import tensorflow as tf a = tf.constant([[1.0, 2.0],[1.0, 2.0],[1.0, 2.0]]) b = tf.constant([2.0,1.0]) c = tf.constant([1.0]) sess = tf.Session() print(sess.run(tf.nn.bias_add(a, b))) # !!! 因为 a 最后一维的维度是 2 ,但是 c 的维度是 1,所以以下语句将发生错误 # print(sess.run(tf.nn.bias_add(a, c))) # 但是 tf.add() 可以正确运行 print(sess.run(tf.add(a, c)))
- 池化层
池化操作是利用一个矩阵窗口在输入张量上进行扫描,并且将每个矩阵窗口中的值通过取最大值,平均值或者XXXX来减少元素个数;
Maxpooling 就是在这个区域内选出最能代表边缘的值,然后丢掉那些没多大用的信息
为什么要这么做
举个例子
有四个美女,如果非要你选,你娶谁
你肯定会选最漂亮的(最符合的特征)tf.nn.max_pool(value, ksize, strides, padding, name=None):
这个函数的作用是计算池化区域中元素的最大值.
max.png
图例1.png
图例2.png
图例3.png
五.使用CNN预测手写数字
- 使用普通算法求手写数字准确率
# 导包
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('./',one_hot=True)
#构建模型
'''
我们通过为输入图像和目标输出类别创建节点,来开始构建计算图。
784是一张展平的MNIST图片的维度
'''
x = tf.placeholder(tf.float32, shape=[None, 784])
y = tf.placeholder(tf.float32, shape=[None, 10])
#为模型定义权重W和偏置b
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
'''
类别预测与损失函数
'''
pred = tf.nn.softmax(tf.matmul(x,W) + b)
cost = tf.reduce_mean(-tf.reduce_sum(y*tf.log(pred),reduction_indices=1))
optimizer = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
#训练保存模型
# Start training
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# Training cycle
for epoch in range(25):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/100)
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(100)
# Fit training using batch data
_, c = sess.run([optimizer, cost], feed_dict={x: batch_xs,
y: batch_ys})
# Compute average loss
avg_cost += c / total_batch
print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(avg_cost))
print("Optimization Finished!")
saver = tf.train.Saver()
saver.save(sess, "./model/estimator", global_step=i)
#加载模型并进行模型评估
with tf.Session() as sess:
saver = tf.train.Saver()
saver.restore(sess, tf.train.latest_checkpoint('./model'))
# tf.equal 来检测我们的预测是否真实标签匹配(索引位置一样表示匹配)。
correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
# Calculate accuracy for 3000 examples
#将布尔值转换为浮点数来代表对、错,然后取平均值。例如:[True, False, True, True]变为[1,0,1,1],计算出平均值为0.75。
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy,feed_dict={x: mnist.test.images[:3000], y: mnist.test.labels[:3000]}))
y_ = tf.argmax(pred,1)
print(sess.run(y_,feed_dict={x:mnist.test.images[:100]}))
print(mnist.test.labels[:100].argmax(-1))
print(sess.run(correct_prediction,feed_dict={x: mnist.test.images[:3000], y: mnist.test.labels[:3000]}).sum()/3000)
- 使用卷积神经求手写数字准确率
#导包
# 导包
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('./',one_hot=True)
#权重初始化以及卷积和池化
def weight_variable(shape):
initial = tf.random_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
#第一层卷积
'''一个卷积接一个max pooling完成。卷积在每个5x5的patch中算出32个特征。
卷积的权重张量形状是[5, 5, 1, 32],
前两个维度是patch的大小,接着是输入的通道数目,最后是输出的通道数目。
而对于每一个输出通道都有一个对应的偏置量。'''
W_conv1=weight_variable([5,5,1,32])
b_conv1=bias_variable([32])
#x变成一个4d向量,其第2、第3维对应图片的宽、高,
#最后一维代表图片的颜色通道数(因为是灰度图所以这里的通道数为1,如果是rgb彩色图,则为3
x_image=tf.reshape(x,[-1,28,28,1])
#把x_image和权值向量进行卷积,加上偏置项,然后应用ReLU激活函数,最后进行max pooling。
h_conv1=tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1)
h_pool1=max_pool_2x2(h_conv1)
#第二层卷积
# 为了构建一个更深的网络,我们会把几个类似的层堆叠起来。第二层中,每个5x5的patch会得到64个特征。
'''为了构建一个更深的网络,我们会把几个类似的层堆叠起来。第二层中,每个5x5的patch会得到64个特征。'''
W_conv2=weight_variable([5,5,32,64])
b_conv2=bias_variable([64])
h_conv2=tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2)
h_pool2=max_pool_2x2(h_conv2)
#全连接层
'''现在,图片尺寸减小到7x7,我们加入一个有1024个神经元的全连接层,用于处理整个图片。
我们把池化层输出的张量reshape成一些向量,乘上权重矩阵,加上偏置,然后对其使用ReLU。'''
W_fc1=weight_variable([7*7*64,1024])
b_fc1=bias_variable([1024])
h_pool2_flat=tf.reshape(h_pool2,[-1,7*7*64])
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1)
#为了减少过拟合,我们在输出层之前加入dropout
'''我们用一个placeholder来代表一个神经元的输出在dropout中保持不变的概率。
这样我们可以在训练过程中启用dropout,在测试过程中关闭dropout。'''
keep_prob=tf.placeholder(tf.float32)
h_fc1_drop=tf.nn.dropout(h_fc1,keep_prob)
#输出层
W_fc2=weight_variable([1024,10])
b_fc2=bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2)
#训练和评估模型
'''在feed_dict中加入额外的参数keep_prob来控制dropout比例。然后每100次迭代输出一次日志。
会用更加复杂的ADAM优化器来做梯度最速下降'''
cost = -tf.reduce_sum(y*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cost)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y: batch[1], keep_prob: 1.0})
print ("step %d, training accuracy %g"%(i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y: batch[1], keep_prob: 0.5})
print ("test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images, y: mnist.test.labels, keep_prob: 1.0}))
AdamOptimizer:
Adam 这个名字来源于adaptive moment estimation,自适应矩估计,如果一个随机变量 X 服从某个分布,X 的一阶矩是 E(X),也就是样本平均值,X 的二阶矩就是 E(X^2),也就是样本平方的平均值。Adam 算法根据损失函数对每个参数的梯度的一阶矩估计和二阶矩估计动态调整针对于每个参数的学习速率。TensorFlow提供的tf.train.AdamOptimizer可控制学习速度。Adam 也是基于梯度下降的方法,但是每次迭代参数的学习步长都有一个确定的范围,不会因为很大的梯度导致很大的学习步长,参数的值比较稳定。it does not require stationary objective, works with sparse gradients, naturally performs a form of step size annealing。AdamOptimizer通过使用动量(参数的移动平均数)来改善传统梯度下降,促进超参数动态调整