一、自动化测试模型
自动化测试模型介绍:线性测试、模块化驱动测试、数据驱动测试和关键字驱动测试
线性测试:每个测试脚本相对独立,且不产生其他依赖与调用,只是单纯的来模拟用户完整的操作场景。
模块化驱动测试:把重复的操作独立成公共模块,当用例执行过程中需要用到这一模块操作时则被调用。
数据驱动测试:就是数据的参数化,因为输入数据的不同从而引起输出结果的不同。
不管我们读取的是定义的数组、字典,或者是外部文件(excel、csv、txt、xml等)都可以看做是数据驱动,它的目的就是实现数据与脚本的分离。
1. 参数化登录
#public.py
from selenium.webdriver.common.keys import Keys
from time import sleep
class loginTest():
def login(self,driver,username,password):
driver.find_element_by_id("username").send_keys(username)
driver.find_element_by_name("j_password").send_keys(password)
sleep(2)
driver.find_element_by_name("j_password").send_keys(Keys.ENTER)
def quit(self,driver):
driver.quit()
#testlogin.py
#coding:utf-8
from selenium import webdriver
from time import sleep
from public import loginTest
class testLogin():
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.maximize_window()
driver.get("http://xxxxxx/adminAuth/login")
#admin登录
def login(self):
username='admin'
password='xxxxxxx'
loginTest().login(self.driver,username,password)
sleep(5)
loginTest().quit(self.driver)
testLogin().login()
2. 读取TXT文件
python提供了以下几种读取txt文件的方式
read():读取整个文件
readline():读取一行数据
readlines():读取所有行的数据
txt文件内容如下图所示,用来存放用户名和密码数据,并通过该文件中的数据作为用例的测试数据。
#TXT文件内容 zhangsan,123 lisi,456 wangwu,789
首先,将用户名和密码按行写入txt文件中,这里把用户名和密码用逗号“,”隔开。
#user_info.py
#coding:utf-8
from selenium import webdriver
from time import sleep
user_file=open('user_info.txt','r')
lines=user_file.readlines()
user_file.close()
for line in lines:
username=line.split(',')[0]
password=line.split(',')[1]
print(username,password)
运行结果如下图所示:
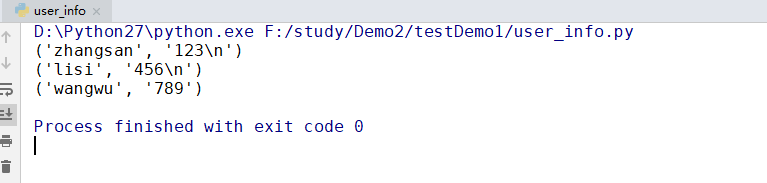
首先通过open()方法以读(“r”)的形式打开user_info.txt文件,使用readlines()方法按行读取txt文件,将获取到的每一行数据通过split()方法拆分出用户名和密码。split()可以将一个字符串通过某一个字符为分割点拆分成左右两部分,这里以逗号(,)为分割点。split()拆分出来的左右两部分以数组的形式存放。所以【0】可以去到左半部分的字符串,【1】可以取到右半部分的字符串。
3.读取CSV文件
创建info.csv文件,如下图所示
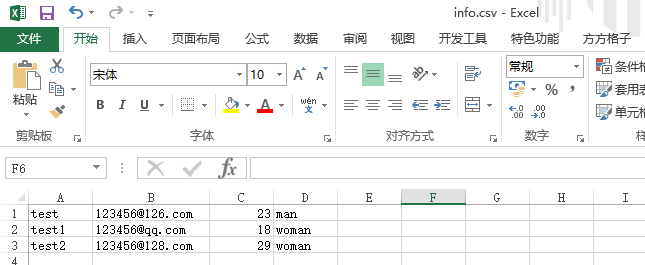
下面为csv_read.py文件
#csv_read.py
#coding:utf-8
import csv #导入csv包
#读取本地csv文件
date=csv.reader(open('info.csv','r'))
#循环输出每一行
for user in date:
print user
输出结果如下图所示:

首先导入csv模块,通过reader()方法读取csv文件,然后通过for循环遍历文件中的每一行数据。从打印结果看,读取的每一行数据均是以数组的形式存储的,取某一列,则只需指定数组下标即可。
#csv_read.py
#coding:utf-8
import csv #导入csv包
#读取本地csv文件
date=csv.reader(open('info.csv','r'))
#循环输出每一行
for user in date:
print user[1]
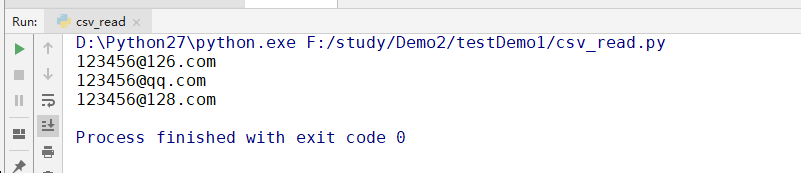
假如现在需要所有用户的邮箱地址,那么只需指定邮箱地址所在列的下标即可。数组下标是以0开始的,邮箱位于数组的第二列,所以指用户邮箱的下标为[1]。
4. 读取xml文件
有时,需要一个配置文件来配置当前自动化测试脚本的URL,浏览器、登录的用户名和密码等,这时候就可以选择使用XML文件来存放这些信息。
#Info.xml <?xml version="1.0" encoding="utf-8"?> <info> <base> <platform>Windows</platform> <browser>Chrome</browser> <url>http://www.baidu.com</url> <login username="admin" password="123456"/> <login username="guest" password="654321"/> </base> <test> <province>北京</province> <province>广东</province> <city>深圳</city> </test> </info>
#read_xml.py
#coding:utf-8
from xml.dom import minidom
#打开xml文档
dom=minidom.parse('info.xml')
#得到文档元素对象
root=dom.documentElement
print(root.nodeName)
print (root.nodeValue)
print (root.nodeType)
print (root.ELEMENT_NODE)

首先导入xml的minidom模块,用来处理XML文件,parse()用于打开一个XML文件,documentElement用于得到XML文件的唯一根元素。
每一个节点都有它的nodeName、nodeValue、nodeType等属性。nodeName为节点名称;nodeValue为节点的值,只对文本节点有效;nodeType为节点的类型。
5.获得任意标签名
#coding:utf-8
#获得任意标签名
from xml.dom import minidom
#打开xml文档
dom=minidom.parse('info.xml')
#获得文档元素对象
root=dom.documentElement
tagname=root.getElementsByTagName('browser')
print (tagname[0].tagName)
tagname=root.getElementsByTagName('login')
print (tagname[0].tagName)
tagname=root.getElementsByTagName('province')
print (tagname[0].tagName)
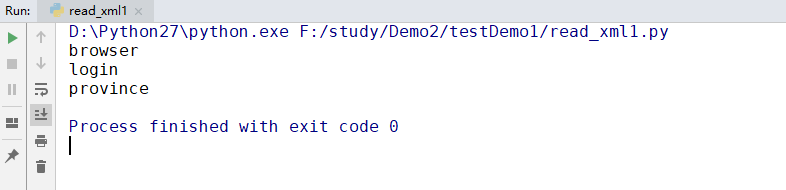
getElementsByTagName()可以通过标签名获取标签,它所获取的对象是以数组形式存放。可以通过指定数组的下标的方式获取某个具体标签。
1.getElementsByTagName('province')获得的是标签名为“peovince”的一组标签;
2.getElementsByTagName('province').tagname[0]表示一组标签中的第一个;
3.getElementsByTagName('province').tagname[2]表示一组标签中的第三个;
6.获得标签的属性值
#coding:utf-8
#获得任意标签名
from xml.dom import minidom
#打开xml文档
dom=minidom.parse('info.xml')
#获得文档元素对象
root=dom.documentElement
logins=root.getElementsByTagName('login')
#获得login标签的username属性值
username=logins[0].getAttribute("username")
print username
username=logins[1].getAttribute("username")
print username

getAttribute()方法用于获取元素的属性值,他和WebDriver中所提供的get_attribute()方法相似。
7.获得标签对之间的数据
#coding:utf-8
#获得任意标签名
from xml.dom import minidom
#打开xml文档
dom=minidom.parse('info.xml')
#获得文档元素对象
root=dom.documentElement
province=root.getElementsByTagName('province')
city=root.getElementsByTagName('city')
#获得第一个province标签对的值
p1=province[1].firstChild.data
print p1
c1=city[0].firstChild.data
print c1
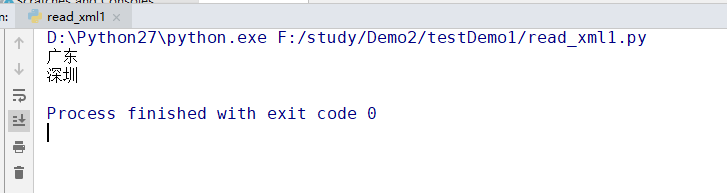
firstChild属性返回被选节点的第一个子节点。data表示获取该节点的数据,它和webdriver中提供的text方法类似。