相对于读书笔记,本文更像是一篇阅读大纲,在初步阅读本书后,尚有许多疑难,借用此大纲,以后温故而知新
DDIA讲了什么
什么是data-intensive
原文这样定义 Data-intensive applications are pushing the boundaries of what is possible by making use of these technological developments. We call an application data-intensive if data is its primary challenge—the quantity of data, the complexity of data, or the speed at which it is changing—as opposed to compute-intensive, where CPU cycles are the bottleneck.
即“数据密集型应用系统”(data-intensive)中数据的规模、复杂度或者数据产生与变化的速率等成为一个系统成败的决定性因素,与数据密集型系统相对应的是计算密集型系统(compute-intensive)。
主要内容
本书讲解了如何更好地驾驭处理数据和存储数据的相关技术,剖析成功的数据系统案例技术要点,分析有效应对当前环境苛刻要求的关键技术。
在DDIA这本书中,对数据系统有概要的介绍,然后是区分各自的优缺点与特性,然后分析这些特性是如何实现。
DDIA一书分为三部分,第一部分是数据系统的基石,一些基本的思想和组件;第二部分是分布式数据系统;第三部分是派生数据系统。
Part I.Founding of Data Systems
Chapter 1. Reliable、Scalable and Maintainable Applications
本章介绍数据系统的衡量标准 (对于一个系统(应用),都希望达到:Reliable, Scalable, and Maintainable)
数据密集型应用由以下标准模块构建而成
- 数据库:用以存储数据,之后的应用可以再次访问
- 高速索引:缓存那些复杂或者操作代价昂贵的结果,加快下一次访问
- 索引:用户可以按照关键字搜索数据并支持各种过滤
- 流式处理:持续发送消息至另一个进程,处理采用异步方式
- 批处理:定期处理大量的累计数据
Reliability
Reliability means making systems work correctly, even when faults occur. Faults can be in hardware (typically random and uncorrelated), software (bugs are typically sys‐tematic and hard to deal with), and humans (who inevitably make mistakes from time to time). Fault-tolerance techniques can hide certain types of faults from the end user.
即使发生故障,系统通过容错技术确保正常工作,避免影响最终用户。
Scalability
As the system grows (in data volume, traffic volume, or complexity), there should be reasonable ways of dealing with that growth. Scalability means having strategies for keeping performance good, even when load increases.In a scalable system, you can add processing capacity in order to remain reliable under high load.
对于可扩展的系统,增加处理能力的同时,还可以在高负载情况下持续保持系统的高可靠性。
伸缩性,当系统的规模增长的时候,系统能保持稳定的性能。这就有两个问题:如何定义负载(load parameter)、如何衡量性能(performance)。
这两个参数(指标)都取决于应用类型,比如web服务,那么负载就是每秒的请求数,而性能就是系统每秒能处理的请求数目。
当负载增大的时候,有两种方式衡量性能:
- 如果系统资源不变,系统性能会有什么变化
- 为了保证性能不变,需要增加多少资源
Maintainability
Over time, many different people will work on the system (engineering and oper‐ations, both maintaining current behavior and adapting the system to new use cases), and they should all be able to work on it productively. Maintainability has many facets, but in essence it’s about making life better for the engineering and operations teams who need to work with the system. Good abstrac‐tions can help reduce complexity and make the system easier to modify and adapt for new use cases. Good operability means having good visibility into the system’s health,and having effective ways of managing it.
可维护性本质是为了让工程和运营团队更为轻松。良好的抽象可以帮助降低复杂性,并使系统更易于修改和适配新场景;良好的可操作性意味着对系统健康状况有良好的观测性和高效的管理方式。
提高软件可维护性的三个设计原则:
- 可运维性:方便运营团队保持系统平稳运行
- 简单性:简化系统复杂性,便于新工程师理解系统
- 可塑性:后续工程师轻松对系统进行改进
Chapter 2. Data Models and Query Languages
本章对比了多种不同的数据模型和查询语言,本章设计的专业名词过多,太过陌生,还需细致了解。
Data model是数据的组织形式,在这一部分,介绍了relational model、document model、graph-like data model,不同的数据模型的存储方式、查询方式差异很大。因此,应用需要根据数据本身的关联关系、常用查询方式来来选择合适的数据模型。
数据与数据之间,有不同的关联形式:one to one,one to many,many to one,many to many。one to one,one to many都较好表示,困难的是如何高效表示many to one,many to many。早在1970s年代,就有两个流派尝试来解决many to many的问题,relational model, network model,自然,network model是更加自然、更好理解的抽象,但是相比relational model而言,难以使用,难以维护。因此relational model逐渐成为了主流的解决方案。
relatioal model将数据抽象为关系(relation,sql中称之为table),每一个关系是一组形式类似的数据的集合。对于many to many的数据关联,relational model将数据分散在不同的relation中,在查询时通过join聚合。
sql是典型的声明式查询语言(declarative query language),只要描述需要做什么,而不需关心具体怎么做,给用户提供的是一个更简洁的编程界面。
Nosql
2009年左右,Nosql(not only sql)逐渐进入人们的视野,近几年在各个领域得到了广泛的发展与应用。NoSQL具有以下特点:
- 天生分布式,更好的伸缩性,更大的数据规模与吞吐
- 开源
- 满足应用的特定需求
- 避免sql约束,动态数据模型
在Nosql阵营中,其中一支是以mongodb为代表的document db,对于one 2 many采用了层次模型的nested record;而对于many 2 one、many 2 many类似关系数据库的外键
这里有两个很有意思的概念:
schema-on-read (the structure of the data is implicit, and only interpreted when the data is read)
schema-on-write (the traditional approach of relational databases, where the schema is explicit and the database ensures all written data conforms to it)
显然,前者是document db采用的形式,后者是关系型数据采用的形式。前者像动态类型语言,后者则像静态类型语言,那么当schema修改的时候,前者要在代码中兼容;后者需要alter table(并为旧数据 增加默认值, 或者立即处理旧数据)。
Graph model
适合用于解决many to many的数据关联关系。
A graph consists of two kinds of objects: vertices (also known as nodes or entities) and edges (also known as relationships or arcs)
data model:property graph model; triple-store model(三元存储模型)
declarative query languages for graphs: Cypher, SPARQL, and Datalog
Chapter 3. Storage and Retrieval
在这一部分,主要是讲从数据库的角度来看,如何存储数据(store the data),如何查询数据(give data back to user)。
涉及到两种存储引擎: log-structured storage engines, andpage-oriented storage engines such as B-trees.
一个最简单的数据库:
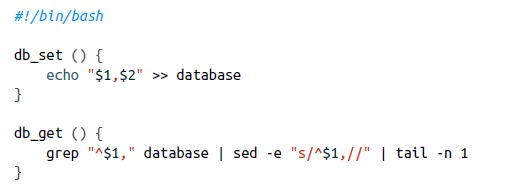
这两个命令组成了一个数据库需要的最基本的操作:存储数据(db_set),读取数据(db_get)。不难发现,db_set是非常高效的,但db_get性能会非常之差,尤其是db中拥有大量数据的时候。
事实上,绝大多数数据库写入性能都很好,而为了提高读取效率,都会使用到索引(Index):
- the general idea behind them is to keep some additional metadata on the side, which acts as a signpost and helps you to locate the data you want
索引是从原始数据(primary data)派生而来的结构,其目的是加速查询(query),索引的添加删除并不会影响到原始数据。但索引并不是银弹:在加速查询的同时,也会影响到写入速度,即在写入(更新)原始数据的同时,也需要同步维护索引数据。
Hash Index
前面的这个最简单的数据库,就是就是一个Log structure的例子,数据以append only的形式组织,即使是对同一个key的修改,也是添加一条新的数据记录。
hash是最为常见的数据结构中,在绝大多数编程语言都有对应的实现。hash在通过key获取value时速度很快,因此也非常适合用在DB查询。具体而言,value是key在文件中的偏移,这样,在db_set的同时修改key对用的文件偏移,在db-get的时候先从hash index中通过key读取偏移位置,然后再从文件读取数据。
hash index的优点在于以很简单的形式加速了查询,但缺点也很明显:hashindex是内存中的数据结构,因此需要内存足够大以容纳所有key-value对,另外hash index对于range query支持不太好。
SSTables and LSM-Trees
在前面simplest db中 log-structured segment中的key是无序的,数据按写入顺序存储。而另外一种格式,Sorted String Table, or SSTable:key则是有序的(磁盘上有序),同一个key在一个SSTable中只会出现一次。
SSTable具有优势:
- segment merge很容易,即使超过内存空间,归并排序
- 由于key有序,更容易查找
- 基于Sparse index,可以将两个key之间的record打包压缩有存储,节省磁盘和带宽
sstable是数据在文件上的组织形式,显然不大可能直接通过移动数据来保证key的有序性。因此都是在内存中用memtable中排序,当memtable的数据量达到一定程度,在以sstable的形式写到文件。关于sstable,memtable,《典型分布式系统分析:Bigtable》有一些介绍。
BTree
Btree是最为常用的索引结构,在关系型数据库以及大多数Nosql中都有广泛应用。如下图:
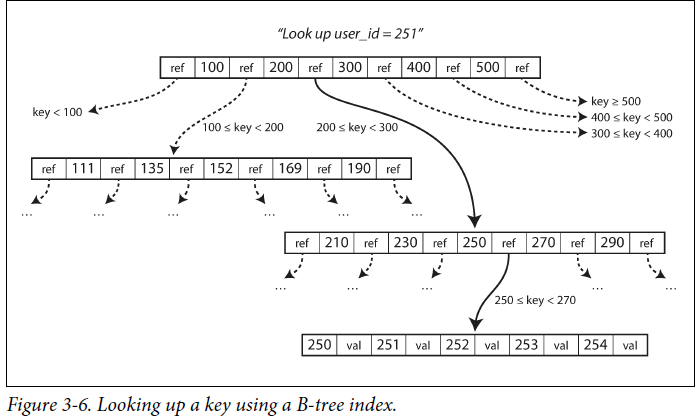
Btree中的基本单元称之为page,一般来说大小为4KB,读写都是以page为单位。
非叶子节点的page会有ref指向child page,这个ref有点像指针,只不过是在指向的是磁盘上的位置而不是内存地址。page的最大child page数目称之为branching factor(上图中branching factor为6),在存储引擎中,branching factor一般是好几百,因此,这个Btree深度只要三四层就足够了。
聚簇索引(clustered index)
前面介绍hash index,LSM的sparse index的时候,key映射的都是数据在文件中的偏移(offset),在Btree中,value既可以是数据本身,又可以是数据的位置信息。如果value就是数据本身,那么称之为clustered index,聚簇索引。
mysql常用的两个存储引擎Innodb,myisam都是用了Btree作为索引结构。但不同的是,Innodb的主索引(primary index)使用了聚簇索引,叶子节点的data域保存了完整的数据记录,如果还建立有辅助索引(secondary index),那么辅助索引的date域是主键的值;而对于myisam,不管是主索引还是辅助索引,data域都是数据记录的位置信息。
内存数据库
In memory db也是使用非常广泛的一类数据库,如redis,memcache,内存数据库的数据维护在内存中,即使提供某种程度上的持久化(如redis),也还是属于内存数据库,因为数据的读操作完全在内存中进行,而磁盘仅仅是为了数据持久化。
为什么In memory db 更快:核心不是因为不用读取磁盘(即使disk based storage也会缓存);而是不用为了持久化,而encoding in memory data structure。
Transaction Processing or Analytics?
online transaction processing(OLTP)与online analytic processing (OLAP)具有显著的区别,如下表所示
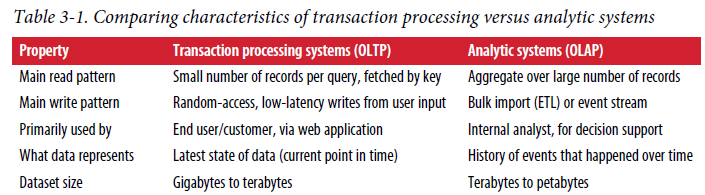
一般来说,数据库(不管是sql,还是nosql)既支持OLTP,又支持OLAP。但一般来说,线上数据库并不会同时服务OLTP与OLAP,因为OLAP一般是跨表、大量记录的查询与聚合,消耗很大,可能影响到正常的OLTP。
因此有了为数据分析定制化的数据库--数据仓库(Data Warehousing),数据的仓库的数据通过Extract–Transform–Load (ETL)导入,如下图所示:
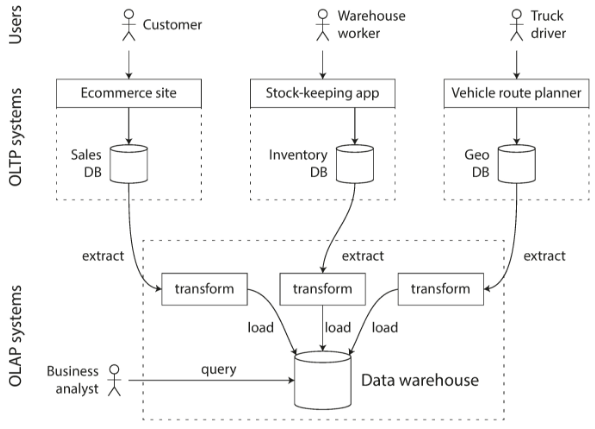
数据分析又一个特点:一次分析可能只会使用到table中的很少的几列,为了减少从磁盘读取更少的数据、以及更好的压缩存储,Column-Oriented Storage是一个不错的选择。
Chapter 4. Encoding and Evolution
数据有两种形态:
- 内存中:称之为对象(object)或者数据结构( structure)
- 网络或者文件中:二进制序列
数据经常要在这两种形态之间转换。
- in-memory representation to a byte sequence:encoding (serialization、marshalling), and the reverse is called decoding (parsing, deserialization, unmarshalling).
在本文中,翻译为序列化与反序列化。
应用在持续运营、迭代的过程中,代码和数据格式也会跟着发生变化。但代码的变更并不是一簇而就的,对于服务端应用,通常需要灰度升级(rolling upgrade),而客户端应用不能保证用户同时更新。因此,在一定的时间内,会存在新老代码、新老数据格式并存的问题。这就存在产生了兼容性问题.
- Backward compatibility: Newer code can read data that was written by older code.
- Forward compatibility:Older code can read data that was written by newer code.
在本章中,讨论了几种数据序列化协议、各个协议兼容性问题,以及数据是如何在各个进程之间流动的。
语言内置的序列化方式
大多数编程语言都天然支持内存数据与字节流的相互转换(即序列化与反序列化),如Java的java.io.Serializable, Ruby的Marshal , Python的pickle。但这些内置模块或多或少都有一些缺点:
- 与特定编程语言绑定,限制了以后的演化
- 安全性问题:
In order to restore data in the same object types, the decoding process needs to be able to instantiate arbitrary classes.
- 一般不考虑向前兼容性或向后兼容性问题
- 效率问题:包括速度与序列化后的size
跨语言的文本序列化协议 JSON XML
Json和Xml是两种使用非常广泛的序列化协议,二者最大的特点在于跨语言、自描述、可读性好。Json经常用于http请求的参数传递。
json和xml也有以下缺陷:
- 对数字的encoding不太友好,会有歧义(XML不能区分number、digital string;JSON不能区分整数与浮点数)
- 支持text string,但不支持binary string(sequences of bytes without a character encoding)。 所以经常需要额外使用base64先对binary string进行换换,这就是额外增加33%的空间(3Byte的binary string转化成4Byte的text string)
Binary Json
JSON协议的二进制进化版本核心是为了使用更少的空间,包括 MessagePack, BSON, BJSON, UBJSON, BISON等,其中由于MongoDB采样了BSON作为序列化协议,使用比较广泛。
除了更小的空间,Binary JSON还有以下优点
- 区分整数浮点数
- 支持binary string
下面是一个内存对象,后文用来对比各种序列化协议的效率(编码后size)
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
在这里用python json模块来序列化:
>>> dd = json.dumps(d, separators=(',', ':'))
>>> dd
'{"userName":"Martin","favoriteNumber":1337,"interests":["daydreaming","hacking"]}'
>>> len(dd)
81
在去除了空格的情况下需要81字节.
而使用msgpack编码如下:
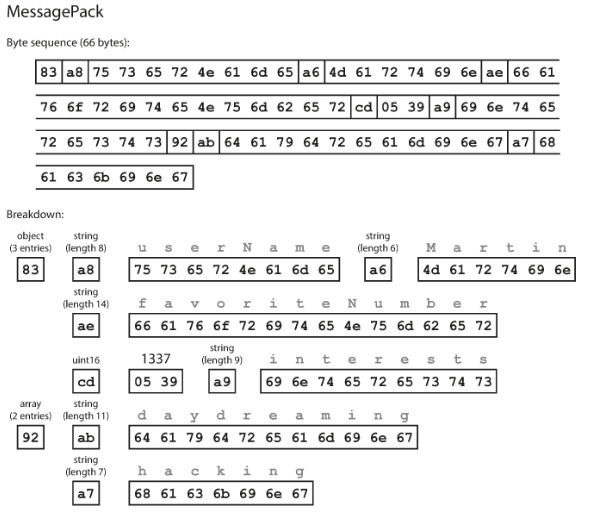
只需要66字节,与json序列化后的内容对比,很容易发现哪里使用了更少的字节.
Thrift and Protocol Buffers
binary json相关json而言,优化了空间,但幅度不是很大(81字节到66字节),原因在于,不管是JSON还是BSON都是自描述、自包含的(self-contained):在序列化结果中包含了fileld name。那么如果去掉field name,就能进一步压缩空间。
Apache Thrift 和 Protocol Buffers就是这样的二进制序列化协议:通过使用格式描述文件(schema),在序列化后的字节流中,不再包含fieldname,而是使用与fieldname对应的filed tag.
以protocol buffer为例,需要定义格式文件(.proto)
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
然后就可以通过工具转化成响应语言的代码,在代码里面,就包含了fieldname与tag的映射,比如上面user_name就映射到了1。一般来说,数字比字符串更省空间。下面是protocol buffer序列化后的结果:
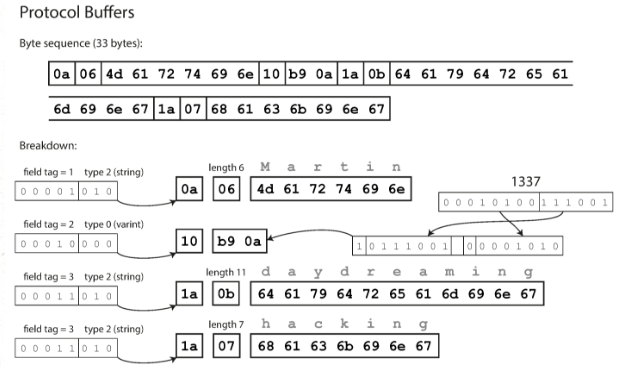
可以看到总共只需要33字节,相比Magpack的66字节有巨大的提升。优化来自于一下几点:
- 使用了field tag而不是fieldname, field tag还不到一个字节
- filed tag 与 field type压缩到了一个字节里面
- 使用了varint,用最少的字节标识一个整数
Thrift两种格式:BinaryProtocol and CompactProtocol,后者采用了与Protocol Buffer类似的压缩策略
Field tags and schema evolution
使用field tag之后,序列化后的数据就不在是自包含的,需要结合schema定义文件(产生的代码)来解读数据。那么在这种情况下如何保证兼容性呢。
首先向前兼容不是什么问题,即使在新的数据定义中增加了字段,旧代码只用忽略这个字段就行了。当然,在新的数据定义中如果要删除字段,那么只能删除可选的(optional)字段,而且不能使用相同的field tag
向后兼容性也好说,如果增加了字段,那么这个字段只要是可选的(optioanl),或者有默认值就行(default value)。
数据流动(DataFlow)
数据从一个节点(进程)流向另一个节点,大约有以下几种形式
- Via databases
- Via service calls
- Via asynchronous message passing
对于database,需要注意的是:当新加filed之后,旧的application level code(DAO)读到新代码所写入的数据(包含new filed)的时候,会忽略掉new field,那么旧代码之后写入到数据库的时候,会不会覆盖掉new filed。
service call有两种形式REST和RPC。
message queue相比RPC优点:
- 缓存(buffer),提高可用性
- 可以重复投递消息,提高可靠性
- 解耦合(无需知道消息消费者)
- 多个消费者