卷积神经网络简介
多层的线性网络和单层的线性网络没有区别,而且线性模型能够解决的问题是有限的。
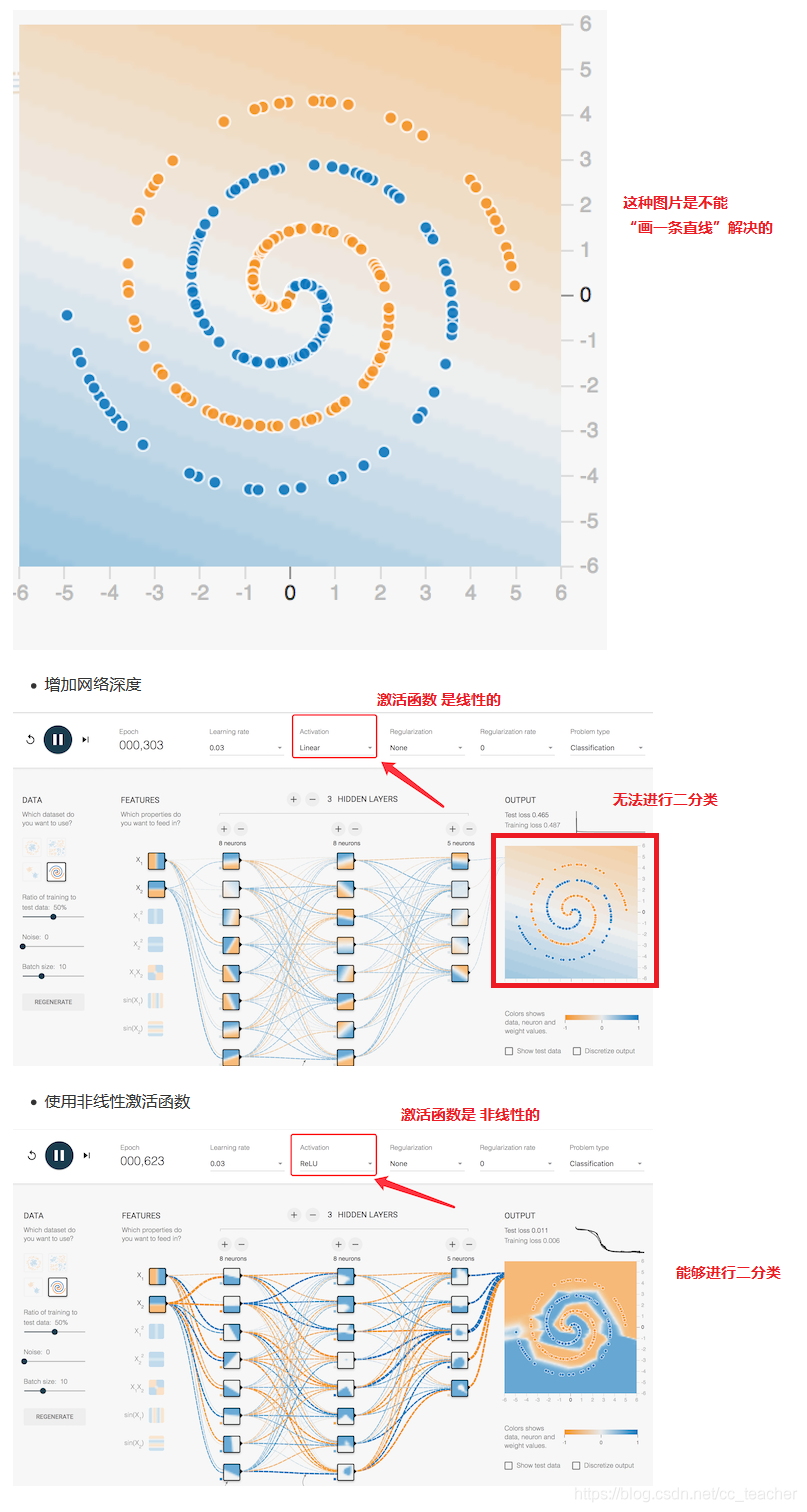
比如A Neural Network playground 中,第四张图形,是无法画一条直线分开的。
也就是,如果Activation只选择Linear的话,那么多层和单层的效果是一致的。
更复杂抽象的数据
一个单隐藏层含有更多的神经元,就能捕捉更多的特征。
有更多的隐藏层,意味着能从数据集中提取更多复杂的结构。
更多神经元+更深的网络=更复杂的抽象。
激活函数的选择
涉及网络优化的时候,会有不同的激活函数选择。
神经网络的隐藏层和输出单元用什么激活函数是一个重要的问题。
之前我们都是选用sigmod函数,但有时候其他的激活函数效果好得多。
这里主要介绍
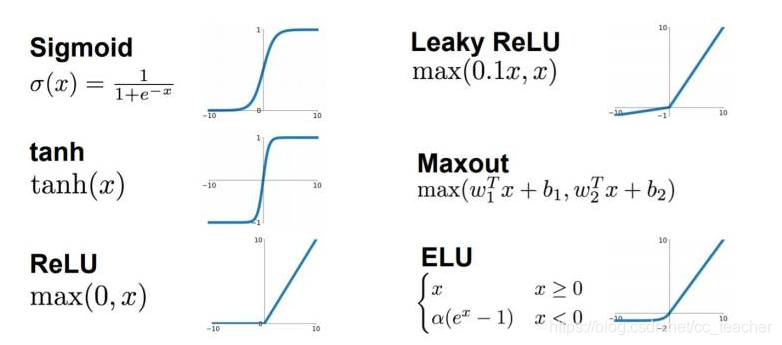
sigmod
tanh
ReLu
Leaky ReLu
tanh和sigmod非常相似,可以理解为tanh为sigmod向下平移了0.5。
tanh函数的效果比sigmod好,因为函数输出介于-1和1之间。
注意: tanh函数存在和sigmod函数一样的缺点,就是当z趋近无穷大(或无穷小),函数的梯度(即函数的斜率)就趋于0,这使得梯度算法的速度会减慢。
一般效果不错的的ReLu。
当z>0时,梯度始终为1,从而提高神经网络基于梯度算法的运算速度,收敛速度远大于sigmod和tanh。
然而当z<0时,梯度一直为0,但是在实际的运用中,该缺陷的影响不是很大。(比如像素值输入为[0,255])
Leaky ReLU 保证在 z < 0 的时候,梯度仍然不为 0。理论上来说,Leaky ReLU 有 ReLU 的所有优点,但在实际操作中没有证明总是好于 ReLU,因此不常用。
为什么需要非线性的激活函数
使用线性的激活函数 == 不使用激活函数 == 直接使用logistic回归
无论线性组合叠加多少层,最终都可以归结为一个线性组合 =》 相当于没有隐藏层,就成了最原始的感知机。

为什么需要卷积神经网络
图像特征数量对神经网络压力太大
假设下图是一图片大小为28 * 28 的黑白图片时候,每一个像素点只有一个值(单通道)。那么总的数值个数为 784个特征。

那现在这张图片是彩色的,那么彩色图片由RGB三通道组成,也就意味着总的数值有28 ×28×3 = 2352个值。

每个像素点有R、G、B三个特征,28×28个像素点就有28×28×3个特征。当然,通常这样的特征包含大量的冗余。
(这里先不纠结如何计算图像的特征数量)
从上面我们得到一张图片的输入是2352个特征值,即神经网路当中与若干个神经元连接,假设第一个隐层是10个神经元,那么也就是23520个权重参数。
如果图片再大一些呢,假设图片为1000 ×1000× 3,那么总共有3百万数值,同样接入10个神经元,那么就是3千万个权重参数。这样的参数大小,神经网络参数更新需要大量的计算不说,也很难达到更好的效果,大家就不倾向于使用多层神经网络了。
使用卷积神经网络: 减少网络的参数数量,达到更好的效果。
感受野
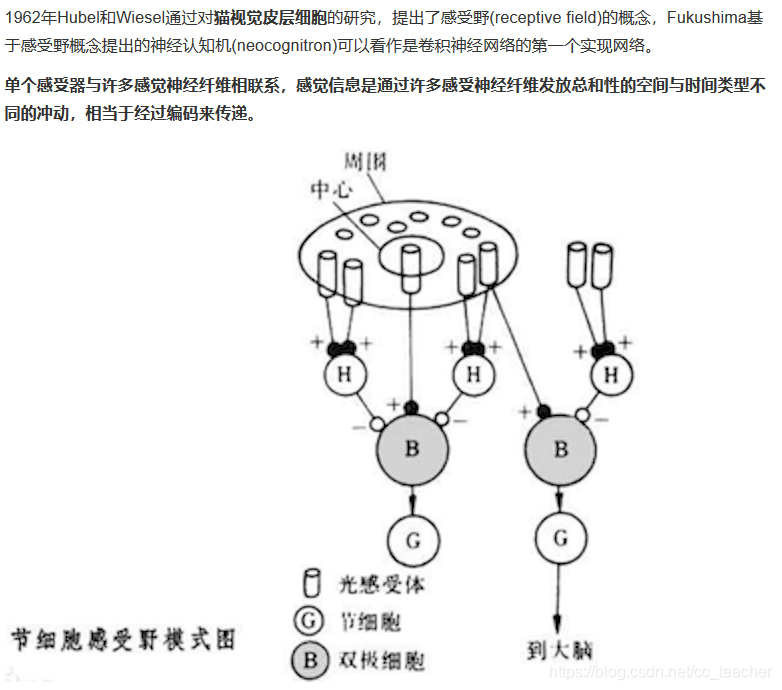
边缘检测
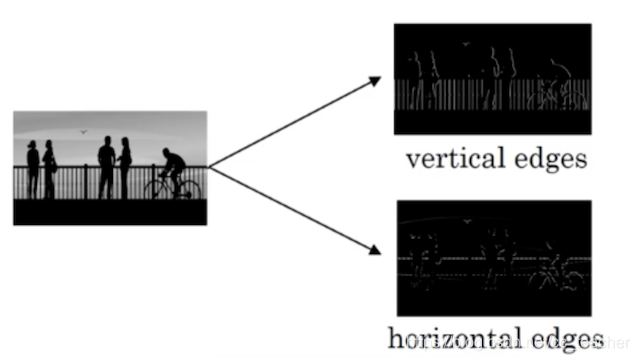
为了能够用更少的参数,检测出更多的信息,基于上面的感受野思想,通常神经网络需要检测出物体最明显的垂直和水平边缘来区分物体,比如
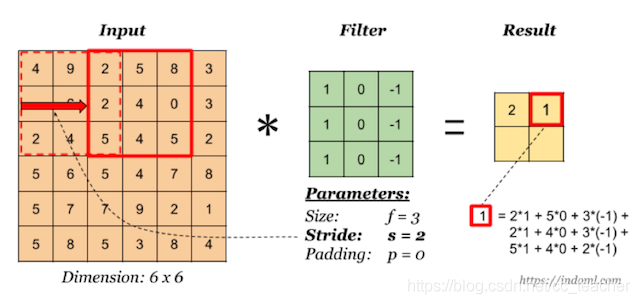
看一个列子,一个 6×6的图像卷积与一个3×3的过滤器(Filter or kenel)进行卷积运算
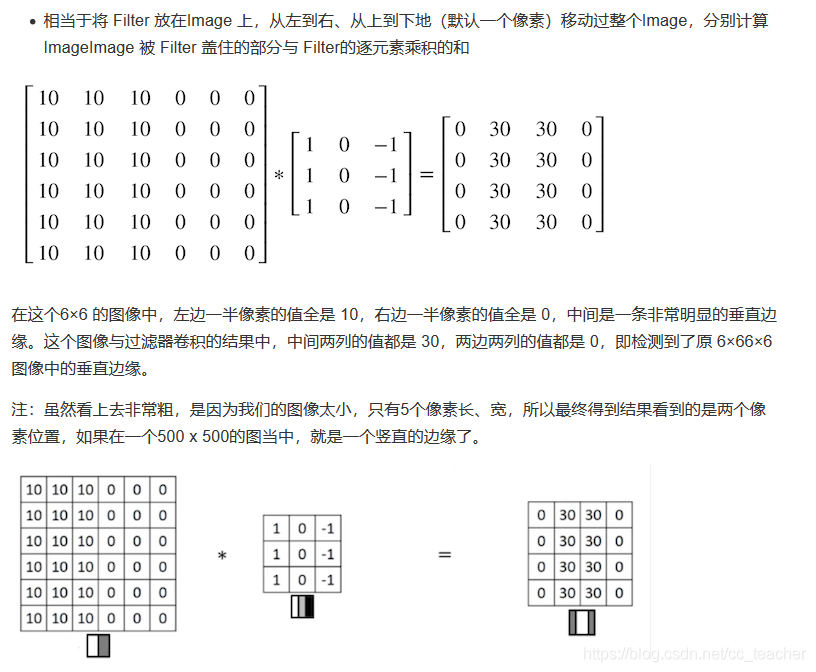
随着深度学习的发展,我们需要检测更复杂的图像中的边缘,与其使用由人工设置的过滤器,还可以将过滤器中的数值作为参数,通过反向传播来学习得到。
算法可以根据实际数据来选择合适的检测目标,无论是检测水平边缘,垂直边缘还是其他角度的边缘,并习得图像的低层特征。
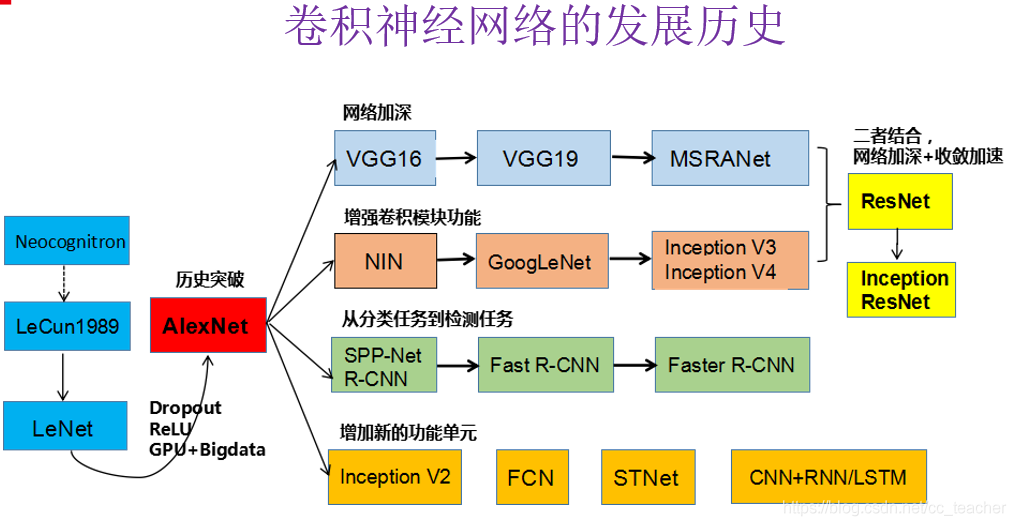
卷精神经网络发展历史
卷积神经网络原理
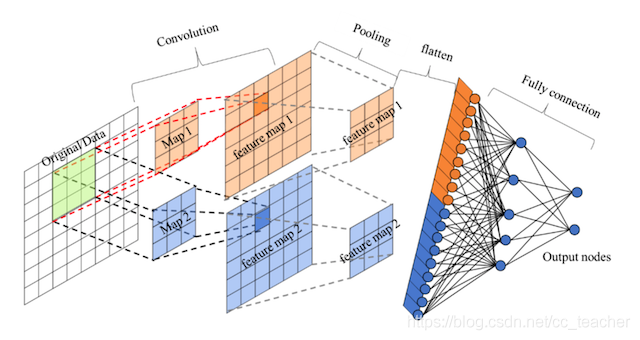
卷积神经网络的组成
卷积神经网络由一个或多个卷积层,池化层以及全连接层等组成。
卷积神经网络的特点在于隐藏层分为卷积层和池化层(pooling layer,又叫下采样层)。
卷积层:通过在原始图像上通过平移来提取特征,每一个特征就是一个特征映射。
池化层:通过特征后稀疏参数来减少学习的参数,降低网络的复杂度(最大池化和平均池化)。
与其他深度学习结构相比,卷积神经网络在图像等方面能够给出更好的结果。
相比其他浅层或深度神经网络,卷积神经网络需要考量的参数更少,使之成为一种颇具吸引力的深度学习结构。

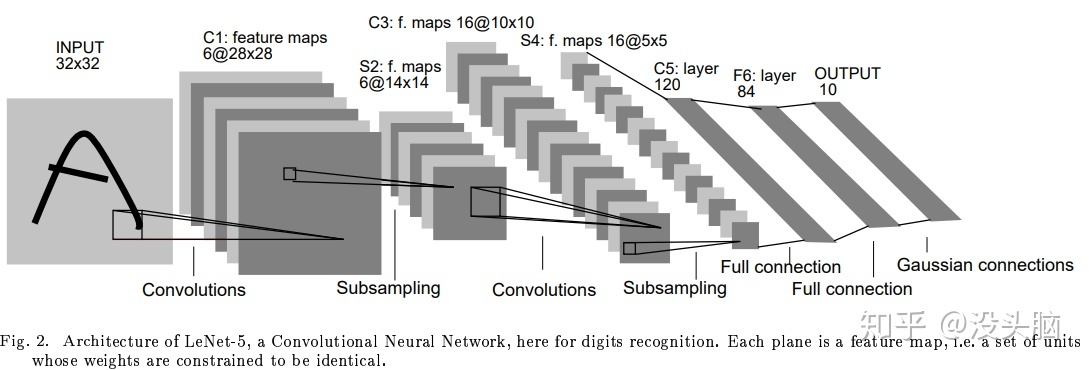
其中包含了几个主要结构
- 卷积层(Convolutions)
- 池化层(Subsampling)
- 全连接称(Full connection)
- 激活函数
卷积层
目的: 卷积运算的目的是提取输入的不同特征,某些卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代出提取出复杂的特征。
参数:
size: 卷积核/过滤器大小,选择有1×1,3×3,5×5
padding: 零填充,Valid与Same
stride: 步长,通常默认为1
计算公式:

卷积运算过程
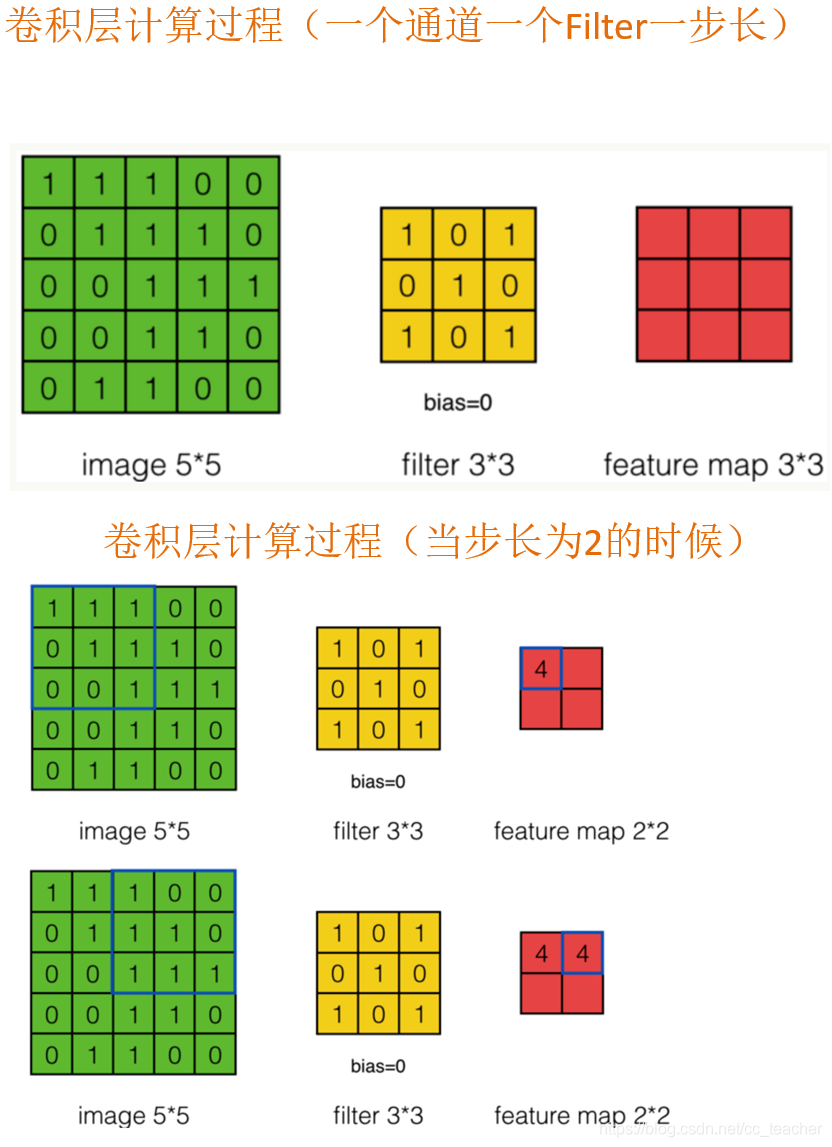
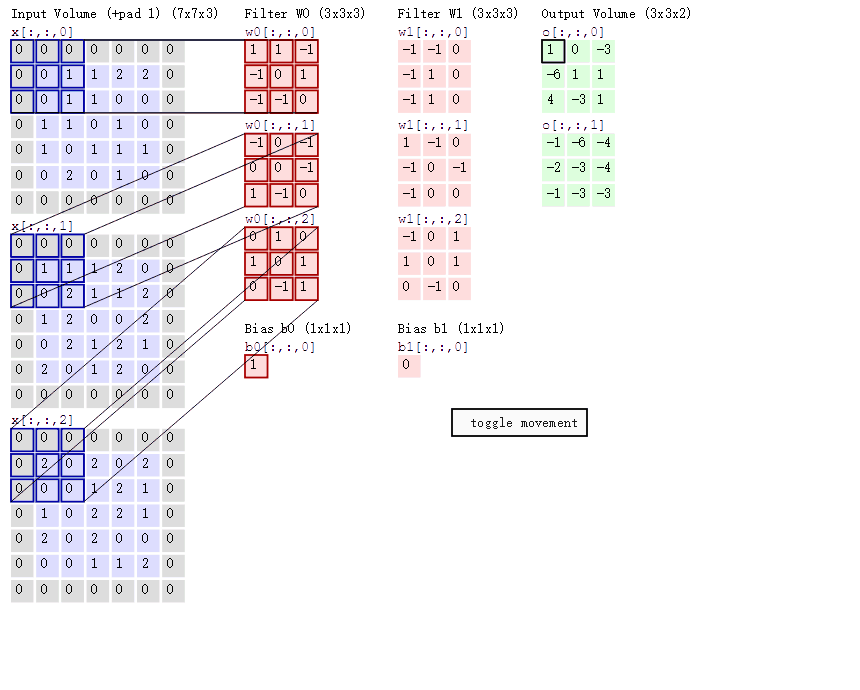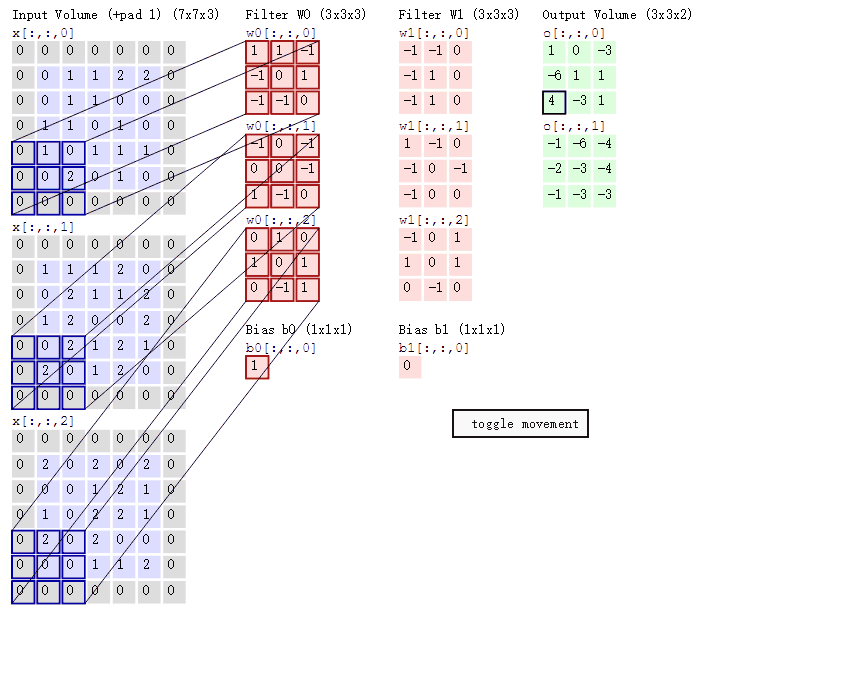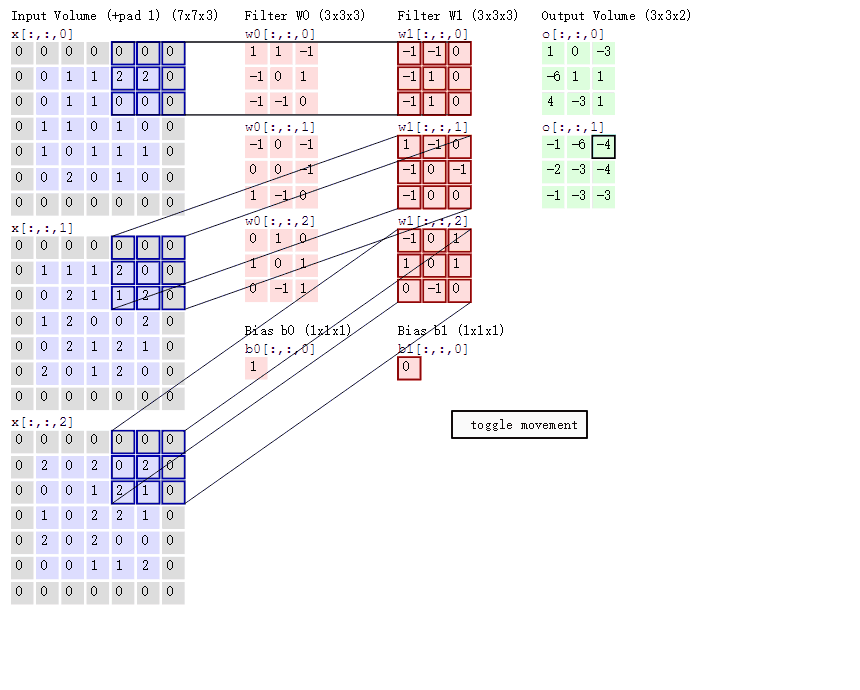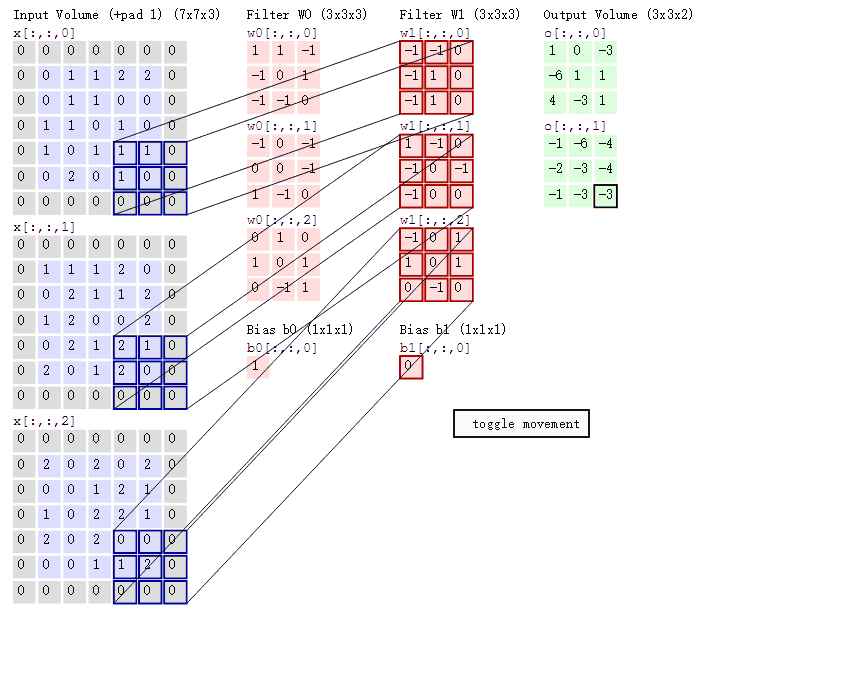
我们会发现进行卷积之后的图片变小了。
那么卷积层数是越多越好? 得到映射矩阵是越抽象越好吗?
如果我们换一个卷积核大小或者加入很多层卷积之后,图像可能最后就变成了1×1大小,这不是我们希望看到的结果。并且对原始图片中当中的边缘像素来说,只计算了一遍,二对于中间的像素会有很多次过滤器与之计算,这样就导致边缘信息的缺失。
缺点:
-
图像变小
-
边缘信息消失
padding-零填充
零填充: 在图片像素的最外层加上若干层0值,若一层,记作p=1。
为什么增加的是0?
因为0在权重乘积和运算中对最终结果不造成影响,也就避免了图片增加了额外的干扰信息。
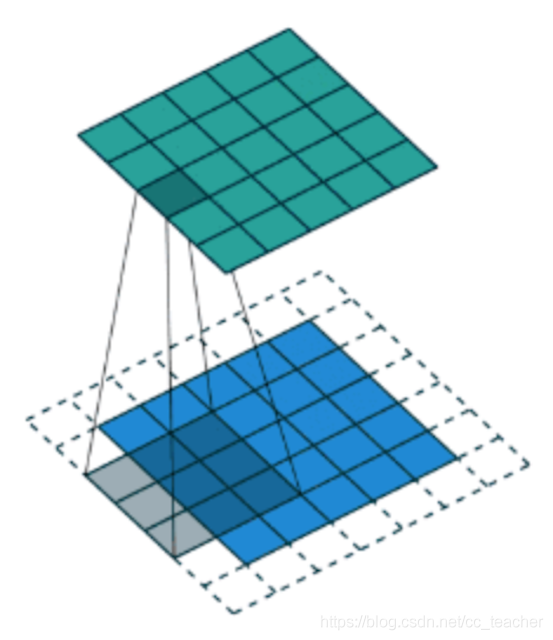
这张图中,还是移动一个像素,并且外面增加了一层0。
那么最终计算结果我们可以这样用公式来计算: 5+2∗p−3+1=5
P为1,那么最终特征结果为5。实际上我们可以填充更多的像素,假设为2层,则 5+2∗2−3+1=7,这样得到的观察特征大小比之前图片大小还大。所以我们对于零填充会有一些选择,该填充多少?
Valid and Same卷积
有两种形式,说了避免得到的矩阵比原始的图片还大的情况,一般都是使用Same这种填充卷积计算方式。
- Valid: 不填充
- Same: 输出大小与原图大小一致,那么N变成N+2P
那就意味着,之间大小与之后的大小一样,得出下面的等式
(N+2P-F+1)=N =》 P=(F-1)/2
所以知道了卷积核的大小之后,就可得出要填充多少层像素。
奇数维度的过滤器
结论:所有的卷积过滤器都是奇数的,比如1×1,3×3...
原因:
(1) P=(F-1)/2,如果F不是奇数而是偶数,那么最终计算结果不是一个整数,造成0.5,1.5...这种情况
(2) 奇数维度的过滤器有中心,便于指出过滤器的位置
当然这个都是一些假设的原因,最终原因还是在F对于计算结果的影响。所以通常选择奇数维度的过滤器,是大家约定成俗的结果,可能也是基于大量实验奇数能得出更好的结果。
stride-步长
以上例子中我们看到的都是每次移动一个像素步长的结果,如果将这个步长修改为2,3,那结果如何?

如果Padding选择Same,那么 (N+2P-F)/S+1=N, P=?
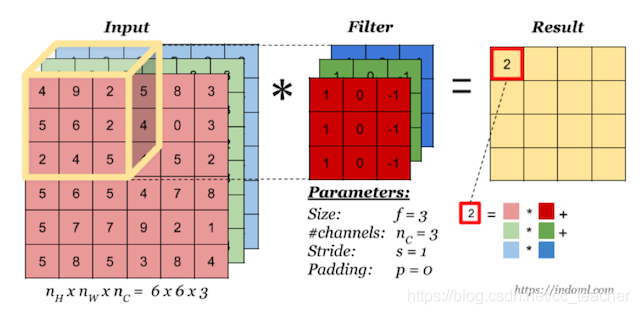
多通道卷积
当输入有多个通道(channel)时(例如图片可以有RGB三个通道),卷积核需要拥有相同的channel数,每个卷积核channel与输入层的对应channel进行卷积,将每个channel的卷积结果按位置相加最终得到 Feature Map。
(也就是最终多个通道也只是得到一张 Feature Map)
多卷积核(多个Filter)
当有多个卷积核时,可以学习到多种不同的特征,对应产生包含多个channel的Feature Map,例如上图有两个filter,所以output有两个channel。 这里的多少个卷积核也可以理解为多少个神经元。
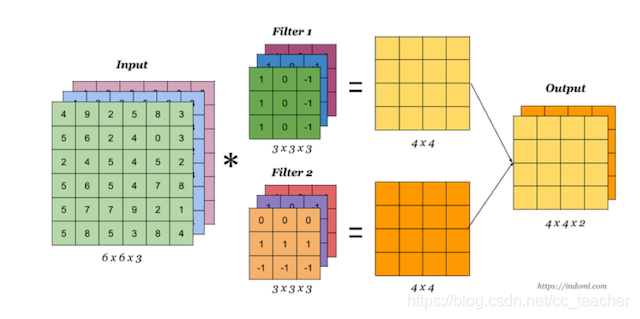
相当于我们把多个功能的卷积核的计算结果放在一起,能够检测到图片中不同的特征(边缘检测)。
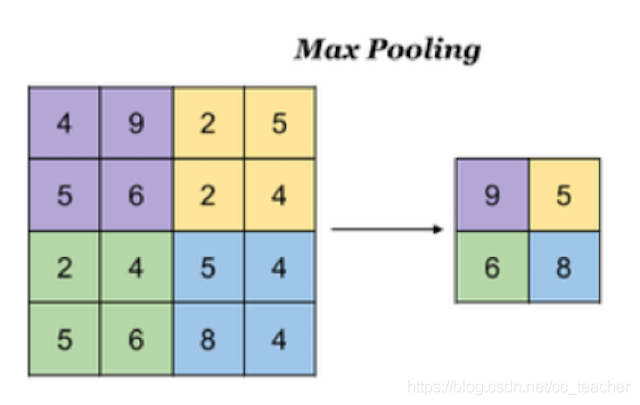
池化层(Pooling)
卷积层充当特征提取的角色,但是并没有减少图片的特征,在最后的全连接层依然面临大量的参数,所以需要池化层进行特征数量的减少。
池化层主要对卷积层学习到的特征图进行亚采样(subsampling)处理,主要有两种:
- 最大池化: Max Pooling,取窗口内的最大值作为输出
- 平均池化: Avg Pooling,取窗口内的所有值的均值作为输出
池化层的意义在于:
- 降低了后续网络层的输入维度,缩减模型大小,提高计算速度
- 提高了Feature Map的鲁棒性,防止过拟合。(换句话说,就是防止卷积观察的太仔细)
池化超参数特点: 不需要进行学习,不像卷积通过梯度下降进行更新。
池化后得到的Feature Map的大小和卷积后Feature Map大小的计算公式是一致的 (N+2P-F)/S+1
通过的池化窗口大小和步长为:2×2,2

全连接层
卷积层+激活层+池化层可以看层是CNN的特征学习/特征提取层,而学习到的特征(Feature Map)最终应用于模型任务(分类,回归)。
- 先对所有Feature Map进行扁平化(flatten,即reshape成1×N向量)
- 再接一个或者多个全连接层,进行模型学习。
小结
1. 多层的线性网络和单层的线性网络没有区别,而且线性模型能够解决问题有限。
比如A Neural Network playground 中,第四张图形,是无法画一条直线分开的。
也就是,如果Activation只选择Linear的话,那么多层和单层的效果是一致的。
2. 如何理解神经网络的单层神经元个数和层数?
一个单层隐藏层有更多的神经元,就能捕捉更多的特征
有更多的隐藏层,就能更加抽象的提取特征
更多神经元+更深的网络=更复杂的抽象。
3. 说一下几种常见的激活函数,画图,优缺点
sigmod,tanh,ReLu
sigmod,tanh归为一类,缺点就是x趋于无穷大或无穷小时,函数的梯度趋于0,导致梯度下降过慢
在靠近x=0的地方,梯度下降最快
ReLu可以保证x>0的时候,梯度始终为1。
但是x<0,梯度直接为0,但是这个缺陷在实际使用中影响并不大。
4. 为什么需要非线性的激活函数?
使用线性的激活函数 == 不使用激活函数 == 直接使用logistic回归
无论线性组合叠加多少层,最终都可以归结为一个线性组合 =》 相当于没有隐藏层,就成了最原始的感知机。
5. 为什么需要卷积神经网络?
图像对传统神经网络的压力太大,特征数量太多
卷积神经网络可以很好的处理图像
6. 什么是边缘检测?
就是一个窗口,这个窗口是有权重参数的,通过窗口中的权重,我们可以感知图片的边缘信息(比如垂直,水平的边缘信息)
窗口: 过滤器 =》 就是通过窗口的权重来过滤图片的边缘信息
而且窗口的数值,之前是人工设置的,现在也可以作为参数,然后通过反向传播来更新,这样算法就可以根据实际的数据,来学习需要学习的边缘信息。
7. 卷积神经网络由什么组成?
卷积层+池化层+全连接层
卷积层: 通过在原始图片上,通过窗口平移来提取特征,每一个特征都是特征映射
池化层: 去除不重要的参数,来减少网络复杂度
8. 卷积层的作用? 也就是卷积计算的作用?
卷积层的作用,就是使用卷积核(窗口)来提取不同的特征(不同的窗口可以提取不同的特征)
卷积计算就是特征的一个提取,也就是特征的一个映射。
9. 有关卷积层的计算公式?
10. 进行卷积操作的直观现象是什么?
直观线性就是卷积操作之后,计算得到的特征矩阵表小了(相当于进行了一次抽象,提取了边缘等特征)
但是卷积层不是越多越好,因为这样会导致边缘信息消失。
注意:一般卷积只是充当特征提取的角色,一般padding为same,不会减少输入量
11. 什么是padding零填充?为什么是填充零?
零填充就是在外围包围一层0,包围n层,p=n
填0的话不会影响后面的权重乘积和运算
12. padding的填充方式? 以及应该填充多上层?
valid: 不填充
same: 输出大小与原图一致
(N+2P−F+1)=N => P=(F-1)/2
还需要考虑步长 ((N+2P−F)/S+1)=N => P=...
13. 为什么过滤器都是选择奇数个?
(1) P=(F-1)/2, 为了避免出现0.5层这种情况
(2) 奇数维度的过滤器有中心,便于指出过滤器的位置
14. 如何理解多通道卷积和多卷积核?
多通道卷积:就是一个Filter多层(但是还是一个),一层对应一个channel,最终得到只有一个Feature Map
多卷积核: 有多个卷积核,不同的卷积核可以观察不同的特征,得到一个 Feature Map的集合。
15. 池化层的作用?
池化层的作用就是为了减少参数的维度
意义:
(1) 降低后续网络层的输入维度,缩减模型大小,提高计算速度
(2) 提高Feature Map的鲁棒性,防止过拟合(换句话说,就是放置卷积观察的太仔细)
16. 全连接层的作用?
前面的卷积层+激活层+池化层可以看成是CNN的特征学习/特征提取层,然后学习到的特征最终还是要输入到全连接层。
最终还是要输入到全连接层,最终还是回归为分类任务。