文本的tokenization
概念和工具的介绍
tokenization就是通常所说的分词,分出的每一个词语我们把它称为token。
常见的分词工具很多,比如:
jieba分词:https://github.com/fxsjy/jieba- 清华大学的分词工具THULAC:
https://github.com/thunlp/THULAC-Python
中英文分词的方法
- 把句子转化为词语
- 比如:
我爱深度学习可以分为[我,爱, 深度学习]
- 比如:
- 把句子转化为单个字
- 比如:
我爱深度学习的token是[我,爱,深,度,学,习]
- 比如:
N-garm表示方法
前面我们说,句子可以用单个字,词来表示,但是有的时候,我们可以用2个,3个或者多个词来表示。
N-gram一组一组的词语,其中的N表示能够被一起使用的词的数量。
例如:
In [59]: text = "深度学习(英语:deep learning)是机器学习的分支,是一种以人工神经网络为架构,对数据进行表征学习的算法。"
In [60]: cuted = jieba.lcut(text)
In [61]: [cuted[i:i+2] for i in range(len(cuted)-1)] #N-gram 中n=2时
Out[61]:[['深度', '学习'],
['学习', '('],
['(', '英语'],
['英语', ':'],
[':', 'deep'],
['deep', ' '],
[' ', 'learning'],
['learning', ')'],
[')', '是'],
['是', '机器'],
['机器', '学习'],
['学习', '的'],
['的', '分支'],
['分支', ','],
[',', '是'],
['是', '一种'],
['一种', '以'],
['以', '人工神经网络'],
['人工神经网络', '为'],
['为', '架构'],
['架构', ','],
[',', '对'],
['对', '数据'],
['数据', '进行'],
['进行', '表征'],
['表征', '学习'],
['学习', '的'],
['的', '算法'],
['算法', '。']]
在传统的机器学习中,使用 N-gram 方法往往能够取得非常好的效果。在深度学习比如RNN中会自带 N-gram的效果。
向量化
因为文本不能够直接被模型计算,所以需要将其转换为向量。
将文本转换为向量有两种方法:
(1) 转换为 one-hot 编码
(2) 转换为 word embedding
one-hot编码
在one-hot编码中,每一个token使用一个长度为N的向量表示,N表示词典的数量
即:把待处理的文档进行分词或者是N-gram处理,然后进行去重得到词典,假设我们有一个文档:深度学习,那么进行one-hot处理后的结果如下:
| token | one-hot encoding |
|---|---|
| 深 | 1000 |
| 度 | 0100 |
| 学 | 0010 |
| 习 | 0001 |
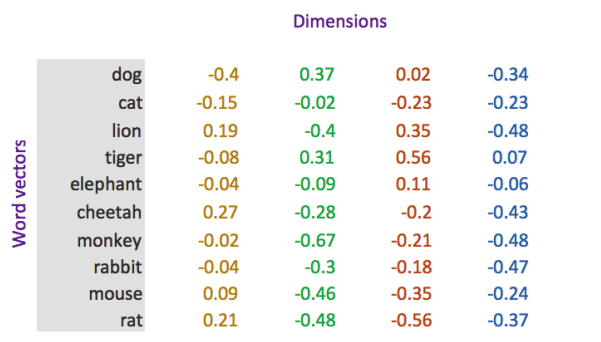
word embedding
word embedding 是深度学习中表示文本常用的一种方法。和 one-hot 编码不同,word embedding使用了浮点型的稠密矩阵来表示token。根据词典的大小,我们的向量通常使用不同维度,例如100,256,300等。 其中向量的每一个值是一个参数,其初始值是随机生成的,之后再训练的过程中进行学习而获得。
如果我们文本中有20000个词语,如果使用one-hot编码,那么我们会有20000*20000的矩阵,其中大多数的位置都为0,但是如果我们使用word embedding来表示的话,只需要20000* 维度,比如20000*300
形象的表示就是:
| token | num | vector |
|---|---|---|
| 词1 | 0 | [w11,w12,w13...w1N] ,其中N表示维度(dimension) |
| 词2 | 1 | [w21,w22,w23...w2N] |
| 词3 | 2 | [w31,w23,w33...w3N] |
| ... | …. | ... |
| 词m | m | [wm1,wm2,wm3...wmN],其中m表示词典的大小 |
我们会把所有的文本转化为向量,把句子用向量来表示
但是在这中间,我们会先把token使用数字来表示,再把数字使用向量来表示。
即:token---> num ---->vector
因为词向量矩阵一开始随机值,要将token和id进行一个映射。
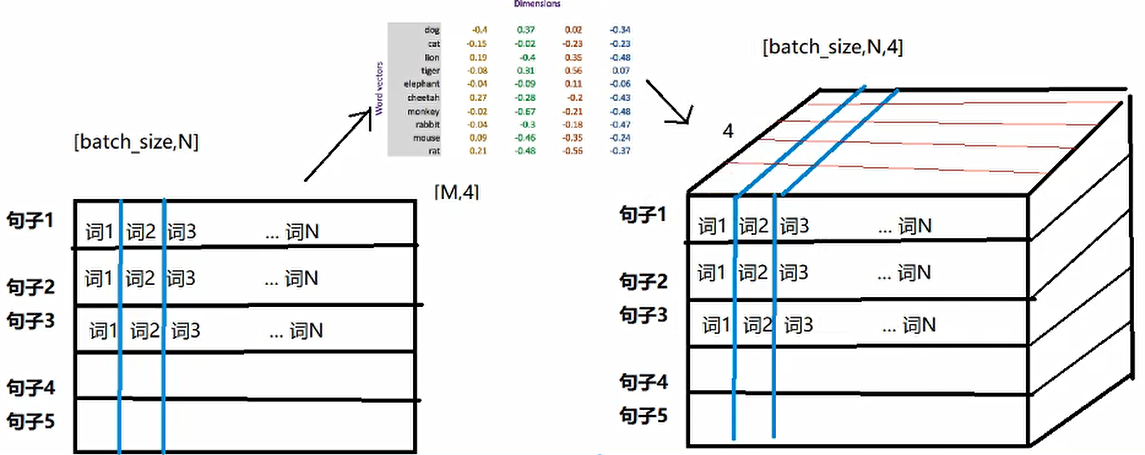
数据的形状变化
思考:每个batch中的每个句子有10个词语,经过形状为[20,4]的Word emebedding之后,原来的句子会变成什么形状?
每个词语用长度为4的向量表示,所以,最终句子会变为[batch_size,10,4]的形状。
增加了一个维度,这个维度是embedding的dim
小结
1. 什么是tokenization? 什么是token?
tokenization就是通常说的分词,分出的每一个词语我们把它称为token
分词工具一般使用 jieba
2. 分词方法有哪些?
(1) 把句子转换为词语
(2) 把句子转换为单个字
3. N-gram是什么?
N-gram 其实就是把分词的token 连续几个这么使用
分词列表
['深度', '学习', '(', '英语', ':', 'deep', ' ', 'learning', ')', '是', '机器', '学习', '的', '分支', ',', '是', '一 种', '以', '人工神经网络', '为', '架构', ',', '对', '数据', '进行', '表征', '学习', '的', '算法', '。']
使用 N-gram ,n=2的分词
[['深度', '学习'], ['学习', '('], ['(', '英语'], ['英语', ':'], [':', 'deep'], ['deep', ' '], [' ', 'learning'], ['learning', ')'], [')', '是'], ['是', '机器'], ['机器', '学习'], ['学习', '的'], ['的', '分支'], ['分支', ','], [',', '是'], ['是', '一种'], ['一种', '以'], ['以', '人工神经网络'], ['人工神经网络', '为'], ['为', '架构'], ['架构', ','], [',', '对'], ['对', '数据'], ['数据', '进行'], ['进行', '表征'], ['表征', '学习'], ['学习', '的'], ['的', '算法'], ['算 法', '。']]
N-gram的效果比普通分词的效果更好是因为N-gram考虑的 顺序
4. 文本向量化的方式有哪些?优缺点?
one-hot: 使用稀疏向量表示文本,占用空间多
word-embedding: 浮点型的稠密矩阵来表示token
5. 关于word-embedding
向量的每一个值是一个超参数,其初始值是随机生成的,之后在训练的过程中进行学习获得
api: torch.nn.Embedding(词典数量,embedding维度)
6. 思考:每个batch中的每个句子有10个词语,经过形状为[20,4]的Word emebedding之后,原来的句子会变成什么形状?
[batch_size,seq_len] -> [batch_size,seq_len,embedding_dim]