LeNet
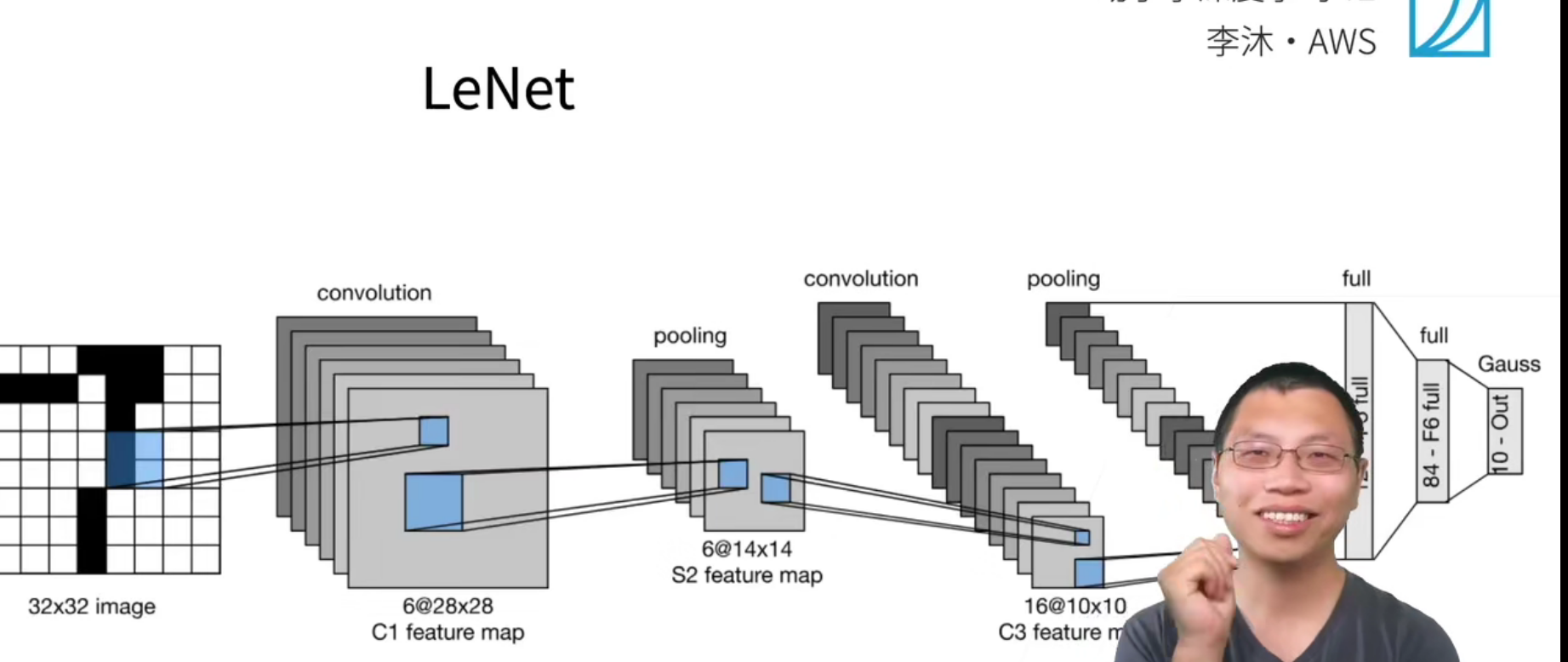




上面是LeNet的结构示意图。
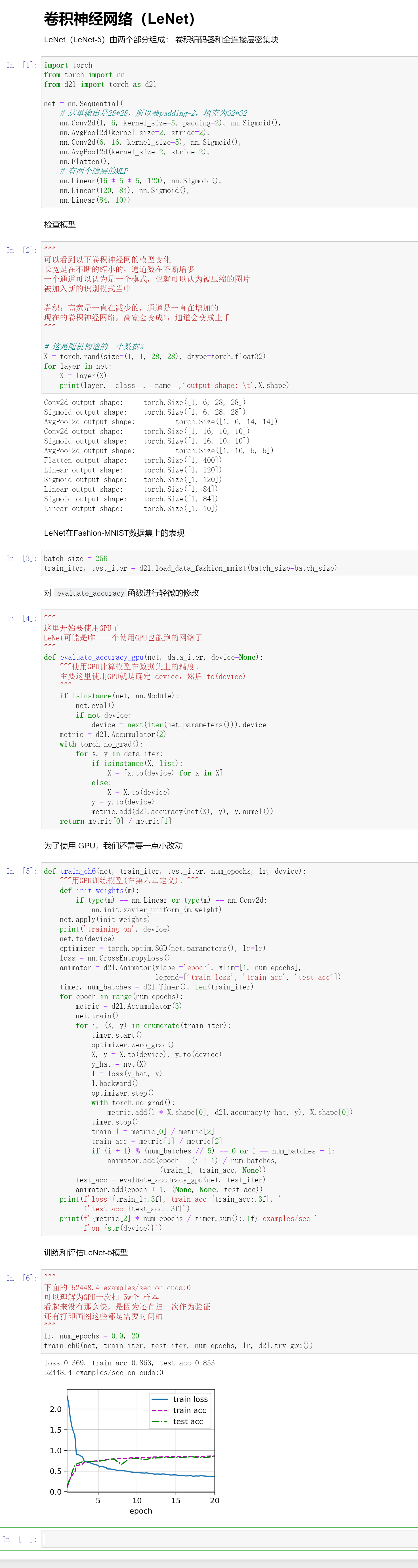
模型定义
net = nn.Sequential(
# 这里输出是28*28,所以要padding=2,填充为32*32
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10)) # 最后输出10个概率

代码
使用LeNet来在Fashion-Mnist数据集上进行训练。
QA
- 池化和卷积是不是更适合图像这类数据,而对于时序性数据(做分类)是不是不适用这类数据?
后面会将一个使用conv-1d来进行文本分类的案例。
至于要不要使用池化,其实没有确定答案,可以试,因为使用了池化也没有带来什么坏处。
- LeNet的第二个卷积层通道数增加到了16,这意味信息被放大了吗?
图片信息肯定是要压缩的,一般来说,就是卷积图片的高宽减半,然后通道增加一倍。(实际信息没有被放大,因为深度学习模型本质就是在压缩信息)
可以看到以下卷积神经网的模型变化,长宽是在不断的缩小的,通道数在不断增多,一个通道可以认为是一个模式,也就可以认为被压缩的图片,被加入新的识别模式当中
卷积:高宽是一直在减少的,通道是一直在增加的,现在的卷积神经网络,高宽会变成1,通道会变成上千。
- 池化层一般用max还是avg,用max的话会不会损失很多信息?
用max的意思是说只关心最大的那个信号量,也就是关系那个pattern是否出现了,如果出现了它的值就会很大,那么就把这个最大值拎出来就行了。(多通道输出,对应多个核)
max不见得比avg损失信息多,max其实比avg训练起来更好。
- 课程网站有个练习是将sigmoid替换为relu,是个sigmoid全替换为relu后模型基本不收敛,有什么原因吗?
不收敛的原因是因为学习率过大。
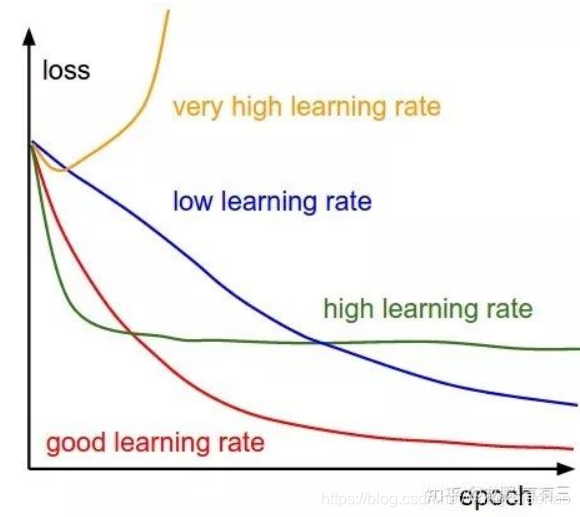
然后课程中给定sigmoid给到0.9的学习率其实给大了..
- 图像识别出来的特征,颜色可以打印出来吗?或者怎么去寻找网络到底学习了什么?
这个是可以打印出来的,有一个网站在做CNN 的可视化展示。
CNN Explainer,可以学习,直观感受CNN是如何工作的。
- 目前的卷积神经网络或其他深度学习是不是都需要较多的训练数据,如果训练数据体量很小是否不适合深度学习?是否有无监督/或小训练集的深度学习?
其实现在深度学习不需要很多数据集,我们后面会讲一个微调。
现在的深度学习,因为我们有很多在大量的数据集上训练好的模型,我们可以做到在真实的训练不需要训练样本,或者很少的训练样本就做的很好了。
我们这里讲的是从零开始学习,但是真实的应用不会真的从零开始的。