RNN

来将我们第一个对序列模型的神经网络——循环神经网络 RNN。
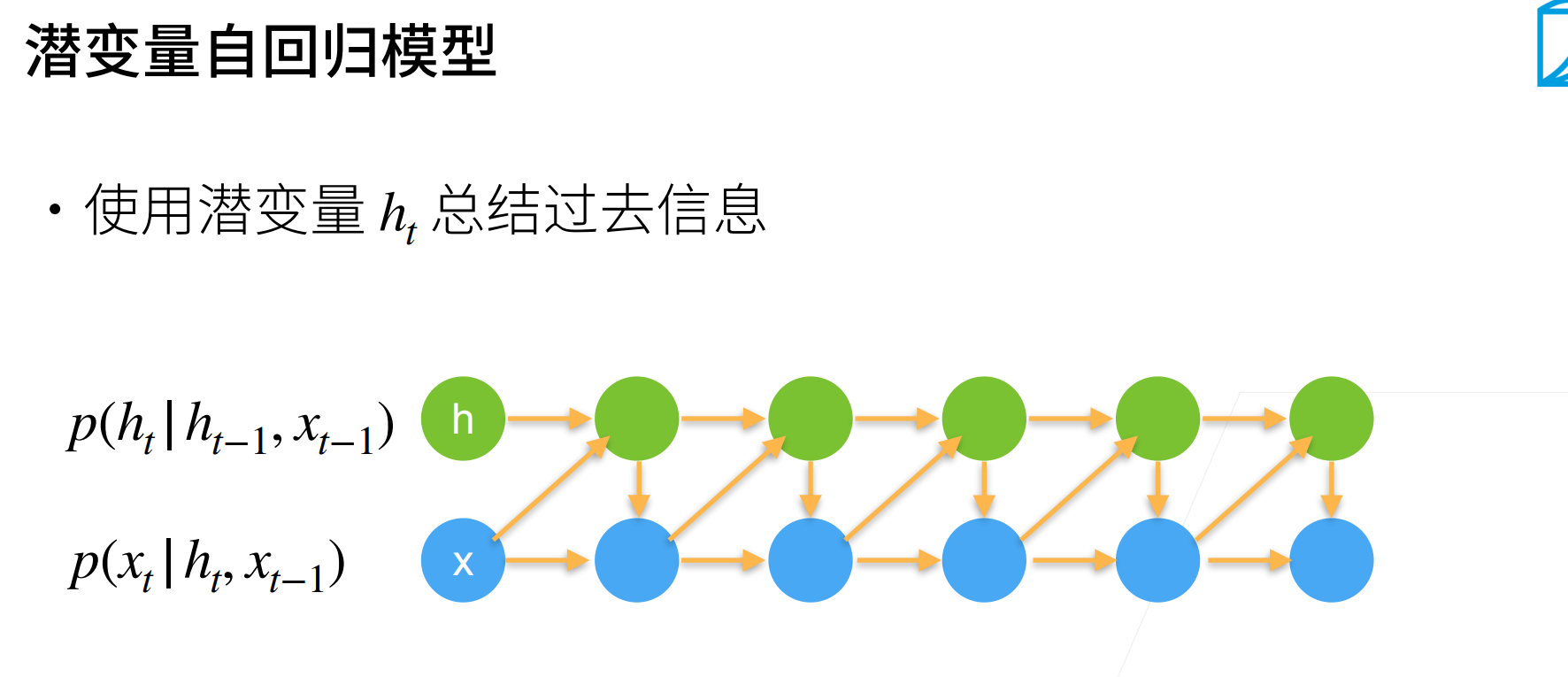
x是“你”,然后会去更新隐变量,要去预测“好”字。
接下来观察到了“好”,更新隐变量后要输一个逗号。
(o_t)是来match(x_t)的输入,但是生成(o_t)的时候你是不能看到(x_t)的。也就是当前时刻的输出是为了预测当前时刻的观察,但是你的输出发生在观察之前。
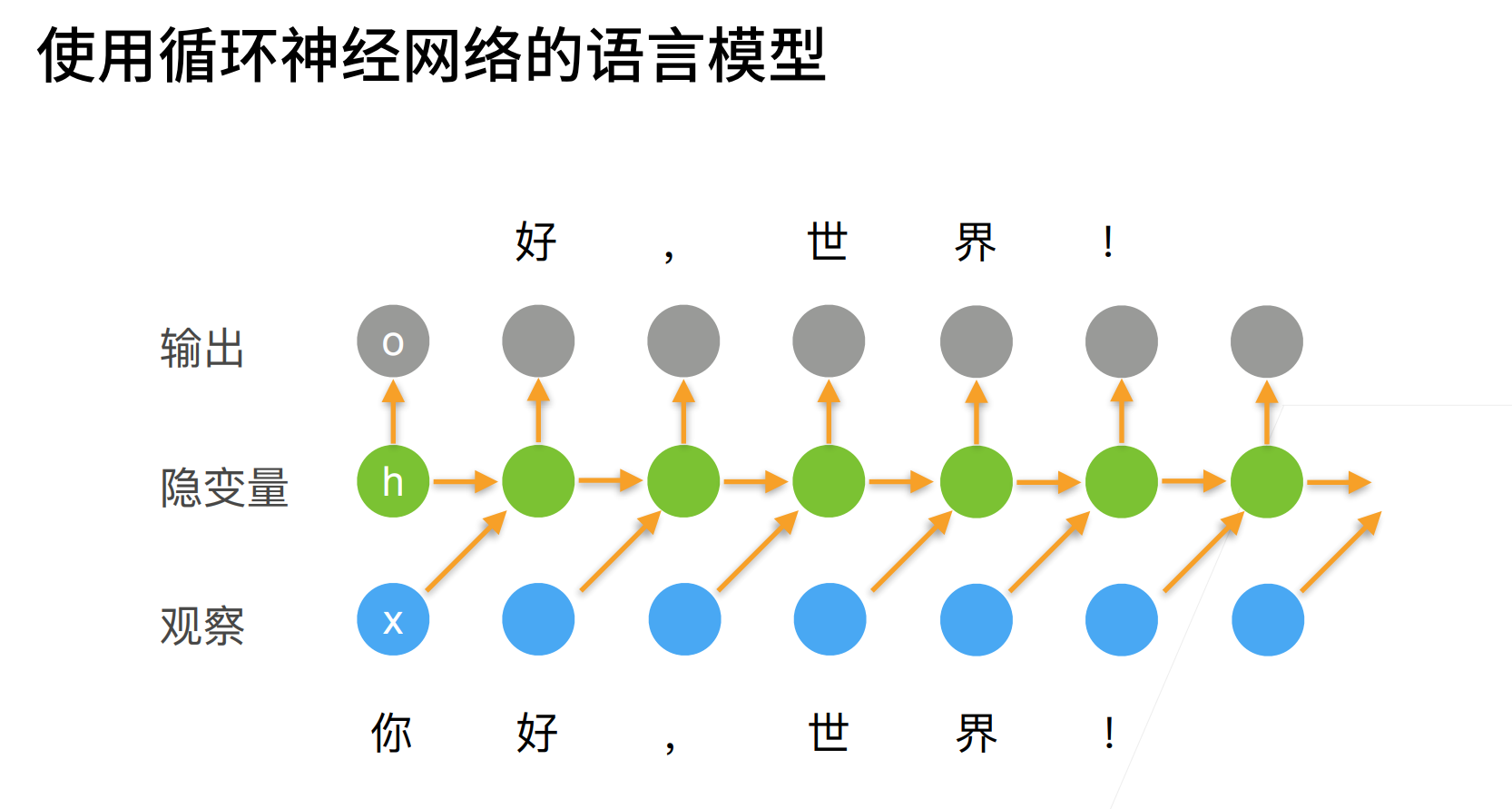
这里t时刻的输出是(x_{t-1},h_t),也就是t时刻的输出是没有用到(x_t)的。
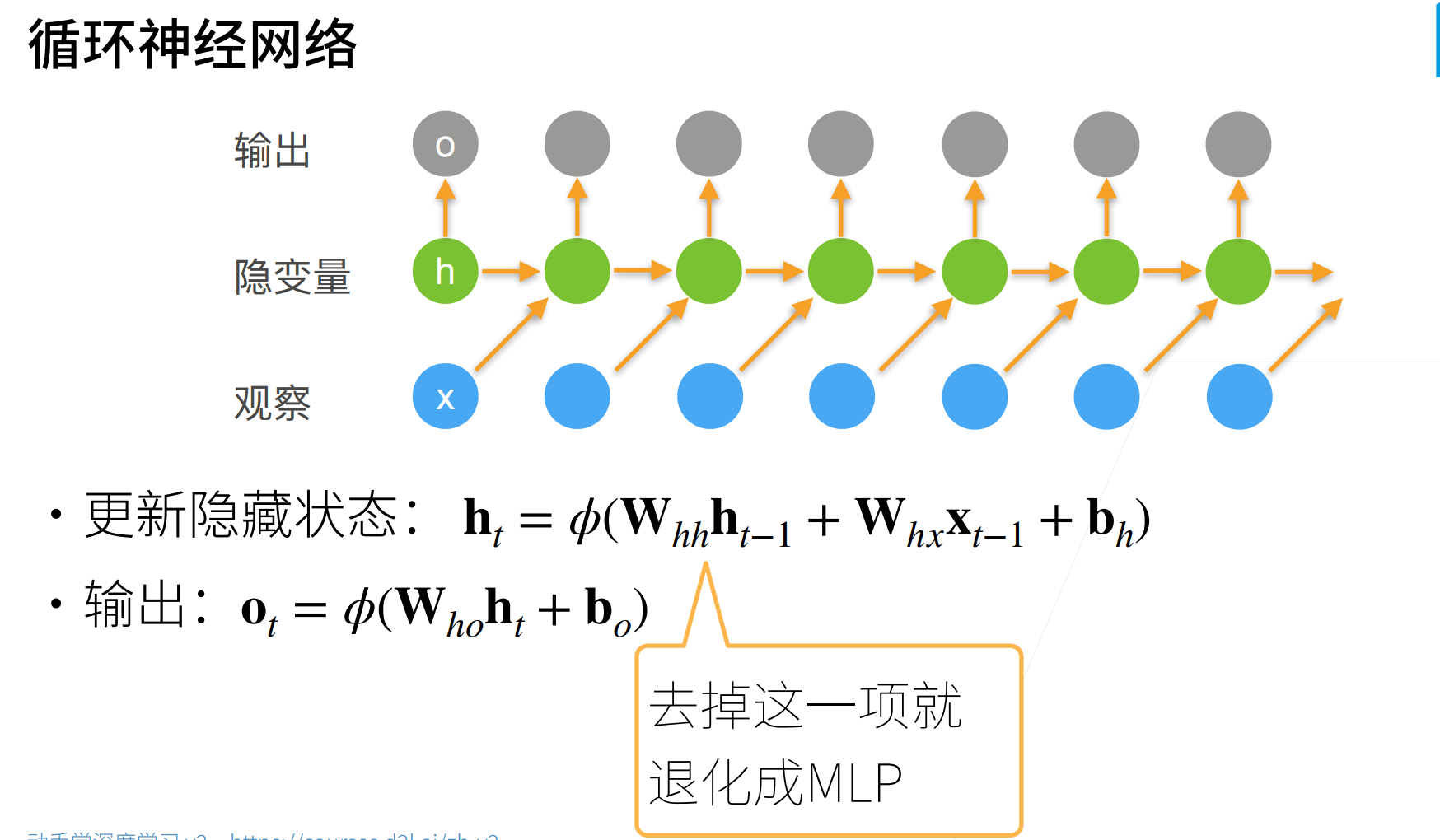
首先使用(x_{t-1})去更新隐藏状态(h_t):(h_t=phi(W_{hh}h_{t-1}+W_{hx}x_{t-1}+b_h))
然后在由这个更新的隐藏状态去预测当前时刻的输出:(o_t=phi(W_{ho}h_t+b_o))
def rnn(inputs, state, params):
W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs: # 按照时间维度进行迭代
# 这里就是将隐藏状态和输入的X进行加法
H = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)
Y = torch.mm(H, W_hq) + b_q
outputs.append(Y)
# 在竖直方向将这些输出拼接,并返回隐藏状态
return torch.cat(outputs, dim=0), (H,)

注意:slides上面的(x_{t-1})其实应该是(x_t),这里写成前者只是为了强调是输入前一个字符,可以预测出后一个字符(预测的字符是还没有输入的)。
RNN和MLP的的差别就是多了一个时间轴,意思就是其实去除了隐藏状态(W_{hh}h_{t-1})就是一个MLP。
最简单的RNN是通过(W_{hh})来存储时序信息的,所以RNN跟MLP相比,就是使用多了一维权重来存储时序信息。
好像下图,最简单的RNN是通过(W_{hh})来存储时序信息的。


另外就是我们如何衡量一个语言模型的好坏?语言模型说白了就是一个分类模型,假设字典的大小为m,那么就可以看做是一个m分类的问题。如果是一个分类问题,当然你是可以用交叉熵来做这个事情。
现在序列的长度为n,那么就要做n次预测,也就做n次分类,那么衡量一个语言模型的好坏就取一个平均,n次交叉熵的平均。
但是由于历史原因,对这个平均交叉熵进行了指数处理(exp(pi)),叫做困惑度。
困惑度为1表示完美,无穷大是最坏的情况。


RNN具体来讲是一个隐变量模型,它告诉你说隐变量是一个向量,然后它的向量是怎么样去更新的,说白了就是一个全连接层。
困惑度,就是把RNN作为分类问题来处理,一个序列长度为n,字典容量为m,那么就预测n次,然后取平均的交叉熵损失,在取指数,就得到了困惑度。
QA
- 循环神经网络和递归神经网络是一个东西吗?如果不是,有什么区别吗?
他们不是一个东西。这里没有讲递归神经网络,递归神经网络可以做的更加fancy一点。但是RNN只能处理一些很平整序列。
可以简单认为RNN就是一个简单的递归神经网络。
- 前面讲的目标检测,现在已经发展比较成熟了,一个人做的话,也不是很容易发paper,现在讲的自然语言处理方面,有哪些方向适合一个人做呀?
目标检测这个现在发paper很难,发很好的paper很难,图片分类发很好的paper也很难。
最近不是大家在用transformer来做图片分类,你也可以用transformer来做目标检测。
深度学习在2018年一直没有突破,直到那时候transformer的出现,transformer出来之后,NLP进展是非常的迅速。
CNN有段时间就是在把backbone刷的特别好,把pre-train模型刷的特别好;现在NLP在干吗呢?现在NLP也是在刷pre-train的模型。
你可以先看CNN在干什么,现在是backbone好了之后,就去刷应用,比如语义分割、目标检测。一个人是很难刷backbone的,因为这需要有很多的机器和很多的数据,如果你是一个人,可以用transformer去做一些偏应用的模型是会好一点的(其实还有最近一直很火的GNN)。
- 中文需不需要分词,可否直接基于字来做?
可以,但是分词是有好处的,因为token中是包含信息的。