单机多卡并行

这里图片是4张980,但是因为GPU靠的太近了,一个月后就烧了一块GPU。这是沐神第一次装多GPU犯的错误。


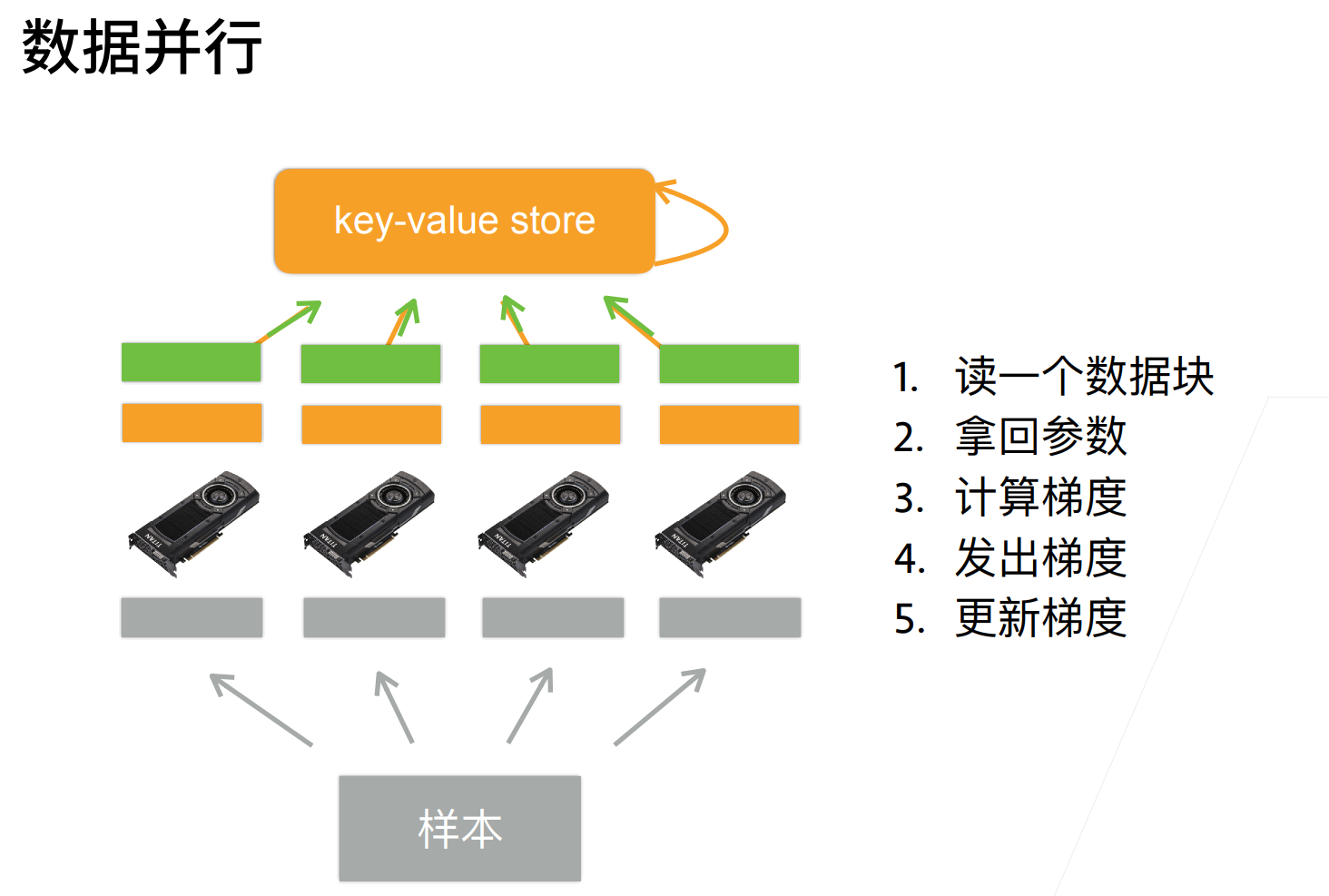
一般都是进行数据并行。
什么使用使用模型并行呢?就batch_size=1的时候,一个GPU都不能计算的话,那么就会考虑进行模型并行,将模型分割到多个GPU来做,比如transformer的模型直接有100个G。

QA
- 我在4块GPU训练,后来我有两块更大显存的GPU,那我什么都不变,换成2块显存的GPU训练,会有什么影响吗?
你可以每次分配多点数据给性能更好的GPU,一般框架也是允许这个操作的。
- 小批量分到多GPU计算后,模型结果怎么合到一块?
一般是说把梯度给加起来,梯度加起来之后就会得到完整梯度,在模型更新的时候,其实模型就只有一份,模型基本可以把保证是一致的。
- 数据并行的时候,不同gpu也是拷贝了同一个模型吗?那是不是数据并行才是真正的并行,模型并行只是模型切块,本质上还是串行。可以这么理解吗?
数据并行确实是在每张卡中拷贝同一个模型。
模型并行实际上也是并行,只不过并行的程度会低一些。