杂记索引:
1.关于unittest中的is_element_present函数该如何传参
2.关于网页上弹窗(alert)的处理
3.关于打印出当前正在执行的函数名称的方法
4.关于在原始网页上跳转后返回原网页的方法
5.关于断言assertEqual返回值报错:True != True
Expected :True
Actual :True
6.关于import其他文件夹中的py文件
7.关于文件相对路径的表达方式
8.关于配置文件的设置格式
9.关于获取web后端数据的方法
10.关于获取的json数据包含中文而显示uxxxx的解决
正文内容:
1.关于unittest中的is_element_present函数
1 def is_element_present(self, how, what): 2 """验证页面元素是否出现的工具函数""" 3 from selenium.common.exceptions import NoSuchElementException 4 try: 5 driver.find_element(by=how, value=what) 6 except NoSuchElementException as e: 7 return False 8 return True
这个函数多用于确认页面某个元素是否存在,而如果需要对比确认某元素的值是否为某值时,不适合用这个
在使用过程中,多次遇到“how”位置的参数不确定该填写哪些方式,参考了模块包中的响应信息源码(位置在)"安装环境Anacondalibsite-packagesseleniumwebdriver emotewebdriver.py", line 978,源码中的函数如下:
1 def find_element(self, by=By.ID, value=None): 2 """ 3 Find an element given a By strategy and locator. Prefer the find_element_by_* methods when 4 possible. 5 6 :Usage: 7 element = driver.find_element(By.ID, 'foo') 8 9 :rtype: WebElement 10 """ 11 if self.w3c: 12 if by == By.ID: 13 by = By.CSS_SELECTOR 14 value = '[id="%s"]' % value 15 elif by == By.TAG_NAME: 16 by = By.CSS_SELECTOR 17 elif by == By.CLASS_NAME: 18 by = By.CSS_SELECTOR 19 value = ".%s" % value 20 elif by == By.NAME: 21 by = By.CSS_SELECTOR 22 value = '[name="%s"]' % value 23 return self.execute(Command.FIND_ELEMENT, { 24 'using': by, 25 'value': value})['value']
分析可知,在使用之前需要导入模块包By,即 from selenium.webdriver.common.by import By
之后 “how”处可传参为By.ID,By.CSS_SELECTOR,By.TAG_NAME,By.CLASS_NAME,By.NAME (实际在使用时还可以用By.XPATH和LINK_TEXT)
简言之:
(1)先导入所需的By模块包
(2)再写入is_element_present函数,最后调用即可
2.关于网页上弹窗(alert)的处理
参考了博客文章:https://www.cnblogs.com/101718qiong/p/8027944.html
简言之:
(1)先导入弹窗处理模块 from selenium.webdriver.support import expected_conditions as EC
(2)再写函数代码如下,来使用
1 alert = EC.alert_is_present()(driver) 2 if alert: 3 print("出现弹窗提示:%s "%alert.text) 4 alert.accept() 5 print("点击确认,进行下一步") 6 else: 7 print("未出现弹窗")
3.关于打印出当前正在执行的函数名称的方法
简言之:
(1)先导入所需的模块包: import sys
(2)在所需位置插入语句 print(" 当前执行函数名:%s " % sys._getframe().f_code.co_name) 即可
4.关于在原始网页上跳转后返回原网页的方法
即当在第一个网页上点击某元素后,并未打开新的网页而是在原有网页的基础上跳转了的情况,就不能使用窗口句柄返回原网页了
简言之:
在原有网页上发生跳转后,返回操作前的页面使用:driver.back()
5.关于断言assertEqual返回值报错:
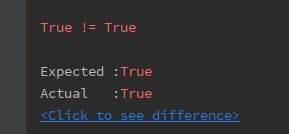
当返回结果为布尔值时,最好换一个断言方式,用assertTrue,下方图片是断言值适应类型:
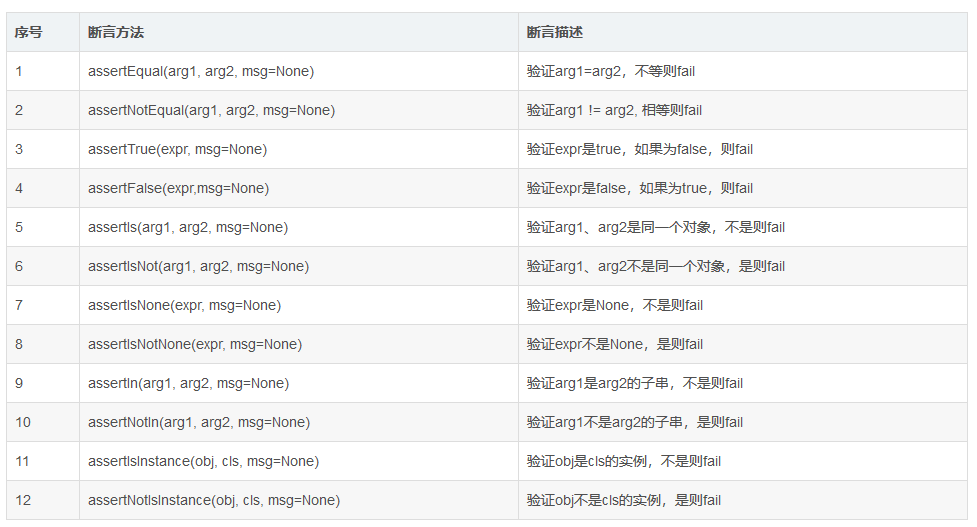
因此,如果要使用断言,优先考虑适配的断言方法,否则可能出现难以理解的报错
6.关于import其他文件夹中的py文件
在引用目标文件所在的文件夹中新建一个__init__.py文件(内容可为空),然后再from 文件夹名字(这里的名字是所在文件夹的上一级文件夹名) import 文件名
7.关于文件相对路径的表达方式
../ 表示当前文件所在的目录的上一级目录
./ 表示当前文件所在的目录(可以省略)
/ 表示当前站点的根目录(域名映射的硬盘目录)
8.关于配置文件的设置
1 """配置文件书写形式如下,一般命名为config.ini""" 2 3 [Default] 4 url=xxxxxxxxx 5 driver=firefox 6 URL_test=xxxxxxxxx 7 8 [LoginData] 9 username=admin 10 usernamenull= 11 usernamewrong=admin1 12 userpw=123 13 userpwwrong=123456 14 userpwnull=
1 """配置文件的使用""" 2 import configparser 3 4 conf = configparser.ConfigParser() 5 conf.read("相对路径配置文件名") 6 7 url = conf.get("Default","url") 8 name = conf.get("LoginData","username") 9 password = conf.get("LoginData","userpw")
9.关于获得web后端数据的方法
在web页面中,通过F12调出开发者工具后,在“网络”中,可以找到后端传来的如下内容
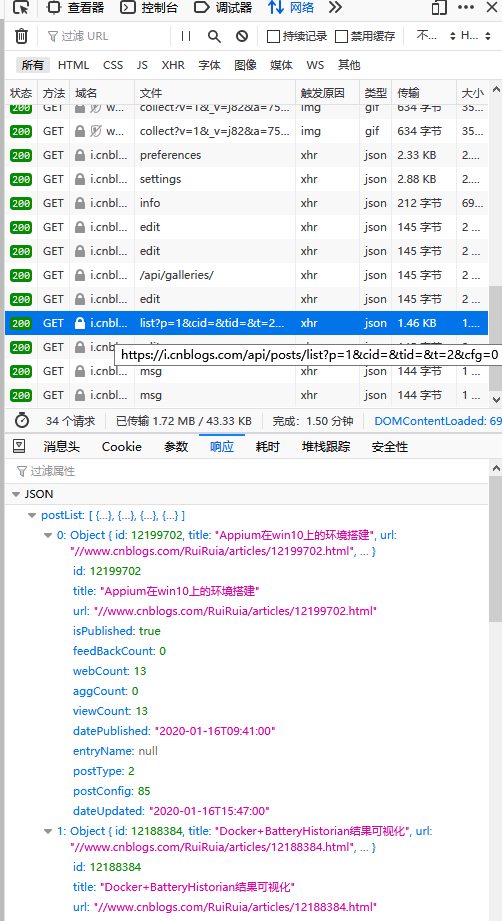
如果想要获取这些响应内容,方法如下:
1 def get_Ajax(self,base_url): 2 """Get the data transmitted asynchronously by the backend, the return value is a list containing all the data information""" 3 """base_url:the request url,change it you could get any other ajax part you need""" 4 5 try: 6 cookielist = self.driver.get_cookies() 7 for cookiedict in cookielist: 8 if cookiedict['name'] == 'CiSession': 9 cookievalue = cookiedict['value'] 10 else: 11 pass 12 cookie = "testcookie=yes;CiSession=" + cookievalue 13 header = { 14 'User-Agent':"根据自己的网页浏览器情况修改", 15 'Cookie': cookie, 16 } 17 18 response = requests.get(base_url,headers=header) 19 Ajax_list = response.json() 20 return Ajax_list 21 22 except requests.ConnectionError as e: 23 self.log("--ERROR--:", e.args)
其中base_url就是上上张图片中的“文件”名,并且通过这种方式也避免了cookie过期的情况。
10.关于获取的json数据包含中文而显示uxxxx的解决
在获取的json数据中添加参数:
json.dumps(jsondata,ensure_ascii=False,indent=4)
其中的indent参数表示转换后缩进为4,这样显得数据整洁好看