我爬取的是新浪新闻,打开网页链接http://news.sina.com.cn/china/:
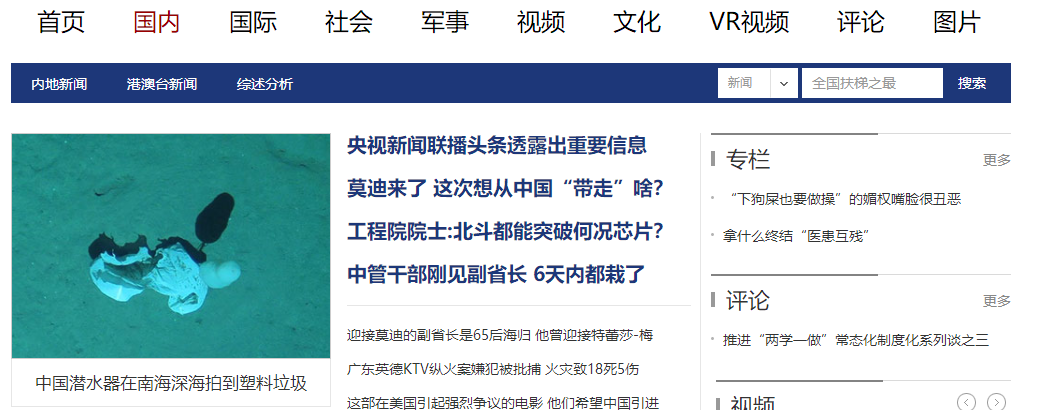
打开网页获取需要的链接: ,然后开始做项目。
,然后开始做项目。
1,获取评论数:
def getCommentsCounts(newsurl):
bianhao = re.search('doc-i(.+).shtml', newsurl)
newsid=bianhao.group(1)
comment=requests.get(commentURL.format(newsid))
jd = json.loads(comment.text)
counts=jd['result']['count']['total']
return counts
2 获取新闻内容:
def getNewsDetail(newsurl):
result = {}
res=requests.get(newsurl)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
# 获取标题
result['title']=soup.select(".main-title")[0].text
# 来源
result['newssources'] = soup.select('.source')[0].text
# 时间
result['timesource'] = soup.select('.date')[0].text
# 编辑
result['editor']=soup.select('.show_author')[0].text.strip('责任编辑:')[-1]
# 评论数
result['comments']=getCommentsCounts(url)
# 内容
result['contents']= soup.select('.article')[0].text.strip()
# writeNewsContent(content)
return str(result['contents'])
3 保存为txt:
def writeNewsContent(content):
f=open('news.txt','a',encoding='utf-8')
f.write(content)
f.close()
得到txt文本:
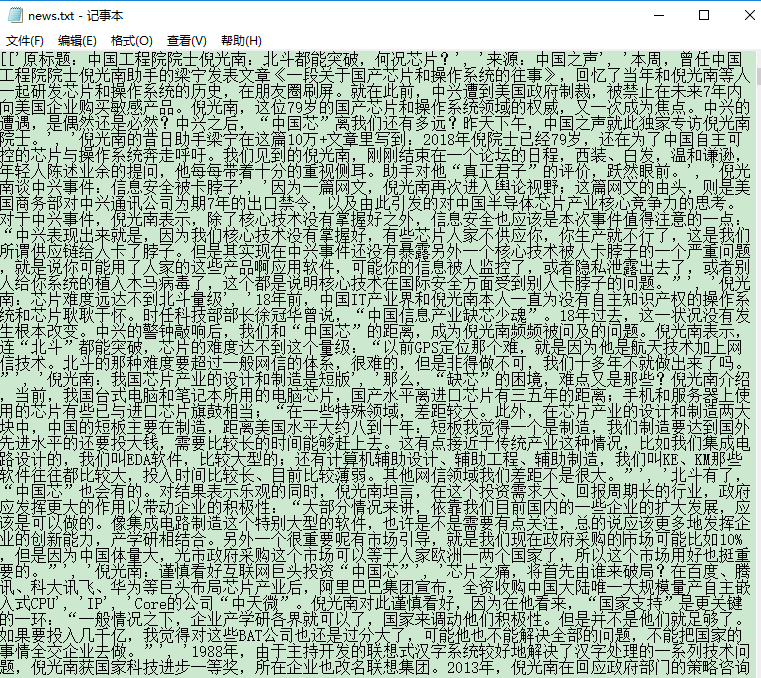
4 词频分析并生成词云:
for c in sep:
news = news.replace(c, ' ')
wordList = list(jieba.cut(news))
wordDict = {}
words = list(set(wordList) - exclude)
for w in range(0, len(words)):
wordDict[words[w]] = news.count(str(words[w]))
dictList = list(wordDict.items())
dictList.sort(key=lambda x: x[1], reverse=True)
cy = {}
f = open('news.txt', 'a', encoding="utf-8")
for i in range(1000):
print(dictList[i])
f.write(dictList[i][0] + ':' + str(dictList[i][1]) + '
')
cy[dictList[i][0]] = dictList[i][1]
f.close()
font = r'C:WindowsFontswb.ttf'
image = Image.open('./wordcloud.jpg')
graph = np.array(image)
wc = WordCloud(font_path=font, background_color='White', max_words=50, mask=graph)
wc.generate_from_frequencies(cy)
image_color = ImageColorGenerator(graph)
plt.imshow(wc)
plt.axis("off")
plt.show()
得到词云图片:

在做大作业的过程中,遇到的主要问题还是在安装wordcloud上,出现了Fatal error in launcher: Unable to create process using '"'的问题,当然不止这个问题,只是最后才找到这个关键的问题,这个问题后来困扰了我两天时间,于是我开始了与wordcloud的对抗。查了各种资料,最后终于在一篇博文(https://blog.csdn.net/testcs_dn/article/details/54176504)上找到了解决这个问题的答案。先升级pip,嗯,第一遍不知道为啥不成功,还好又试了一个,很好,成功了。
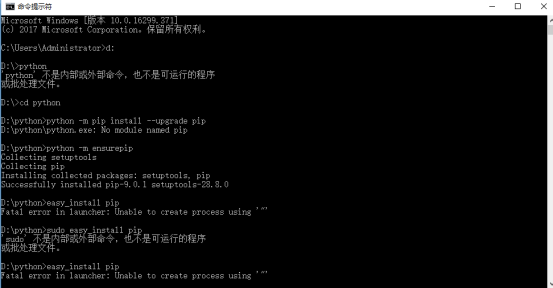
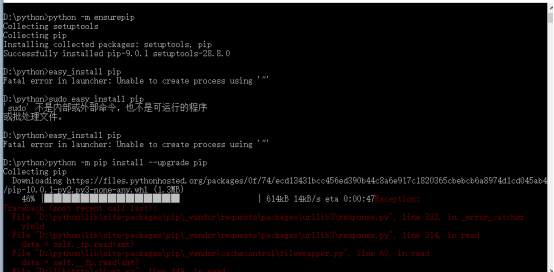
然后,就下载whl,接着安装,这里就不说了哈,百度上有。最后贴上代码:。
大作业代码:
import requests
import json
import re
from bs4 import BeautifulSoup
import jieba
# 获取评论数
def getCommentsCounts(newsurl):
bianhao = re.search('doc-i(.+).shtml', newsurl)
newsid=bianhao.group(1)
comment=requests.get(commentURL.format(newsid))
jd = json.loads(comment.text)
counts=jd['result']['count']['total']
return counts
def getNewsDetail(newsurl):
result = {}
res=requests.get(newsurl)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
# 获取标题
result['title']=soup.select(".main-title")[0].text
# 来源
result['newssources'] = soup.select('.source')[0].text
# 时间
result['timesource'] = soup.select('.date')[0].text
# 编辑
result['editor']=soup.select('.show_author')[0].text.strip('责任编辑:')[-1]
# 评论数
result['comments']=getCommentsCounts(url)
# 内容
result['contents']= soup.select('.article')[0].text.strip()
# writeNewsContent(content)
return str(result['contents'])
# 保为 txt
def writeNewsContent(content):
f=open('news.txt','a',encoding='utf-8')
f.write(content)
f.close()
def parseListLinks(url):
newsdetails=[]
res=requests.get(url)
jss = res.text.lstrip(' newsloadercallback(').rstrip(');')
jd = json.loads(jss)
for news in jd['result']['data']:
allURL=news['url']
newsdetails.append(getNewsDetail(allURL).split())
writeNewsContent(str(newsdetails))
return newsdetails
commentURL = 'http://comment5.news.sina.com.cn/page/info?version=1
&format=json&channel=gn&newsid=comos-{}&group=undefined&
compress=0&ie=utf-8&oe=utf-8&page=1&page_size=3'
url='http://news.sina.com.cn/c/zj/2018-04-20/doc-ifzihneq2559172.shtml'
listURL='http://api.roll.news.sina.com.cn/zt_list?channel=news&cat_1=gnxw&cat_2==gdxw1||=gatxw||=zs-pl||=mtjj&level==1||=2&show_ext=1&show_all=1&show_num=22&tag=1&format=json&page={}&
callback=newsloadercallback&_=1524705663198'
news_total=[]
for i in range(1,2):
newssurl=listURL.format(i)
newsary=parseListLinks(newssurl)
news_total.extend(newsary)
print(len(news_total))
import jieba
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
f = open('content.txt', 'r', encoding='utf-8')
news = f.read()
f.close()
sep = ''',。‘’“”:;()!?、《》[] '''
exclude = {'的','下','中','就','是','■'}
jieba.add_word('中国芯')
jieba.add_word('倪光南')
jieba.add_word('梁宁')
jieba.add_word('沈静文')
jieba.add_word('宋爽')
jieba.add_word('冯志远')
jieba.add_word('霍宇昂')
jieba.add_word('杨冠宇')
jieba.add_word('杨渡')
for c in sep:
news = news.replace(c, ' ')
wordList = list(jieba.cut(news))
wordDict = {}
words = list(set(wordList) - exclude)
for w in range(0, len(words)):
wordDict[words[w]] = news.count(str(words[w]))
dictList = list(wordDict.items())
dictList.sort(key=lambda x: x[1], reverse=True)
cy = {}
f = open('news.txt', 'a', encoding="utf-8")
for i in range(1000):
print(dictList[i])
f.write(dictList[i][0] + ':' + str(dictList[i][1]) + '
')
cy[dictList[i][0]] = dictList[i][1]
f.close()
font = r'C:WindowsFontswb.ttf'
image = Image.open('./wordcloud.jpg')
graph = np.array(image)
wc = WordCloud(font_path=font, background_color='White', max_words=50, mask=graph)
wc.generate_from_frequencies(cy)
image_color = ImageColorGenerator(graph)
plt.imshow(wc)
plt.axis("off")
plt.show()
词云底片:

生成的词云: