@by Ruth92(转载请注明出处)
第6章 理解 Buffer
✁ 为什么需要 Buffer?
在 Node 中,应用需要处理网络协议、操作数据库、处理图片、接收上传文件等,在网络流和文件的操作中,还要处理大量二进制数据,JavaScript 自由的字符串远远不能满足这些需求,于是 Buffer 对象应运而生。
✁ 字符串与 Buffer 的区别
Buffer 是二进制数据,字符串与 Buffer 之间存在编码关系。
一、Buffer 结构
Buffer 是一个像 Array 的对象,但它主要用于操作字节。
-
模块结构
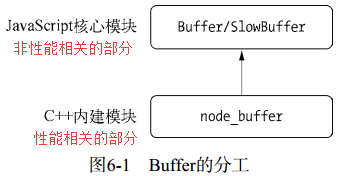
Buffer所占用的内存不是通过 V8 分配的,属于堆外内存。由于
Buffer太过常见,Node 在进程启动时就已经加载了它,并将其放在全局对象(global)上。所以在使用Buffer时,无需通过require()即可直接使用。 -
Buffer 对象
Buffer对象类似于数组,它的元素为16进制的两位数,即 0-255 的数值。var str = '深入浅出Node.js'; var buf = new Buffer(str, 'utf-8'); // 不同的编码的字符串占用的元素个数各不相同 // 中文字在 UTF-8 编码下占用3个元素,字母和半标点符号占用1个元素 buf; // => <Buffer e6 b7 b1 e5 85 a5 e6 b5 85 e5 87 ba 6e 6f 64 65 2e 6a 73> // Buffer 受 Array 类型的影响很大, // 可以访问 length 属性得到长度,也可以通过下标访问元素 buf.length; // => 19 buf[10]; // => 135 var newBuf = new Buffer(100); newBuf.length; // => 100 newBuf[10]; // => 88 (元素值是一个 0-255 的随机值) // 如果给元素赋值不是0-255的数时: // 给元素的赋值如果小于0,就讲该值逐次加256,直到得到0-255区间内的整数 newBuf[20] = -100; newBuf[20]; // => 156 // 给元素的赋值如果大于0,就逐次减256,直到得到0-255区间内的整数 newBuf[21] = 300; newBuf[21]; // => 44 // 如果是小数,舍弃小数部分,只保留整数部分 newBuf[22] = 3.1415; newBuf[22]; // 3 -
Buffer 内存分配
Buffer对象的内存分配不是在 V8 的堆内存中,而是在 Node 的 C++ 层面实现内存的申请的。Node 在内存的使用上应用的是在 C++ 层面申请内存、在 JavaScript 中分配内存的策略。
【小结】:
- 真正的内存是在 Node 的 C++ 层面提供的,JavaScript 层面只是使用它。
- 当进行小而频繁的
Buffer操作时,采用 slab 的机制进行预先申请和事后分配,使得 JavaScript 到操作系统之间不必有过多的内存申请方面的系统调用。 - 对于大块的
Buffer而言,则直接使用 C++ 层面提供的内存,而无需细腻的分配操作。
二、Buffer 的转换
Buffer 对象可以与字符串之间相互转换。目前支持的字符串编码类型有:ASCII、UTF-8、UTF-16LE/UCS-2、Base64、Binary、Hex。
-
字符串转 Buffer
字符串转
Buffer对象主要是通过 构造函数 完成的。new Buffer(str, [encoding]);通过构造函数转换的
Buffer对象,存储的只能是一种编码类型。encoding参数不传递时,默认按 UTF-8 编码进行转码和存储。一个
Buffer对象可以存储不同编码类型的字符串转码的值,调用write()方法可以实现。buf.write(string, [offset], [length], [encoding]);由于可以不断写入内容到
Buffer对象中,并且每次写入可以指定编码,所以Buffer对象中可以存在多种编码转化后的内容。需要小心的是,每种编码所用的字节长度不同,将Buffer反转回字符串时需要谨慎处理。 -
Buffer 转字符串
Buffer对象的toString()可以将Buffer对象转换为字符串。buf.toString([encoding], [start], [end]); -
Buffer 不支持的编码类型
isEncoding()方法:判断编码是否支持转换Buffer.isEncoding(encoding); Buffer.isEncoding('utf-8'); // true Buffer.isEncoding('GBK'); // false对于不支持的编码类型,可以借助 Node 生态圈中的模块完成转换。iconv 和 iconv-lite 两个模块可以支持更多的编码类型转换。
三、Buffer 的拼接
Buffer 在使用场景中,通常是以一段一段的方式传输。
var fs = require('fs');
var rs = fs.createReadStream('test.md');
var data = '';
rs.on('data', function(chunk) {
// data 事件中获取的 chunk 对象即是 Buffer 对象
// 隐藏了 toString() 操作
// 等价于:data = data.toString() + chunk.toString();
data += chunk;
});
rs.on('end', function() {
console.log(data);
});
-
乱码是如何产生的
toString()默认以 UTF-8 编码,中文在该编码方式下占3个字节,因此,对于宽字节的中文,会形成问题。// 将文件可读流的每次读取的 Buffer 长度限制为 11 var rs = fs.createReadStream('test.md', {highWaterMark: 11}); // => 窗前明◆◆◆光,疑◆◆◆地上霜✎ 第一个 Buffer 对象在输出时,只能显示3个字符,Buffer 中剩下的2个字节将会以乱码的形式显示。第二个Buffer对象的第一个字节也不能形成文字,只能显示乱码。
☁ 对于任意长度的
Buffer而言,宽字节字符串都有可能存在被截断的情况,只不过Buffer的长度越大出现的概率越低而已。 -
setEncoding() 与 string_decoder() ☛ 不能从根本上解决乱码问题
◐
setEncoding方法:设置编码【作用】:让 data 事件中传递的不再是一个
Buffer对象,而是编码后的字符串。readable.setEncoding(encoding); var rs = fs.createReadStream('test.md', {highWaterMark: 11}); rs.setEncoding('utf8'); // => 窗前明月光,疑是地上霜如论如何设置编码,触发 data 事件的次数依旧相同,即意味着设置编码并未改变按段读取的基本方式。
在调用
setEncoding()时,可读流对象在内部设置了一个decoder对象。◑
decoder对象:来自于string_decoder模块StringDecoder的实例对象,最终解决乱码问题。// decoder 的神奇原理: var StringDecoder = require('string_decoder').StringDecoder; var decoder = new StringDecoder('utf8'); var buf1 = new Buffer([0xE5, 0xBA, 0x8A, 0xE5, 0x89, 0x8D, 0xE6, 0x98, 0x8E, 0xE6, 0x9C]); console.log(decoder.write(buf1)); // => 床前明 var buf2 = new Buffer([0x88, 0xE5, 0x85, 0x89, 0xEF, 0xBC, 0x8C, 0xE7, 0x96, 0x91, 0xE6]); console.log(decoder.write(buf2)); // => 月光,疑虽然
string_decoder模块很奇妙,但是它也并非万能药,它目前只能处理 UTF8、Base64 和 UCS-2/UTF-16LE 这3种编码。所以,通过setEncoding()的方式不可否认能解决大部分的乱码问题,但并不能从根本上解决该问题。 -
正确拼接 Buffer
① 用一个数组来存储接收到的所有
Buffer片段并记录下所有片段的总长度;② 调用
Buffer.concat()方法生成一个合并的Buffer对象。var chunks = []; var size = 0; rs.on('data', function(chunk) { chunks.push(chunk); size += chunk.length; }); rs.on('end', function() { var buf = Buffer.concat(chunks, size); var str = iconv.decode(buf, 'utf8'); console.log(str); });Buffer.concat()方法封装了从小Buffer对象向大Buffer对象的复制过程:Buffer.concat = function(list, length) { if (!Array.isArray(list)) { throw new Error('Usage: Buffer.concat(list, [length]'); } if (list.length === 0) { return new Buffer(0); } else if (list.length === 1) { return list[0]; } if (typeof length !== 'number') { length = 0; for (var i = 0; i < list.length; i++) { var buf = list[i]; length += buf.length; } } var buffer = new Buffer(length); var pos = 0; for (var i = 0; i < list.length; i++) { var buf = list[i]; buf.copy(buffer, pos); pos += buf.length; } return buffer; }
四、Buffer 与性能
-
Buffer在文件 I/O 和网络 I/O 中运用广泛。-
在应用中:操作字符串;
-
在网络中传输:需要转换为
Buffer,以进行二进制数据传输。
-
-
在 Web 应用中,字符串转换到
Buffer是时时刻刻发生的,提高字符串到Buffer的转换效率,可以很大程度地提高网络吞吐率。 -
Buffer的使用除了与字符串的转换有性能损耗外,在文件的读取时,有一个highWaterMark设置对性能的影响至关重要。- highWaterMark 设置对
Buffer内存的分配和使用有一定影响; - highWaterMark 设置过小,可能导致系统调用次数过多;
- highWaterMark 的值越大,读取速度越快。
- highWaterMark 设置对