PyTorch随手记
Note:
-
官方书籍:Deep learning with PyTorch。
1. 模型操作
假设我们有一个用self.arcnn = nn.Sequential(...)定义并训练好的ARCNN模型。我们想迁移过来,冻结前几层再训练。分两步:
-
print(model.state_dict())查看名称,如'arcnn.12.bias', 'arcnn.12.weight'等。 -
model.arcnn[0].weight.requires_grad = False,model.arcnn[0].bias.requires_grad = False,让第一层冻结。
2. 网络设计
卷积图示
填充(padding)
PyTorch和TensorFlow的填充规则是不同的。因此必须查阅官方文档。
如果y = F.pad(x, (1,2,3,4)),意思是:在(x)的最后一个维度上(一般是W),左边填一圈零,右边填两圈0(默认为0);在(x)的倒数第二个维度上(一般是H),上面填3圈零,下面填4圈零。
升采样
其中有一个参数align_corners。例子参见官方教程里的Example。
这里有一个图例:
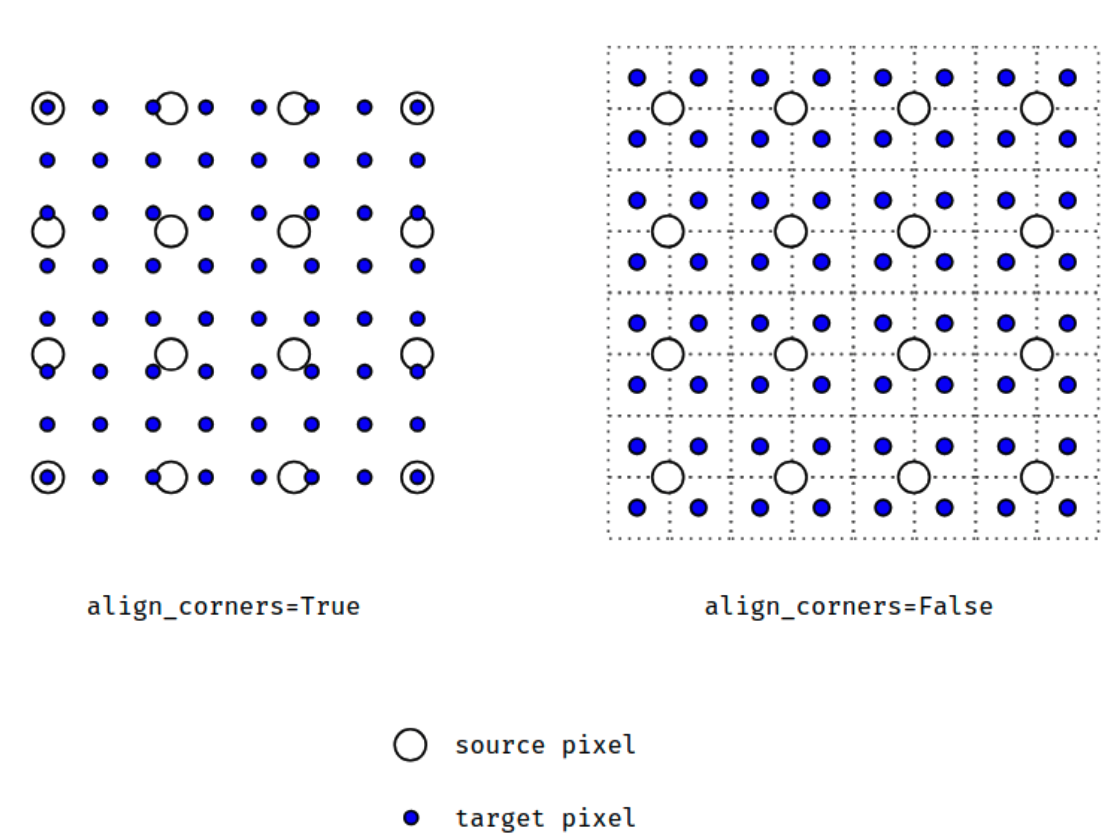
全连接层
假设我们经过多层卷积,得到了((128, 32, 4, 4))的通道,即batch size为128,32张特征图,通道尺寸为(4 imes 4)。我们希望基于此得到2分类。那么可以如下操作:
self.l1 = nn.Linear(32 * 4 * 4, 128)
self.l2 = nn.Linear(128, 32)
self.l3 = nn.Linear(32, 2)
x = x.view(-1, 32 * 4 * 4)
x = self.l1(x)
x = self.l2(x)
x = self.l3(x)
关于交叉熵和softmax,参见损失函数。
3. 损失函数
交叉熵
loss_func = F.cross_entropy
batch_pred_t = model(batch_cmp_t)
batch_pred = batch_pred_t.detach().cpu()
acc = cal_acc(batch_pred, batch_label)
def cal_acc(batch_pred, batch_label):
batch_pred = [torch.argmax(batch_pred[ite_patch]) for ite_patch in range(batch_size)]
acc = 0
for ite_patch in range(batch_size):
if pred[ite_patch] == batch_label[ite_patch]:
acc += 1
acc /= batch_size
return acc
注意:
-
cross_entropy函数结合了nn.LogSoftmax()和nn.NLLLoss()。 -
第二个参数是
target。假设batch size是32,那么就是一个32维向量(张量),值为从0开始的正确标签。 -
第一个参数是
input,可以没有被softmax归一化。假设batch size是32,一共有5个分类,那么就是一个(32 imes 5)的张量。
4. 系统或环境交互
模型加载
自动搜索空余显存最多的GPU,然后将模型加载到该GPU上:
os.system('nvidia-smi -q -d Memory |grep -A4 GPU|grep Free >tmp')
memory_gpu=[int(x.split()[2]) for x in open('tmp','r').readlines()]
dev = torch.device("cuda:" + str(np.argmax(memory_gpu)))
print(dev)
model.load_state_dict(torch.load(os.path.join(dir_model, "model_" + str(index_model) + ".pt"), map_location=dev))
model.to(dev)
5. 犯过的错误
损失异常
- CNN最后一层使用了非线性激活函数ReLU,导致输出在0附近浮动。
测试显存过大
在测试程序中指定了torch.no_grad(),然而显存还是过大。后来改成with torch.no_grad():包裹测试程序,成功了。