分布式计算:
原则:移动计算而尽可能减少移动数据(减少网络开销)
分布式计算其实就是将单台机器上的计算拓展到多台机器上并行计算。
MapReduce是一种编程模型。Hadoop MapReduce采用Master/slave 结构。只要按照其编程规范,只需要编写少量的业务逻辑代码即可实现一个强大的海量数据并发处理程序。核心思想是:分而治之。Mapper负责分,把一个复杂的业务,任务分成若干个简单的任务分发到网络上的每个节点并行执行,最后把Map阶段的结果由Reduce进行汇总,输出到HDFS中,大大缩短了数据处理的时间开销。MapReduce就是以这样一种可靠且容错的方式进行大规模集群海量数据进行数据处理,数据挖掘,机器学习等方面的操作。
MapReduce分布式计算框架体系结构
首先理解几个概念:
Master:是整个集群的唯一的全局管理者,功能包括:作业管理、状态监控和任务调度等,即MapReduce中的JobTracker
slave:负责任务的执行和任务状态回报,即MapReduce中的TaskTracker
Job&Task:在hadoop mapreduce中,一个 Job 它是一个任务,主业务。一个Job 可以拆分成多个Task,map Task与reduce Task。
JobTracker:JobTracker是一个后台服务进程,启动之后,会一直监听并接收来自各个TaskTracker发送的心跳信息,包括资源使用情况和任务运行情况等信息
JobTracker的主要功能:
作业控制:在hadoop中每个应用程序被表示成一个作业,每个作业又被分成多个任务,JobTracker的作业控制模块则负责作业的分解和状态监控。
最重要的状态监控:主要包括TaskTracker状态监控、作业监控和任务状态监控。主要作用:容错和为任务调度提供决策依据。
资源管理。
TaskTracker:TaskTracker是JobTracker和Task之间的桥梁:一方面,从JobTracker接收并执行各种命令:运行任务、杀死任务等;另一方面讲本地节点上各个任务状态通过心跳周期性汇报给JobTracker。TaskTracker与JobTracker和Task之间采用了RPC协议进行通信。
TaskTracker的功能:
汇报心跳:Tracker周期性讲所有节点上各种信息通过心跳机制汇报给JobTracker。这些信息包括两部分:
*机器级别信息:节点健康情况,资源使用情况等。
*任务级别信息:任务执行进度、任务运行状态等。
执行命令:JobTracker会给TaskTracker下达各种命令,主要包括:启动任务(LaunchTaskAction)、提交任务(CommunitTaskAction),杀死任务(KillJobAction)和重新初始化(TaskTrackerReinitAction)。
MapReduce体系结构里有两类节点,第一个是JobTracker,它是一个master管理节点,另一个是TaskTracker。客户端(Client)提交一个任务(Job),JobTracker把他提交到候选列队里,将Job拆分成map任务(Task)和reduce任务(Task),把map任务和reduce任务分给TaskTracker执行。在mapreduce编程模型里,Task一般起在和DataNode所在的同一台物理机上。如下图(图片来自网络):
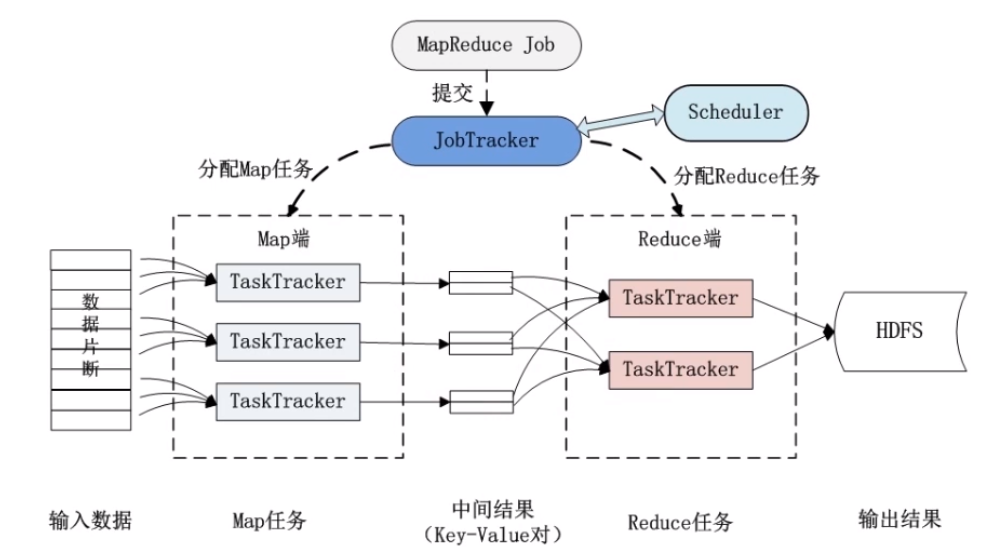
MapReduce分布式工作流程
1.分布式的运算程序往往需要分成至少2个阶段
MapReduce的第一阶段是Map,运行的实例叫Map Task,第二阶段是Reduce,运行的实例叫Reduce Task。每个Task只需要完成后把文件输出到自己的工作目录即可。
2.第一阶段的Task并发实例各司其职,各自为政,互不相干,完全并行
3.第二阶段的Task并发实例互不相干,但是他们的数据以来于上一阶段的所有Task并发实例的输出
4.MapReduce编程模型,只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能来多个mapreduce程序,串行运行
MapReduce容错机制
MapReduce的第一阶段是Map,运行的实例叫Map Task,第二阶段是Reduce,运行的实例叫Reduce Task。第二阶段Reduce要等第一阶段Map上的Map Task完成之后才能开始。如果Map Task运行失败,如何处理?
这时候就要启动mapreduce的容错机制了,它允许整个执行过程中TaskTracker中间出现宕机,发生故障,JVM发生重启等等这些情况,允许它出错。处理的方式:
1.重复执行
有可能是job本身问题,硬件问题,数据的问题都有可能,默认会重新执行,如果重新执行4次都失败就放弃执行。
2.推测执行
由于要Map端所有任务执行完才会执行reduce任务,可能存在某个节点完成的特别慢,JobTracker发现它很慢的时候,说明它出现了问题,另外找一台TaskTrack执行同一任务,哪个先完成就取该结果,结束另一个TaskTracker。
总结
以上知识体系基本能解决一下几个问题了:
1.你的MapTask如何进行任务分配?
3.MapTask和ReduceTask之间如何衔接?
4.如果某MapTask运行失败,如何处理?
master监控到有MapTask失败就会启动在另一台机器上启动maptask,主要由MapReduce容错机制处理。详情看上面的MapReduce容错机制。
5.mapreduce如果都需要自己自己负责输出的分区,很麻烦,所以有一个master管理,MapTask只需要把文件输出到自己的工作目录即可,ReduceTask执行时由master中的管理节点JobTracker把MapTask的资源调动给ReduceTask,发挥资源管理作用。
MapReduce运行的两种模式
MapReduce运行模式分为两种,本地模式和运行在yarn上
拓展:MapReduce的输出目录原则上是不能存在的,已经存在的话会报错。