一.首先来了解一下Java面向对象的五个程序设计方式:
1.万物皆对象
Java以类为基本模块来将问题抽象化,在计算机中解决实际生活中的问题
2.程序为对象的集合,程序中的类通过互发消息来告知彼此要做的
消息即为对一个类的方法的调用
3.每个对象都有其他对象构成的存储
在新建的类中可以包含一个以存在的类的对象,即组和实现代码复用
4.每个对象都有其类型
对象时某个类的实例,而类就是对象的类型
5.某一特定类型的对象可以接收同样的消息
通过继承来实现代码复用时,子类也继承了父类的成员变量和方法则子类也可以实现父类的方法
二.使用应用来操作对象
既然Java是面向对象的语言,那么Java通过什么来操作对象呢?
——Java通过引用来操作对象
打一个比方,如下:
Car car1=new Car();
那么在这里通过new这个关键字创造了一个Car类型的实例对象,那么car1就是引用。
通俗来讲就是你给你创造的对象起了个名字叫car1,你也可以叫它car2,这都无所谓,但是起名字必须要符合Java的命名标准:
1)、名称只能由字母、数字、下划线、$符号组成
2)、不能以数字开头
3)、名称不能使用JAVA中的关键字。
4)、在正规的大型项目中不能出现中文及拼音命名。(自己写小程序意淫当然没关系啦!)
同样的你也可以仅仅创造一个引用如下:
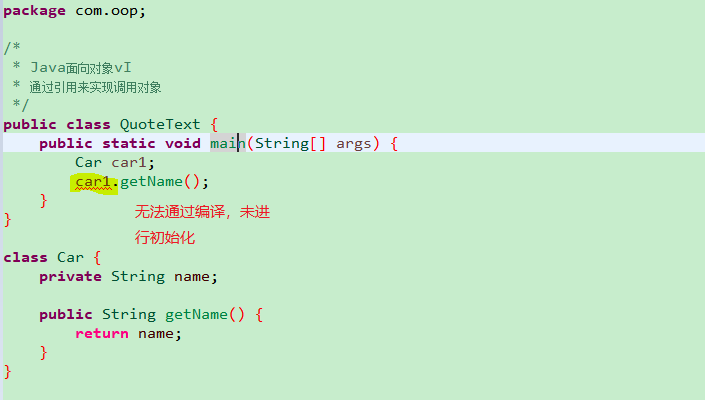
Car car1;
那么此时 你仅仅创建了一个引用没有创建对象,你对其采取任何一个方法调用都不会通过编译,(博主以为会通过编译,然后在运行时报出空指针异常,然而连编译期都通不过)
三.引用与对象存储到什么地方?
这部分需要深入Java虚拟机,在这里仅仅简单介绍,当博主深入学习JVM后在做详细介绍。
在这里仅仅理解两个JVM的部分:堆和栈
可以简单粗暴的理解为:栈是用来存储对象的引用的,而堆是来存储对象本身的
看图理解:
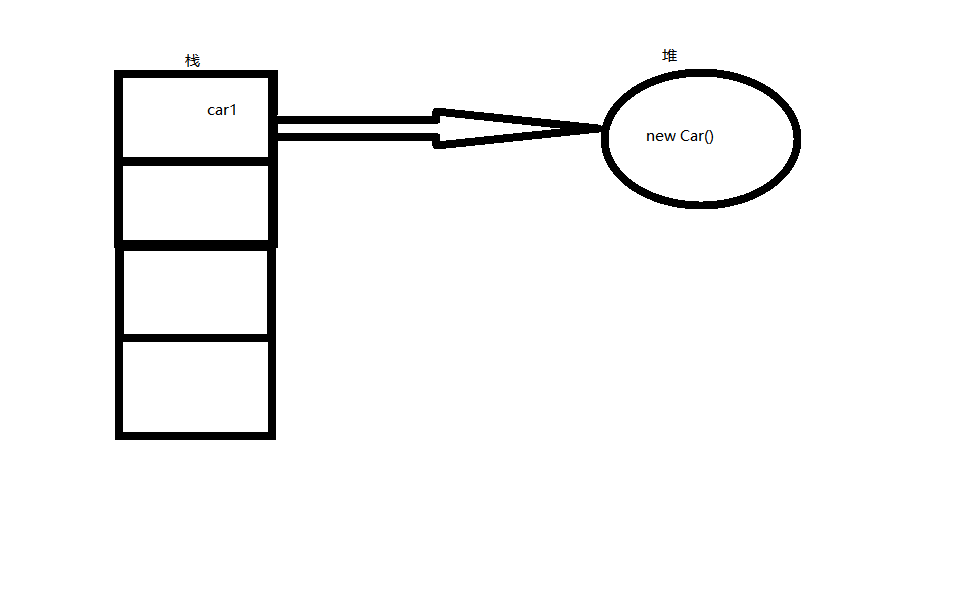
当你使用new关键字时就会在堆上开辟一个类的实例对象,而你取的“名字”也就是引用将在栈上指向对应的实例对象
那么执行方法本体的是堆里的对象,而不是栈里的对象引用,所以刚才的仅仅是创建了引用的car1调用方法,而无法通过编译就很好理解了。
在这里可能会有一个疑问Java的虚拟机为什么要将引用放在栈里将对象放在堆里呢?
首先对象本生大小是不可以估计的,而且其大小也是可以改变的所以对于 栈这种分配效率高但是灵活性低的存储区当然不适合,而堆灵活性较高,分配效率较低,并且编译器不需要知道存储的数据在堆里存活的时间。所以这样的存储模式也是十分合理的。
对于基本类型,如double、int等都是存放在栈中的。
因为基本类型的打内存大小是确定的,所以放在栈中可以使其效率更快。
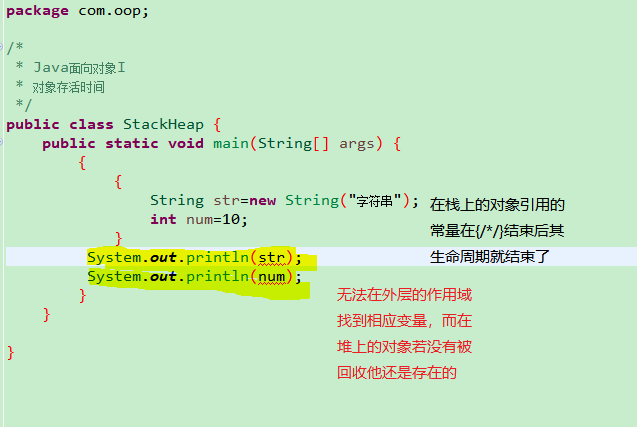
上面说到编译器不需要知道栈中对象的存在时间,而需要知道栈中对象存活的时间,下面可以看一个例子:
第一次发表文章,如有错误请斧正。