1.使用朴素贝叶斯模型对iris数据集进行花分类
尝试使用3种不同类型的朴素贝叶斯:
高斯分布型
from sklearn import datasets
iris = datasets.load_iris()
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()#建立模型
pred = gnb.fit(iris.data,iris.target) #拟合模型
y_pred = pred.predict(iris.data) #数据预处理
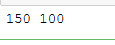
print(iris.data.shape[0],(iris.target != y_pred).sum())

多项式型
from sklearn import datasets
iris = datasets.load_iris()
from sklearn.naive_bayes import MultinomialNB
gnb = MultinomialNB()#建立模型
pred = gnb.fit(iris.data,iris.target) #拟合模型
y_pred = pred.predict(iris.data) #数据预处理
print(iris.data.shape[0],(iris.target != y_pred).sum())

伯努利型
from sklearn import datasets
iris = datasets.load_iris()
from sklearn.naive_bayes import BernoulliNB
gnb = BernoulliNB()#建立模型
pred = gnb.fit(iris.data,iris.target) #拟合模型
y_pred = pred.predict(iris.data) #数据预处理
print(iris.data.shape[0],(iris.target != y_pred).sum())
2.使用sklearn.model_selection.cross_val_score(),对模型进行验证。
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import cross_val_score
gnb = GaussianNB()
scores = cross_val_score(gnb,iris.data,iris.target,cv = 10)
print("Accuracy:%.3f"%scores.mean())

from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import cross_val_score
gnb = MultinomialNB()
scores = cross_val_score(gnb,iris.data,iris.target,cv = 10)
print("Accuracy:%.3f"%scores.mean())
from sklearn.naive_bayes import BernoulliNB
from sklearn.model_selection import cross_val_score
gnb = BernoulliNB()
scores = cross_val_score(gnb,iris.data,iris.target,cv = 10)
print("Accuracy:%.3f"%scores.mean())

3. 垃圾邮件分类
数据准备:
- 用csv读取邮件数据,分解出邮件类别及邮件内容。
- 对邮件内容进行预处理:去掉长度小于3的词,去掉没有语义的词等
尝试使用nltk库:
pip install nltk
import nltk
nltk.download
不成功:就使用词频统计的处理方法
训练集和测试集数据划分
- from sklearn.model_selection import train_test_split
import csv
file_path = r'F:SMSSpamCollectionjs.txt'
sms = open(file_path,'r',encoding = 'utf-8')
sms_data = []
sms_label = []
csv_reader = csv.reader(sms,delimiter = ' ') #用csv读取邮件数据
for line in csv_reader:
sms_label.append(line[0])
sms_data.append(line[1])
#sms_data.append(preprocessing(line[1]))
sms.close()
print(len(sms_label))
sms_label
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(sms_data,sms_label,test_size=0.3,random_state=0,stratify=sms_label)

from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df = 2,ngram_range=(1,2),stop_words='english',strip_accents='unicode',norm='l2')
x_train = vectorizer.fit_transform(x_train)
x_test = vectorizer.transform(x_test)
