最近在看关于哈希学习的几篇论文,下面利用博客记录一下阅读笔记和比较。
| 论文名字 | 论文出处 | 类型 | Hash function | Balance function | Optimization | loss function | pair |
| Supervised Hashing with Kernels | cvpr 2012 | Supervised | kernel function |
bit balance (哈希码平衡) |
Greedy+sigmoid Smoothng+RGD | |
pairwise |
| Top Rank Supervised Binary Coding for Visual Search | ICCV 2015 | Supervised | liner function | bit balance | tanh relaxation+SGD |
|
triplets |
| Towards Optimal Binary Code Learning via Ordinal Embedding | AAAI 2016 | Unsupervised | liner function |
bit uncorrelation (比特不相关) |
tanh relaxation+SGD | |
ordinal graph |

上图是几个哈希学习重要属性的比较,下面站在我的角度说说这三篇论文的一些思路和感想
一、首先是一篇老文章,2012年的cvpr的文章《Supervised Hashing with Kernels》,这篇文章还是有一定影响力的,我认为这篇文章最大的贡献就是将海明距离用编码的内积代替计算,并且跟相似矩阵很好的对应起来,这样大大减少了运算时间提高了效率。其实原理非常简单,就是利用了1和-1的加和性,再加上与相似矩阵适配。非常简单,非常巧妙。至于其他方面,它使用核方法代替了线性方法作为哈希函数,但好像不是这篇的原创。以及使用贪心算法逐位优化,这个思想可以学习。
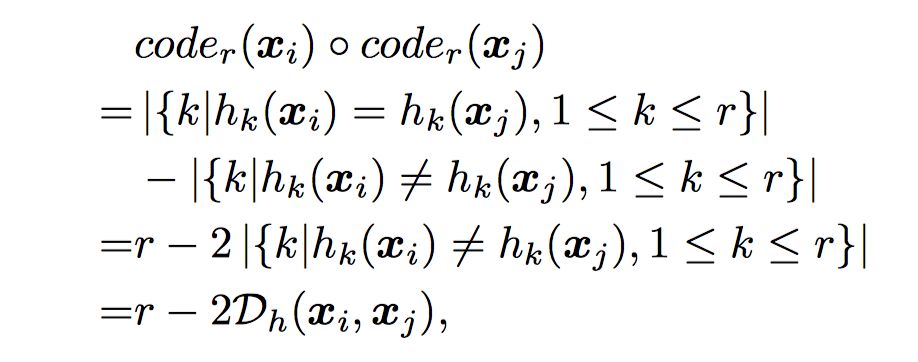
总结:从这篇文章我学习到了一种很好的思路,就是用编码的内积代替海明距离来完成和相似矩阵的适配,从而完成损失函数的构建。
二、然后是一篇ICCV2015的文章《Top Rank Supervised Binary Coding for Visual Search》,这篇文章的思路很新颖,和别的不太一样,这篇文章的最大贡献是在loss function中夹带了样本的排序信息,他使用三元组信息。主要公式如下
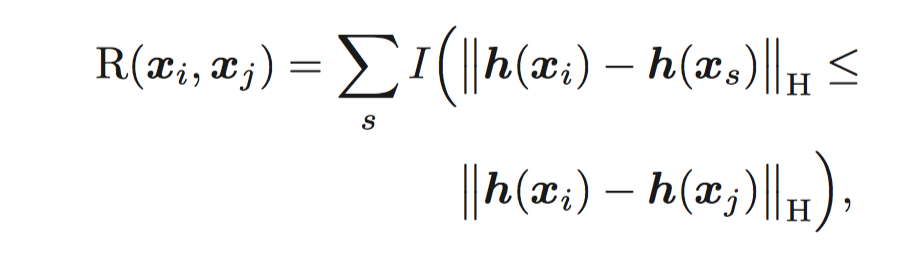
这里已知dis(xi,xj)<dis(xi,xs)可以看出他的主要思路就是让xi和xj的距离排名最高,通过这样的loss function,我们可以保证query和查找的answer相似度距离是最近的,这也是我们最直观想要得到的结果。这是该文章最大的贡献。
总结:这篇文章给我最大的启示是你要关注你最终要的是什么,根据你最终的需要设计你的损失函数。比如我就需要我的查询和查询量相似度排序最高,其他都比他们低。那根据这个思路就可以设计出适合的损失函数。
三、最后是AAAI2016的文章《Towards Optimal Binary Code Learning via Ordinal Embedd》这篇是我看的唯一一篇非监督hash,思路也很新颖,利用两两样本间的相似序数关系建图,图的节点代表两两节点,而图中的有向边代表该边始点对应的节点对间的距离小于该边终点所指向的节点对(语言描述好绕。。),之后利用这个图的信息代替了之前的pairwise信息,得到loss function:
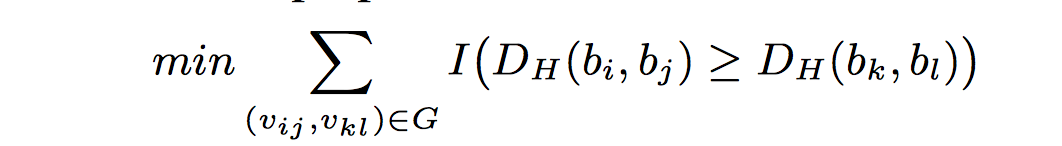
之后在转化问题的时候貌似借用了svm的思想,把这个问题转化成了一个min max问题。最后数学求解。其中由于直接建图时间复杂度太高,所以使用了聚类中心建图,之后对比了原样本与聚类中心的差别,最后构建出了最后的损失函数,之后用tanh+SGD求解。
总结:首先这篇文章让我看出了非监督哈希和监督哈希的一些区别,感觉非监督的由于要深度挖掘数据本身的关系,所以使用的方法要复杂一些,不能像前两篇文章那样直接用简单的思想构建loss function。其次让我明白了一些聚类的使用方法。
最后感想:这三篇都是比较老的文章,用的还都是传统机器学习方法,没有用到神经网络(但其实我更喜欢这种类型的),而且我发现这些哈希学习文章都在损失函数上下文章,本质都是根据不同的场景设计设计不同的损失函数,在对hash function的构建,哈希码平衡上都没有太大改动,可能在16年以后神经网络火之后会改变hash function的形式,使用神经网络代替传统的kernel或liner吧。总之这三篇文章带我入门了hash,以后随着阅读量的增加,会继续补充这个系列,作为以后科研的一个笔记。