splitDataSet这个函数困扰了我好一阵子,为什么以某一特征值为标准进行划分数据集以后,变成了局部?例如,如果以第1个特征为0为标准进行划分,那么返回的结果集就是不含有此特征的结果集,如下图红框部分所示:
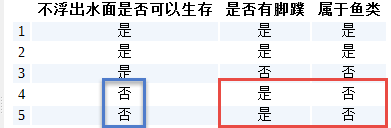
代码表示为:[[1, 'no'], [1, 'no']]
同理,如果以第1个特征为1作为标准,那么返回的结果集如下图所示:
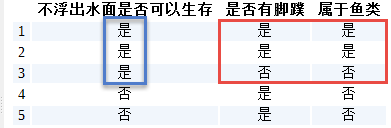
代码表示为:[[1, 'yes'], [1, 'yes'], [0, 'no']]
后经此文提示:http://blog.csdn.net/guo1988kui/article/details/75110361
了解到这是因为把那个特征值作为分界线以后,它自身不再作为特征出现在数据集中。
但是我没想明白为什么要这样做,是什么道理?为什么分界线就不再进入数据集了?穿红衣服的同学一组,蓝衣服的同学一组,那么这个分界线就是“衣服”,为什么要把“衣服”排除在外?
同时,实际上,它是否进入数据集,对熵并没有影响。
它统计的是符合特征的样本数量占样本总体的比例,得到概率,与特征数量本身没有关系。
存疑。随着学习的深入,希望有一天能够解开。
继续往下看就知道了,因为要构建决策树,数据集中的特征应当逐步减少。