这场的题都让我收获颇丰啊QWQ 感谢van♂老师
T1 喵喵喵!当时以为经典题只能那么做, 思维定势了...
因为DP本质是通过一些条件和答案互相递推的一个过程, 实际上就是把条件和答案分配在DP的状态和结果中, 所以当条件数值非常大, 而答案比较小的时候, 完全可以将答案放在DP数组的状态中,用来递推条件, 如果这个条件合法, 那么表明这个答案是可行的。
在这题里面, 答案不会超过b串的长度, 而a串的长度可以非常长, 所以可以设f[i][j]为b串中前i个字符, 匹配了j为在a串中的最前位置是什么, 用序列自动机处理出nxt[i][x]为a串第i位的下一个x字符的位置,就很好转移了。
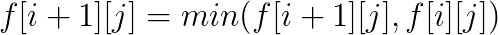
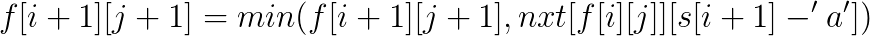


#include<iostream> #include<cstring> #include<cstdlib> #include<cstdio> #include<algorithm> #define ll long long using namespace std; const int maxn=1010,inf=1e9; int n1, n2, ans; int f[maxn][maxn], last[26], nxt[1000010][26]; char s1[1000010], s2[maxn]; void read(int &k) { int f=1;k=0;char c=getchar(); while(c<'0'||c>'9')c=='-'&&(f=-1),c=getchar(); while(c<='9'&&c>='0')k=k*10+c-'0',c=getchar(); k*=f; } inline int max(int a, int b){return a>b?a:b;} inline int min(int a, int b){return a<b?a:b;} int main() { scanf("%s", s1+1); scanf("%s", s2+1); int n1=strlen(s1+1), n2=strlen(s2+1); memset(f,32,sizeof(f)); f[0][0]=0; for(int i=0;i<26;i++) last[i]=inf; for(int i=n1;i>=0;i--) { for(int j=0;j<26;j++) nxt[i][j]=last[j]; if(i) last[s1[i]-'a']=i; } for(int i=0;i<=n2;i++) for(int j=0;j<=i;j++) if(f[i][j]<=n1) { f[i+1][j]=min(f[i+1][j], f[i][j]); f[i+1][j+1]=min(f[i+1][j+1], nxt[f[i][j]][s2[i+1]-'a']); ans=max(ans, j); } printf("%d ", ans); return 0; }
T2 也是道非常好的DP...
可以发现一个点至少被一个区间覆盖, 至多被两个区间覆盖,且区间必须相互覆盖, 因为是树不是森林。考虑区间覆盖的样子, 实际上是一些大区间下面覆盖着一些小区间, 所以可以考虑分类来转移。
先预处理出第i个位置的下一个左端点大于i的区间nxt[i], 设f[i][j]为前i个区间, 选择的区间最右端点为j的方案数, 如果当前区间左端点在j或j左边才可转移, 若当前区间为大区间(a[i].r>=j), 则有
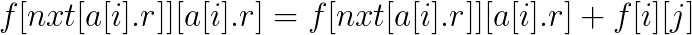
若当前区间为小区间(a[i].r<j), 则有
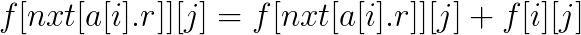
注意刷表法如果是用i这个位置更新答案的话最后的答案应该为f[n+1][]。
喵啊, 真的喵喵
#include<iostream> #include<cstring> #include<cstdlib> #include<cstdio> #include<cmath> #include<algorithm> #define MOD(x) ((x)>=mod?(x)-mod:(x)) using namespace std; const int maxn=2010, mod=1e9+7; struct poi{int l,r;}a[maxn]; int n, ans; int f[maxn][4010], nxt[4010]; inline void read(int &k) { int f=1; k=0; char c=getchar(); while(c<'0' || c>'9') c=='-'&&(f=-1), c=getchar(); while(c<='9' && c>='0') k=k*10+c-'0', c=getchar(); k*=f; } bool cmp(poi a, poi b){return a.l<b.l;} int main() { read(n); for(int i=1;i<=n;i++) read(a[i].l), read(a[i].r); sort(a+1, a+1+n, cmp); for(int i=1, j=1;i<=4000;nxt[i++]=j) while(j<=n && a[j].l<=i) j++; a[n+1].r=n+1; for(int i=1;i<=n;i++) f[i+1][a[i].r]=1; for(int i=1;i<=n;i++) for(int j=1;j<=4000;j++) { f[i+1][j]+=f[i][j]; f[i+1][j]=MOD(f[i+1][j]); if(a[i].l<=j) { if(a[i].r<j) f[nxt[a[i].r]][j]+=f[i][j], f[nxt[a[i].r]][j]=MOD(f[nxt[a[i].r]][j]); else f[nxt[j]][a[i].r]+=f[i][j], f[nxt[j]][a[i].r]=MOD(f[nxt[j]][a[i].r]); } } for(int i=1;i<=4000;i++) ans=MOD(ans+f[n+1][i]); printf("%d ", ans); return 0; }
T3 也喵喵喵...第一次见到这种姿势!
分阈值分块做!设一个阈值B, 分公差x<B和>=B两种情况
如果公差>=B, 可以直接暴力修改。因为当公差较大的时候, 修改复杂度会非常小, 这时候可以用O(n/B)修改, O(sqrt(n))查询的分块来做, 如果B定为sqrt(n),那肯定是可以承受的复杂度。
如果公差<B, 先说说80分的做法。
80分算法1:直接记录首项为y, 公差为x的被加了多少, 我们知道这些标记之后, 完全可以用数学方法O(1)算出区间[l, r]种这个标记出现了几次, 下面会提到怎么计算。这样的话修改O(1), 因为最多有B^2种标记, 所以查询是O(B^2)的。考虑平衡一下<B和>=B的情况, 应该尽量让它们相等, 即n/B=B^2, 所以将B定为n^(1/3), 复杂度为O(n^(5/3))的, 可以通过80分的数据。
80分算法2:可以发现一个公差为y的标记, 无论首项是多少, 在区间[l,r]最多只有两种取值, 因为考虑首项+1, 最多会有一个数被移出去, 而在接下来的移动中, 下一个数被移出去之前必定有一个新的从前面加入。考虑使用树状数组来维护区间和这时候我们用前面提到的数学方法来计算这些区间,具体方法下面再细说...将B定为sqrt(n)这样复杂度为O(nsqrtnlogn)
100分做法...
发现我们前两种做法的修改复杂度都较低, 而主要复杂度在查询上, 可以考虑提高修改复杂度使得查询复杂度降低, 有什么做法是修改复杂度高而查询复杂度低的呢?对了, 前缀和!tag[x][y]表示公差为x, 首项y~x的标记和, 这样每次修改的复杂度为O(B), 查询的时候枚举公差, 用数学方法O(1)算出这个公差的答案, 复杂度O(B), 考虑上<B时的常数比较大, 所以将B定为sqrt(n/5)就可以过了...现在终于来说说所谓的数学方法...考虑80分算法1所提到的一个区间中同个公差的标记只有2种, 而取值较小的那种用r/i和(l-1)/i相减就可以求得了, 这个还是很好推的。思考一下什么时候取值会变大,就是当新的一个数进入区间开始, 到下一个数离开区间结束, 中间这一段会比另一个取值多1, 而新的一个数进入区间就是首项为x+k*i和l重合开始, 末项y+k*i和r重合结束, 也就是首项在[l%i, r%i]的时候。所以我们只需要加上所有首项的答案, 最后再加上一次首项在[l%i, r%i]这一段的答案就好了。即tag[i][i]*(r/i-(l-1)/i)+tag[i][r]-tag[i][l-1]即为答案。
#include<iostream> #include<cstring> #include<cstdlib> #include<cstdio> #include<cmath> #include<algorithm> #define MOD(x) ((x)>=mod?(x)-mod:(x)) using namespace std; const int maxn=200010, mod=1e9+7; int n, m, ty, x, y, z, blo; int tag[510][maxn], a[maxn], s[maxn], bl[maxn]; inline void read(int &k) { int f=1; k=0; char c=getchar(); while(c<'0' || c>'9') c=='-'&&(f=-1), c=getchar(); while(c<='9' && c>='0') k=k*10+c-'0', c=getchar(); k*=f; } void update(int x, int y, int z) { if(x>=blo) for(int i=y;i<=n;i+=x) a[i]+=z, a[i]=MOD(a[i]), s[bl[i]]+=z, s[bl[i]]=MOD(s[bl[i]]); else for(int i=y;i<=x;i++) tag[x][i]+=z, tag[x][i]=MOD(tag[x][i]); } inline int min(int a, int b){return a<b?a:b;} inline int query(int l, int r) { int up=min(bl[l]*blo, r), ans=0; for(int i=l;i<=up;i++) ans+=a[i], ans=MOD(ans); if(bl[l]!=bl[r]) for(int i=(bl[r]-1)*blo+1;i<=r;i++) ans+=a[i], ans=MOD(ans); for(int i=bl[l]+1;i<=bl[r]-1;i++) ans+=s[i], ans=MOD(ans); for(int i=1;i<=blo;i++) { int x=r/i-(l-1)/i; ans=(ans+1ll*x*tag[i][i]+tag[i][r%i]-tag[i][(l-1)%i]+mod)%mod; } return ans; } int main() { read(n); read(m); blo=sqrt(n/5); for(int i=1;i<=n;i++) bl[i]=(i-1)/blo+1; for(int i=1;i<=n;i++) read(a[i]); for(int i=1;i<=n;i++) s[bl[i]]+=a[i], s[bl[i]]=MOD(s[bl[i]]); for(int i=1;i<=m;i++) { read(ty); read(x); read(y); if(ty==1) read(z), update(x, y, z); else printf("%d ", query(x, y)); } }