认识URI、URL、URN
详细请参考:https://blog.51cto.com/xoyabc/1905492
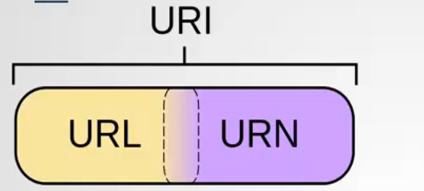
URI:uniform resource Indent 统一资源标识符
URL:uniform resource locator 统一资源定位符
URN:统一资源名称
它们的关系如:
URL
我们学习java网络编程最常用的类就是URL。
一个完整的URL由:protocol、host、port、path、parameter、anchor(锚点)组成
代码测试:
package _20191213;
import java.net.MalformedURLException;
import java.net.URL;
/**
* URL测试类
* @author TEDU
*
*/
public class URLTest {
public static void main(String[] args) throws MalformedURLException {
URL url = new URL("https://www.cnblogs.com/Scorpicat/category/1596649.html");
System.out.println(url.getProtocol());
System.out.println(url.getFile());
System.out.println(url.getAuthority());
System.out.println(url.getDefaultPort());
System.out.println(url.getPort());
System.out.println(url.getQuery());
System.out.println(url.getHost());
System.out.println(url.getRef());
System.out.println(url.getUserInfo());
}
}
运行结果:
https
/Scorpicat/category/1596649.html
www.cnblogs.com
443
-1
null
www.cnblogs.com
null
null
通过URL与IO流爬取一张网页的数据
运行后将会生成一个web.txt文件,存储有目标地址的网页数据。
package _20191213;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
public class DownloadAWebPage {
public static void main(String[] args) throws IOException {
//目标地址
URL url = new URL("https://gy.anjuke.com/?pi=navi-tencent-qq-mz");
//流创建:选择源,选择流,读取,关闭
BufferedReader br = new BufferedReader(new InputStreamReader(url.openStream(),"utf-8"));
BufferedWriter bw = new BufferedWriter(new FileWriter(new File("web.txt")));
char[] cbuf = new char[1024*8];
String content;
while((content = br.readLine())!=null) {
System.out.println(content);
bw.write(content);
bw.newLine();
bw.flush();
}
bw.close();
br.close();
}
}