Kubernetes之Prometheus监控实战
Prometheus服务监控介绍
对于运维开发人员来说,不管是哪个平台服务,监控都是非常关键重要的。
在传统服务里面,我们通常会到zabbix、open-falcon、netdata来做服务的监控,但对于目前主流的K8s平台来说,由于服务pod会被调度到任何机器上运行,且pod挂掉后会被自动重启,并且我们也需要有更好的自动服务发现功能来实现服务报警的自动接入,实现更高效的运维报警,这里我们需要用到K8s的监控实现Prometheus,它是基于Google内部监控系统的开源实现。
Prometheus架构图
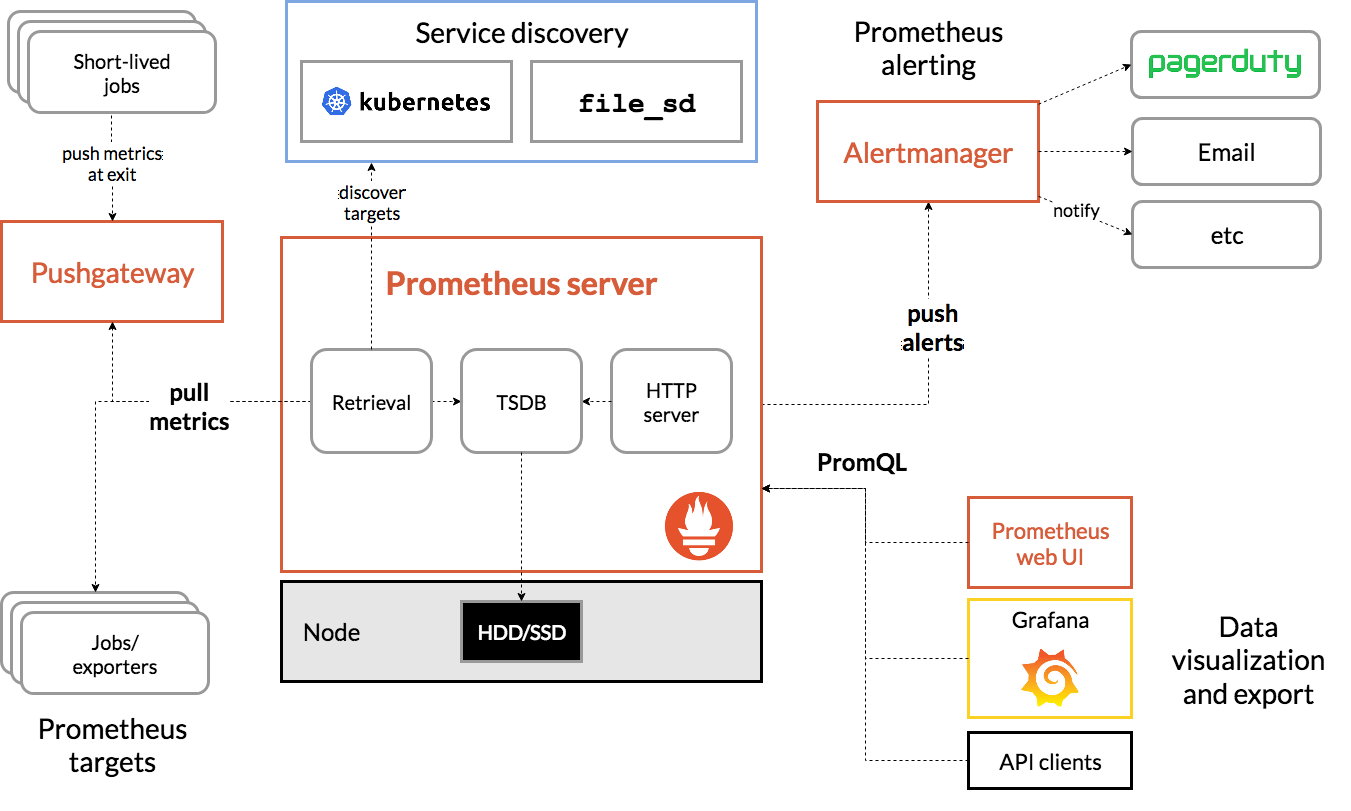
Prometheus是由golang语言编写,这样它的部署实际上是比较简单的,就一个服务的二进制包加上对应的配置文件即可运行,然而这种方式的部署过程繁琐并且效率低下,我们这里就不以这种传统的形式来部署Prometheus来实现K8s集群的监控了,而是会用到Prometheus-Operator来进行Prometheus监控服务的安装,这也是我们生产中常用的安装方式。
从本质上来讲Prometheus属于是典型的有状态应用,而其有包含了一些自身特有的运维管理和配置管理方式。而这些都无法通过Kubernetes原生提供的应用管理概念实现自动化。为了简化这类应用程序的管理复杂度,CoreOS率先引入了Operator的概念,并且首先推出了针对在Kubernetes下运行和管理Etcd的Etcd Operator。并随后推出了Prometheus Operator。
Prometheus Operator的工作原理
从概念上来讲Operator就是针对管理特定应用程序的,在Kubernetes基本的Resource和Controller的概念上,以扩展Kubernetes api的形式。帮助用户创建,配置和管理复杂的有状态应用程序。从而实现特定应用程序的常见操作以及运维自动化。
在Kubernetes中我们使用Deployment、DamenSet,StatefulSet来管理应用Workload,使用Service,Ingress来管理应用的访问方式,使用ConfigMap和Secret来管理应用配置。我们在集群中对这些资源的创建,更新,删除的动作都会被转换为事件(Event),Kubernetes的Controller Manager负责监听这些事件并触发相应的任务来满足用户的期望。这种方式我们成为声明式,用户只需要关心应用程序的最终状态,其它的都通过Kubernetes来帮助我们完成,通过这种方式可以大大简化应用的配置管理复杂度。
而除了这些原生的Resource资源以外,Kubernetes还允许用户添加自己的自定义资源(Custom Resource)。并且通过实现自定义Controller来实现对Kubernetes的扩展。
如下所示,是Prometheus Operator的架构示意图:
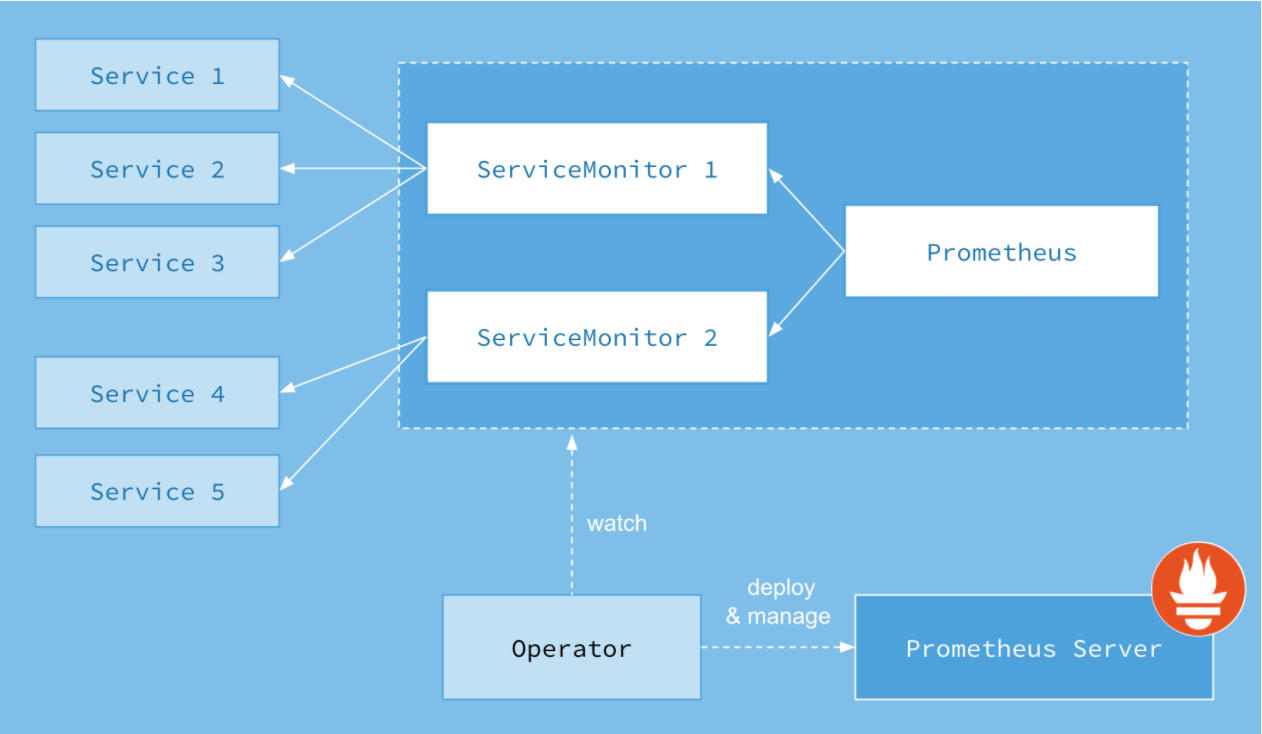
Prometheus的本质就是一组用户自定义的CRD资源以及Controller的实现,Prometheus Operator负责监听这些自定义资源的变化,并且根据这些资源的定义自动化地完成如Prometheus Server自身以及配置的自动化管理工作。
Prometheus Operator能做什么
要了解Prometheus Operator能做什么,其实就是要了解Prometheus Operator为我们提供了哪些自定义的Kubernetes资源,列出了Prometheus Operator目前提供的️4类资源:
- Prometheus:声明式创建和管理Prometheus Server实例;
- ServiceMonitor:负责声明式的管理监控配置;
- PrometheusRule:负责声明式的管理告警配置;
- Alertmanager:声明式的创建和管理Alertmanager实例。
简言之,Prometheus Operator能够帮助用户自动化的创建以及管理Prometheus Server以及其相应的配置。
实战操作篇之部署监控Prometheus Operator
在K8s集群中部署Prometheus Operator
我们这里用prometheus-operator来安装整套prometheus服务,建议直接用master分支即可,这也是官方所推荐的
https://github.com/prometheus-operator/kube-prometheus
开始安装
> 安装包和离线镜像包下载
>
>
> https://cloud.189.cn/t/bM7f2aANnMVb (访问码:0nsj)
1. 解压下载的代码包
unzip kube-prometheus-master.zip
rm -f kube-prometheus-master.zip && cd kube-prometheus-master
2. 这里建议先看下有哪些镜像,便于在下载镜像快的节点上先收集好所有需要的离线docker镜像
# find ./ -type f |xargs grep 'image: '|sort|uniq|awk '{print $3}'|grep ^[a-zA-Z]|grep -Evw 'error|kubeRbacProxy'|sort -rn|uniq
quay.io/prometheus/prometheus:v2.22.1
quay.io/prometheus-operator/prometheus-operator:v0.43.2
quay.io/prometheus/node-exporter:v1.0.1
quay.io/prometheus/alertmanager:v0.21.0
quay.io/fabxc/prometheus_demo_service
quay.io/coreos/kube-state-metrics:v1.9.7
quay.io/brancz/kube-rbac-proxy:v0.8.0
grafana/grafana:7.3.4
gcr.io/google_containers/metrics-server-amd64:v0.2.01
directxman12/k8s-prometheus-adapter:v0.8.2
在测试的几个node上把这些离线镜像包都导入 docker load -i xxx.tar
3. 开始创建所有服务
kubectl create -f manifests/setup
kubectl create -f manifests/
过一会查看创建结果:
kubectl -n monitoring get all
# 附:清空上面部署的prometheus所有服务:
kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup
访问下prometheus的UI
# 修改下prometheus UI的service模式,便于我们访问
# kubectl -n monitoring patch svc prometheus-k8s -p '{"spec":{"type":"NodePort"}}'
service/prometheus-k8s patched
# kubectl -n monitoring get svc prometheus-k8s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus-k8s NodePort 10.68.23.79 <none> 9090:22129/TCP 7m43s
点击上方菜单栏Status --- Targets ,我们发现kube-controller-manager和kube-scheduler未发现
monitoring/kube-controller-manager/0 (0/0 up)
monitoring/kube-scheduler/0 (0/0 up)
接下来我们解决下这一个碰到的问题吧
> 注:如果发现下面不是监控的127.0.0.1,并且通过下面地址可以获取metric指标输出,那么这个改IP这一步可以不用操作
>
> curl 10.0.1.201:10251/metrics curl 10.0.1.201:10252/metrics
# 这里我们发现这两服务监听的IP是127.0.0.1
# ss -tlnp|egrep 'controller|schedule'
LISTEN 0 32768 127.0.0.1:10251 *:* users:(("kube-scheduler",pid=567,fd=5))
LISTEN 0 32768 127.0.0.1:10252 *:* users:(("kube-controller",pid=583,fd=5))
问题定位到了,接下来先把两个组件的监听地址改为0.0.0.0
# 如果大家前面是按我设计的4台NODE节点,其中2台作master的话,那就在这2台master上把systemcd配置改一下
# 我这里第一台master 10.0.1.201
# sed -ri 's+127.0.0.1+0.0.0.0+g' /etc/systemd/system/kube-controller-manager.service
# sed -ri 's+127.0.0.1+0.0.0.0+g' /etc/systemd/system/kube-scheduler.service
# systemctl daemon-reload
# systemctl restart kube-controller-manager.service
# systemctl restart kube-scheduler.service
# 我这里第二台master 10.0.1.202
# sed -ri 's+127.0.0.1+0.0.0.0+g' /etc/systemd/system/kube-controller-manager.service
# sed -ri 's+127.0.0.1+0.0.0.0+g' /etc/systemd/system/kube-scheduler.service
# systemctl daemon-reload
# systemctl restart kube-controller-manager.service
# systemctl restart kube-scheduler.service
# 获取下metrics指标看看
curl 10.0.1.201:10251/metrics
curl 10.0.1.201:10252/metrics
然后因为K8s的这两上核心组件我们是以二进制形式部署的,为了能让K8s上的prometheus能发现,我们还需要来创建相应的service和endpoints来将其关联起来
> 注意:我们需要将endpoints里面的NODE IP换成我们实际情况的
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
k8s-app: kube-controller-manager
spec:
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10252
targetPort: 10252
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
subsets:
- addresses:
- ip: 10.0.1.201
- ip: 10.0.1.202
ports:
- name: http-metrics
port: 10252
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10251
targetPort: 10251
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: kube-system
subsets:
- addresses:
- ip: 10.0.1.201
- ip: 10.0.1.202
ports:
- name: http-metrics
port: 10251
protocol: TCP
将上面的yaml配置保存为repair-prometheus.yaml,然后创建它
kubectl apply -f repair-prometheus.yaml
创建完成后确认下
# kubectl -n kube-system get svc |egrep 'controller|scheduler'
kube-controller-manager ClusterIP None <none> 10252/TCP 58s
kube-scheduler ClusterIP None <none> 10251/TCP 58s
记得还要修改一个地方
# kubectl -n monitoring edit servicemonitors.monitoring.coreos.com kube-scheduler
# 将下面两个地方的https换成http
port: https-metrics
scheme: https
# kubectl -n monitoring edit servicemonitors.monitoring.coreos.com kube-controller-manager
# 将下面两个地方的https换成http
port: https-metrics
scheme: https
然后再返回prometheus UI处,耐心等待几分钟,就能看到已经被发现了
monitoring/kube-controller-manager/0 (2/2 up)
monitoring/kube-scheduler/0 (2/2 up)
使用prometheus来监控ingress-nginx
我们前面部署过ingress-nginx,这个是整个K8s上所有服务的流量入口组件很关键,因此把它的metrics指标收集到prometheus来做好相关监控至关重要,因为前面ingress-nginx服务是以daemonset形式部署的,并且映射了自己的端口到宿主机上,那么我可以直接用pod运行NODE上的IP来看下metrics
curl 10.0.1.201:10254/metrics
创建 servicemonitor配置让prometheus能发现ingress-nginx的metrics
# vim servicemonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app: ingress-nginx
name: nginx-ingress-scraping
namespace: ingress-nginx
spec:
endpoints:
- interval: 30s
path: /metrics
port: metrics
jobLabel: app
namespaceSelector:
matchNames:
- ingress-nginx
selector:
matchLabels:
app: ingress-nginx
创建它
# kubectl apply -f servicemonitor.yaml
servicemonitor.monitoring.coreos.com/nginx-ingress-scraping created
# kubectl -n ingress-nginx get servicemonitors.monitoring.coreos.com
NAME AGE
nginx-ingress-scraping 8s
指标一直没收集上来,看看proemtheus服务的日志,发现报错如下:
# kubectl -n monitoring logs prometheus-k8s-0 -c prometheus |grep error
level=error ts=2020-12-13T09:52:35.565Z caller=klog.go:96 component=k8s_client_runtime func=ErrorDepth msg="/app/discovery/kubernetes/kubernetes.go:426: Failed to watch *v1.Endpoints: failed to list *v1.Endpoints: endpoints is forbidden: User "system:serviceaccount:monitoring:prometheus-k8s" cannot list resource "endpoints" in API group "" in the namespace "ingress-nginx""
需要修改prometheus的clusterrole
# kubectl edit clusterrole prometheus-k8s
#------ 原始的rules -------
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
#---------------------------
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-k8s
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
再到prometheus UI上看下,发现已经有了
ingress-nginx/nginx-ingress-scraping/0 (1/1 up)
使用Prometheus来监控二进制部署的ETCD集群
作为K8s所有资源存储的关键服务ETCD,我们也有必要把它给监控起来,正好借这个机会,完整的演示一次利用Prometheus来监控非K8s集群服务的步骤
在前面部署K8s集群的时候,我们是用二进制的方式部署的ETCD集群,并且利用自签证书来配置访问ETCD,正如前面所说,现在关键的服务基本都会留有指标metrics接口支持prometheus的监控,利用下面命令,我们可以看到ETCD都暴露出了哪些监控指标出来
# curl --cacert /etc/kubernetes/ssl/ca.pem --cert /etc/etcd/ssl/etcd.pem --key /etc/etcd/ssl/etcd-key.pem https://10.0.1.201:2379/metrics
上面查看没问题后,接下来我们开始进行配置使ETCD能被prometheus发现并监控
# 首先把ETCD的证书创建为secret
kubectl -n monitoring create secret generic etcd-certs --from-file=/etc/etcd/ssl/etcd.pem --from-file=/etc/etcd/ssl/etcd-key.pem --from-file=/etc/kubernetes/ssl/ca.pem
# 接着在prometheus里面引用这个secrets
kubectl -n monitoring edit prometheus k8s
spec:
...
secrets:
- etcd-certs
# 保存退出后,prometheus会自动重启服务pod以加载这个secret配置,过一会,我们进pod来查看下是不是已经加载到ETCD的证书了
# kubectl -n monitoring exec -it prometheus-k8s-0 -c prometheus -- sh
/prometheus $ ls /etc/prometheus/secrets/etcd-certs/
ca.pem etcd-key.pem etcd.pem
接下来准备创建service、endpoints以及ServiceMonitor的yaml配置
> 注意替换下面的NODE节点IP为实际ETCD所在NODE内网IP
# vim prometheus-etcd.yaml
apiVersion: v1
kind: Service
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd
spec:
type: ClusterIP
clusterIP: None
ports:
- name: api
port: 2379
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd
subsets:
- addresses:
- ip: 10.0.1.201
- ip: 10.0.1.202
- ip: 10.0.1.203
ports:
- name: api
port: 2379
protocol: TCP
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd-k8s
spec:
jobLabel: k8s-app
endpoints:
- port: api
interval: 30s
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-certs/ca.pem
certFile: /etc/prometheus/secrets/etcd-certs/etcd.pem
keyFile: /etc/prometheus/secrets/etcd-certs/etcd-key.pem
#use insecureSkipVerify only if you cannot use a Subject Alternative Name
insecureSkipVerify: true
selector:
matchLabels:
k8s-app: etcd
namespaceSelector:
matchNames:
- monitoring
开始创建上面的资源
# kubectl apply -f prometheus-etcd.yaml
service/etcd-k8s created
endpoints/etcd-k8s created
servicemonitor.monitoring.coreos.com/etcd-k8s created
过一会,就可以在prometheus UI上面看到ETCD集群被监控了
monitoring/etcd-k8s/0 (3/3 up)
接下来我们用grafana来展示被监控的ETCD指标
1. 在grafana官网模板中心搜索etcd,下载这个json格式的模板文件
https://grafana.com/dashboards/3070
2.然后打开自己先部署的grafana首页,
点击左边菜单栏四个小正方形方块HOME --- Manage
再点击右边 Import dashboard ---
点击Upload .json File 按钮,上传上面下载好的json文件 etcd_rev3.json,
然后在prometheus选择数据来源
点击Import,即可显示etcd集群的图形监控信息
prometheus监控数据以及grafana配置持久化存储配置
这节实战课给大家讲解下如果配置prometheus以及grafana的数据持久化。
prometheus数据持久化配置
# 注意这下面的statefulset服务就是我们需要做数据持久化的地方
# kubectl -n monitoring get statefulset,pod|grep prometheus-k8s
statefulset.apps/prometheus-k8s 2/2 5h41m
pod/prometheus-k8s-0 2/2 Running 1 19m
pod/prometheus-k8s-1 2/2 Running 1 19m
# 看下我们之前准备的StorageClass动态存储
# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-boge nfs-provisioner-01 Retain Immediate false 4d
# 准备prometheus持久化的pvc配置
# kubectl -n monitoring edit prometheus k8s
spec:
......
storage:
volumeClaimTemplate:
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "nfs-boge"
selector:
matchLabels:
app: my-example-prometheus
resources:
requests:
storage: 1Gi
# 上面修改保存退出后,过一会我们查看下pvc创建情况,以及pod内的数据挂载情况
# kubectl -n monitoring get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
prometheus-k8s-db-prometheus-k8s-0 Bound pvc-055e6b11-31b7-4503-ba2b-4f292ba7bd06 1Gi RWO nfs-boge 17s
prometheus-k8s-db-prometheus-k8s-1 Bound pvc-249c344b-3ef8-4a5d-8003-b8ce8e282d32 1Gi RWO nfs-boge 17s
# kubectl -n monitoring exec -it prometheus-k8s-0 -c prometheus -- sh
/prometheus $ df -Th
......
10.0.1.201:/nfs_dir/monitoring-prometheus-k8s-db-prometheus-k8s-0-pvc-055e6b11-31b7-4503-ba2b-4f292ba7bd06/prometheus-db
nfs4 97.7G 9.4G 88.2G 10% /prometheus
grafana配置持久化存储配置
# 保存pvc为grafana-pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: grafana
namespace: monitoring
spec:
storageClassName: nfs-boge
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
# 开始创建pvc
# kubectl apply -f grafana-pvc.yaml
# 看下创建的pvc
# kubectl -n monitoring get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
grafana Bound pvc-394a26e1-3274-4458-906e-e601a3cde50d 1Gi RWX nfs-boge 3s
prometheus-k8s-db-prometheus-k8s-0 Bound pvc-055e6b11-31b7-4503-ba2b-4f292ba7bd06 1Gi RWO nfs-boge 6m46s
prometheus-k8s-db-prometheus-k8s-1 Bound pvc-249c344b-3ef8-4a5d-8003-b8ce8e282d32 1Gi RWO nfs-boge 6m46s
# 编辑grafana的deployment资源配置
# kubectl -n monitoring edit deployments.apps grafana
# 旧的配置
volumes:
- emptyDir: {}
name: grafana-storage
# 替换成新的配置
volumes:
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana
# 同时加入下面的env环境变量,将登陆密码进行固定修改
spec:
containers:
......
env:
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD
value: admin321
# 过一会,等grafana重启完成后,用上面的新密码进行登陆
# kubectl -n monitoring get pod -w|grep grafana
grafana-5698bf94f4-prbr2 0/1 Running 0 3s
grafana-5698bf94f4-prbr2 1/1 Running 0 4s
# 因为先前的数据并未持久化,所以会发现先导入的ETCD模板已消失,这时重新再导入一次,后面重启也不会丢了
Prometheus发送报警
大家好,我是博哥爱运维。早期我们经常用邮箱接收报警邮件,但是报警不及时,而且目前各云平台对邮件发送限制还比较严格,所以目前在生产中用得更为多的是基于webhook来转发报警内容到企业中用的聊天工具中,比如钉钉、企业微信、飞书等。
prometheus的报警组件是Alertmanager,它支持自定义webhook的方式来接受它发出的报警,它发出的日志json字段比较多,我们需要根据需要接收的app来做相应的日志清洗转发
这里博哥将用golang结合Gin网络框架来编写一个日志清洗转发工具,分别对这几种常用的报警方式作详细地说明及实战
> 下载boge-webhook.zip
>
>
> https://cloud.189.cn/t/B3EFZvnuMvuu (访问码:h1wx)
首先看下报警规则及报警发送配置是什么样的
prometheus-operator的规则非常齐全,基本属于开箱即用类型,大家可以根据日常收到的报警,对里面的rules报警规则作针对性的调整,比如把报警观察时长缩短一点等
监控报警规划修改 vim ./manifests/prometheus/prometheus-rules.yaml
修改完成记得更新 kubectl apply -f ./manifests/prometheus/prometheus-rules.yaml
# 通过这里可以获取需要创建的报警配置secret名称
# kubectl -n monitoring edit statefulsets.apps alertmanager-main
...
volumes:
- name: config-volume
secret:
defaultMode: 420
secretName: alertmanager-main
...
# 注意事先在配置文件 alertmanager.yaml 里面编辑好收件人等信息 ,再执行下面的命令
kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml -n monitoring
报警配置文件 alertmanager.yaml
# global块配置下的配置选项在本配置文件内的所有配置项下可见
global:
# 在Alertmanager内管理的每一条告警均有两种状态: "resolved"或者"firing". 在altermanager首次发送告警通知后, 该告警会一直处于firing状态,设置resolve_timeout可以指定处于firing状态的告警间隔多长时间会被设置为resolved状态, 在设置为resolved状态的告警后,altermanager不会再发送firing的告警通知.
# resolve_timeout: 1h
resolve_timeout: 10m
# 告警通知模板
templates:
- '/etc/altermanager/config/*.tmpl'
# route: 根路由,该模块用于该根路由下的节点及子路由routes的定义. 子树节点如果不对相关配置进行配置,则默认会从父路由树继承该配置选项。每一条告警都要进入route,即要求配置选项group_by的值能够匹配到每一条告警的至少一个labelkey(即通过POST请求向altermanager服务接口所发送告警的labels项所携带的<labelname>),告警进入到route后,将会根据子路由routes节点中的配置项match_re或者match来确定能进入该子路由节点的告警(由在match_re或者match下配置的labelkey: labelvalue是否为告警labels的子集决定,是的话则会进入该子路由节点,否则不能接收进入该子路由节点).
route:
# 例如所有labelkey:labelvalue含cluster=A及altertname=LatencyHigh labelkey的告警都会被归入单一组中
group_by: ['job', 'altername', 'cluster', 'service','severity']
# 若一组新的告警产生,则会等group_wait后再发送通知,该功能主要用于当告警在很短时间内接连产生时,在group_wait内合并为单一的告警后再发送
# group_wait: 30s
group_wait: 10s
# 再次告警时间间隔
# group_interval: 5m
group_interval: 20s
# 如果一条告警通知已成功发送,且在间隔repeat_interval后,该告警仍然未被设置为resolved,则会再次发送该告警通知
# repeat_interval: 12h
repeat_interval: 1m
# 默认告警通知接收者,凡未被匹配进入各子路由节点的告警均被发送到此接收者
receiver: 'webhook'
# 上述route的配置会被传递给子路由节点,子路由节点进行重新配置才会被覆盖
# 子路由树
routes:
# 该配置选项使用正则表达式来匹配告警的labels,以确定能否进入该子路由树
# match_re和match均用于匹配labelkey为service,labelvalue分别为指定值的告警,被匹配到的告警会将通知发送到对应的receiver
- match_re:
service: ^(foo1|foo2|baz)$
receiver: 'webhook'
# 在带有service标签的告警同时有severity标签时,他可以有自己的子路由,同时具有severity != critical的告警则被发送给接收者team-ops-wechat,对severity == critical的告警则被发送到对应的接收者即team-ops-pager
routes:
- match:
severity: critical
receiver: 'webhook'
# 比如关于数据库服务的告警,如果子路由没有匹配到相应的owner标签,则都默认由team-DB-pager接收
- match:
service: database
receiver: 'webhook'
# 我们也可以先根据标签service:database将数据库服务告警过滤出来,然后进一步将所有同时带labelkey为database
- match:
severity: critical
receiver: 'webhook'
# 抑制规则,当出现critical告警时 忽略warning
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
# Apply inhibition if the alertname is the same.
# equal: ['alertname', 'cluster', 'service']
#
# 收件人配置
receivers:
- name: 'webhook'
webhook_configs:
- url: 'http://alertmanaer-dingtalk-svc.kube-system//b01bdc063/boge/getjson'
send_resolved: true