一、JML简介
1.1 JML与契约式设计
说起JML,就不得不提到契约式设计(Design by Contract)。这种设计模式的始祖是1986年的Eiffel语言。它是一种限定了软件中每个元素所必需的责任与义务的开发模式,程序设计中的每个元素都需要用规范的语言精准地限定其前置条件(Preconditions)、后置条件(Postconditions)和不变式(Invariants)。通过这三项限定,我们可以清晰地获得对一个函数功能的刻画,从而达成设计与实现的分离,便于优化、测试和生成文档。
契约式设计的理论基础是形式验证、形式规约和霍尔逻辑。在我看来,契约式设计正是形式规约的工程化实现方式,也正是因为有了规范的契约,形式验证才可能得以成立。相比于测试驱动编程(Test-Driven Development),契约式设计能通过定理证明器通过形式验证的方式证明程序的正确性,从而更加可靠。
契约式设计在很多语言中都有自带支持,例如Fortress、Perl和Java的新近亲Kotlin,其中很多语言都是通过类似于assert断言的方法进行契约限定的。Java并没有自带的契约式设计模块,JML作为仍处于活跃开发中的第三方Java契约式设计模块可以填补这一方面的空白。
JML是一种行为接口规格语言,可以借由一套标准化的带注解的注释实现对Java代码语法接口(即函数名、返回类型、可抛出异常等)和行为的规范。JML将Eiffel等契约式设计语言的操作性和Java等现代语言的可读性相结合,利用Java表达式进行规格书写,并对其进行了一定的扩展,增加了量词方便规格书写。
1.2 JML工具链
JML的一大优势就在于其丰富的外围工具,它们都被罗列在了http://www.eecs.ucf.edu/~leavens/JML//download.shtml上。其中比较重要的几个如下:
- OpenJML:首选的JML相关工具,以提供全面且支持最新Java标准的JML相关支持为目标,能够进行静态规格检查(ESC,Extended Static Cheking)、运行时规格检查(RAC,Runtime Assertion Checking)和形式化验证等一系列功能。OpenJML提供了自带的命令行版本和Eclipse插件版本。
- JML Editing:官方的Eclipse插件,提供了JML规格的代码高亮及代码补全。
- JMLUnitNG:JMLUnit的替代工具,能够根据JML规格自动生成基于测试库TestNG的单元测试集。
- jmldoc:能够通过JML生成javadoc的工具。现已合并入OpenJML中。
JML还有一系列其他工具,但是这些工具大都是从不同角度根据规格进行代码测试的,这些功能已被OpenJML所涵盖。
二、SMT Solver的使用
利用SMT Solver进行形式化验证是OpenJML提供的功能之一。该工具有两种使用方式:使用命令行版本(或通过IDEA的OpenJML/ESC插件间接调用该工具)或使用OpenJML的Eclipse插件。
在我的前一篇博客中,我介绍了如何利用Maven项目在IDEA和Eclipse间进行项目互通以方便地使用Eclipse插件进行形式化验证,因此在此省略操作部分。
然而,OpenJML存在一些谜一样的问题,会导致代码被错误地判为invalid。许多人遇到的size在形式验证中返回值为真实值-1的错误至今依然让我感到疑惑,甚至MyPath同样的代码和规格,在第9次作业中全部为valid,然而复制粘贴到第10次作业中就出现了错判。这也许和OpenJML对JML语法的支持尚不完全有关,不过我在写上一篇博客时意外地留下了一张运行无误的截图,在此可以对它进行一下粗略的分析。
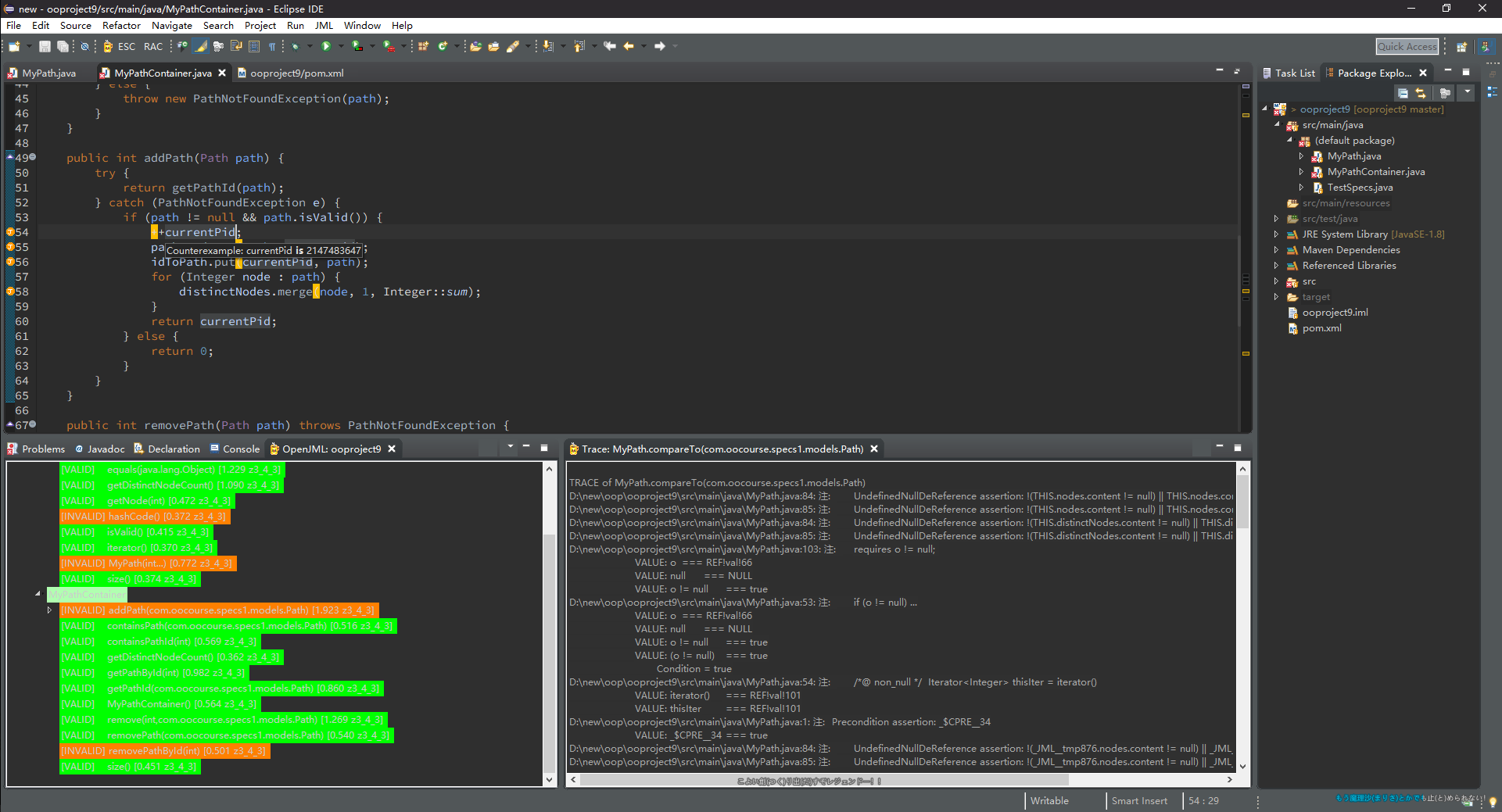
这是对我的第9次作业所有文件的形式验证结果,验证配置为OpenJML 0.8.42 + z3 Prover 4.7.1。从左下角一片绿色的验证结果可以看出,这次作业中MyPath和MyPathContainer两个类中除了个别方法被判为invalid外(实际上这些错误大部分是因为整数自增溢出),其余方法都能够完美地通过形式化验证。在这其中,出现错误最多也最典型的一个函数是MyPathContainer.addPath()。从代码中的高亮可以看到,该函数中存在4处错误。这四处错误分别为:
- 54行:
++currentPid中,由于currentPid为int型,故自增可能导致溢出。 - 55行、56行:我在
MyPathContainer的实现中为了提高id和Path互查的效率,采用了双HashMap的结构,因此在addPath()中需要对pathToId和idToPath两个HashMap均进行put()操作。此处报出的两个错均为InvariantLeaveCaller,表明调用一个外部函数时不满足不变式。这一结果出乎意料地正确,因为在调用单个put()操作的中间,由于已经调用了外部函数,故属于可见状态,而在此期间两个HashMap并未完成统一,所以不变式未达成。不过HashMap.put()作为jdk自带方法,这样的报错也许是多余的。 - 58行:在这里虽然采用了java 8的双冒号写法,但内涵依然是
int递增,仍然可能导致溢出。
由此可见,利用SMT Solver在不出现无法解释的全部判错现象时是非常可靠的,可以认为一旦通过了该测试就完全符合了规格要求,是保险性最高的测试。
三、JMLUnitNG的使用
此处首先感谢讨论区伦dalao的分享。
JMLUnitNG虽然是JMLUnit的替代版,但它的功能尚未开发完全,使用起来非常复杂,稍有不慎就会让人彻底崩溃。我在使用过程中遇到了许多难题:
- 该工具的最后一次更新是在2014年,甚至在java 1.8更新前。由于JMLUnitNG包中自带了其全部依赖库,所以其自带的过旧的OpenJML库依赖使得其无法正常分析使用了java 1.8及之后版本的语法,这给测试造成了第一道困难。为此,我将其依赖的OpenJML工具替换成了截至2019年5月的最新版本0.8.42并重新打了包,感兴趣的可以从我的github上下载:https://github.com/sheryc/JMLUnitNG/releases/tag/v1_5
- 该工具分四步操作:生成测试→编译→执行rac→测试。在第一步生成测试中,需要添加-cp参数添加库依赖。根据JMLUnitNG的官方doc,classpath参数的写法遵循javac写法,然而实际上在添加多个依赖目录时,JMLUnitNG采用了对windows系统极为不友好的冒号分隔方式。这导致以盘符加冒号(如D:)开头的绝对路径无法作为JMLUnitNG的-cp参数被传入。为了解决这个问题,需要将依赖库全部放入项目文件夹中。
- JMLUnitNG不允许所分析的文件中带有GBK字符,而官方接口中每个函数都有用中文写的javadoc,删除注释的工作量巨大。最终迫不得已转成了对并不依赖过多官方文件的
MyPath类进行测试。 - 当依赖.jar文件包时,JMLUnitNG无法检测到JML规格。为此我将JML规格复制到了自己的文件中。
- 由于对OpenJML的依赖,所以OpenJML存在的对一部分量词无法验证的问题自然也继承到了JMLUnitNG中。为此需要对规格进行改写。需要删去model,在自己的实现中添加
spec_public标识,并改写或删除会报错的exists和forall规格。 - 即使解决了以上问题,还会存在JMLUnitNG对于一部分写法不能识别的问题。在一开始,我在进行rac步骤时会报出一个其他人都不会报出的错误:A catastrophic JML internal error occurred. Please report the bug with as much information as you can. Reason: Mismatch in number of arguments in accumulateTypeInstantiations。经过一段时间控制变量式的探索后,我发现错误根源竟在于
Path.equals()中采用的如下for-each循环:
Iterator<Integer> objIter = ((MyPath) obj).iterator();
for (Integer integer : this) {
if (!objIter.next().equals(integer)) {
return false;
}
}
该循环本身写法并没有错,并且支持了java 1.8语法后应该对for-each循环的判别没有问题。然而这样的循环竟然会导致OpenJML的内部错误,这非常不可理喻。这样一个错误花费了我很长的时间,从第9次作业贯穿到本次总结的写作,甚至我拜托了几名同学帮我进行测试,却怎么也没想到错误是由于OpenJML本身的bug导致的所谓“Catastrophic internal error”。最终我将for-each循环改为了hasNext()循环,解决了这个问题。
最终的测试结果如下:
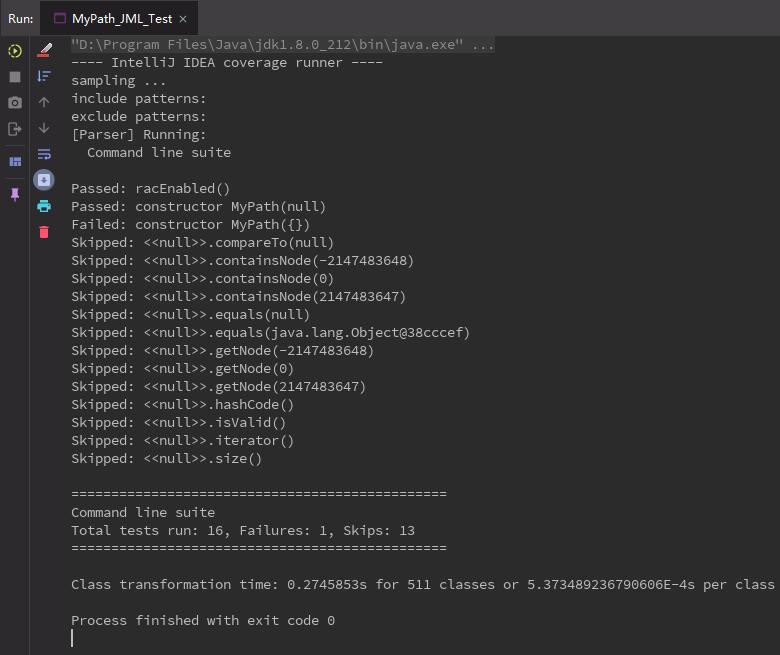
鼓捣了半天,最后居然报了构造方法出错,而且似乎因为构造器无法通过测试而跳过了后续的测试?但是MyPath的构造器实际上构造非常简单,由于时间紧迫,我也没有进一步探寻如何修复报出的莫须有的错误。不过从后续的测试数据中可以发现,JMLUnitNG即使在检测到了JML规格的情况下,所做的也只有边界测试,测试覆盖性极其有限,并且其生成单元测试的依据似乎不是JML规格,而是函数签名。
虽然自动生成单元测试的功能很方便,但对于JMLUnitNG这一款工具而言着实鸡肋:其高昂的学习代价,漏洞百出的执行过程,毫无体验感的使用流程,对JML规格并不够好的支持,以及最终生成的覆盖度差的测试用例,都不值得让用户使用这样一款半成品工具,也难怪早在5年前这一项目就停止了活跃开发。相比之下,阅读规格并自己设计单元测试会更加可靠且更加方便。在自行设计单元测试时,我们可以仿照JMLUnitNG的测试思路,在覆盖所有运行分支的基础上,多设计一些边界测试和无效测试,而这些在SMT Prover的形式验证中也常常成为测试的反例。
四、JUnit的使用
在这几次作业中,JUnit如果使用到位是可以对程序验证起到非常大的帮助的。在此以自己第9次作业的单元测试为例。通过对测试执行“Run with Coverage”指令,可以获得单元测试对代码中所有执行路径的覆盖程度:
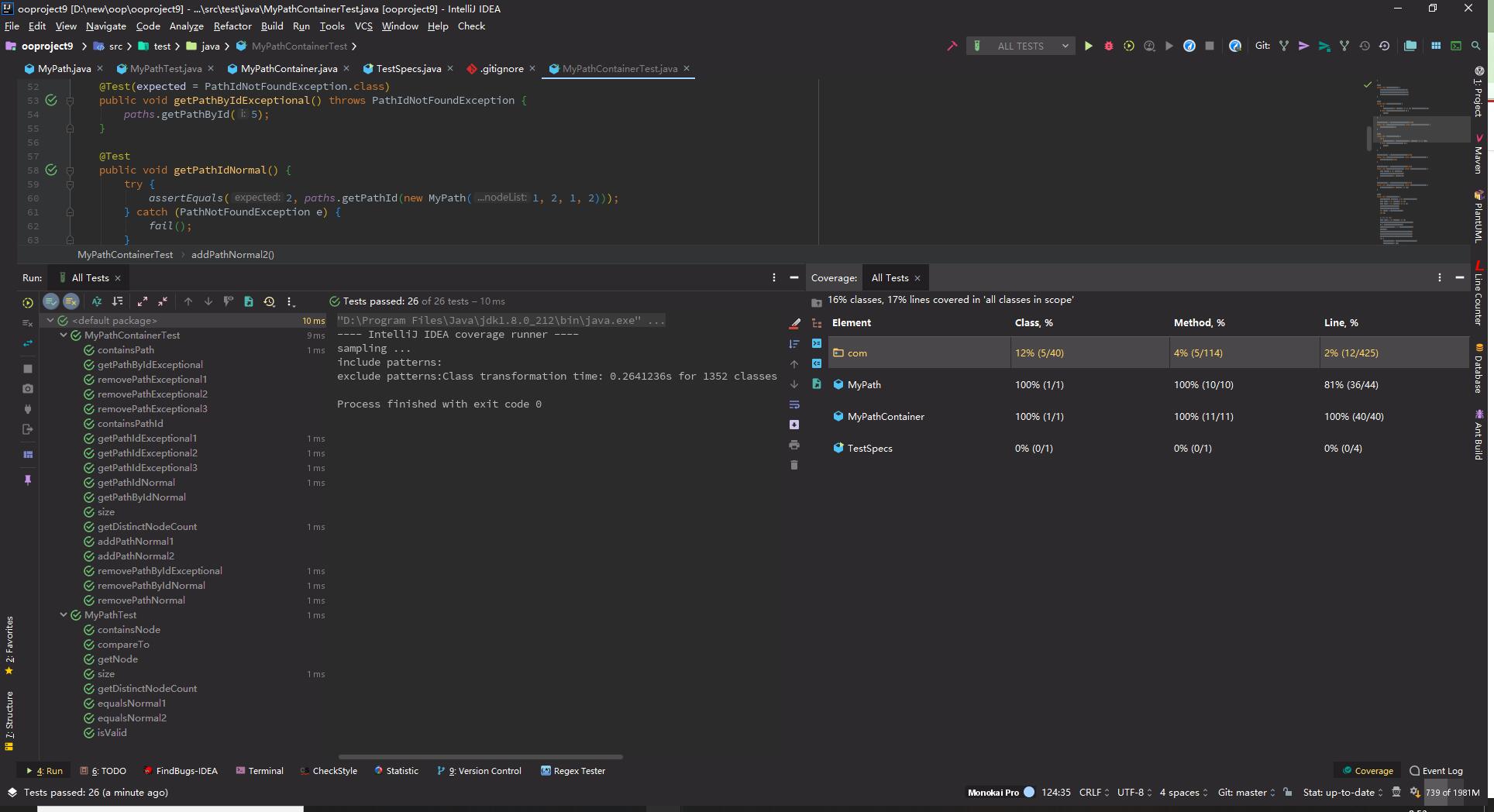
从右边的Coverage可以看出,我的测试对于MyPath和MyPathContainer的代码覆盖度分别达到了81%和100%,已经可以几乎覆盖到所有执行分支。而实际上,我的单元测试是在写代码前就已经写好的(颇有一种Test-Driven Develop的感觉),所以可以做到测试和代码的分离。
在设计测试时,需要将不同运行分支分在不同的方法中进行测试,这也是为何我的函数后面会带有Normal、Exceptional和编号,这样可以在一次执行中最大化发现的问题数量。
单元测试是最底层的测试,在我的理解中,它的作用与方法规格是相辅相成的,都是为了测试一个函数是否能够满足对该函数的所有要求。刚好在此次作业中每个函数的功能几乎是分离的,所以一个覆盖性好的单元测试对正确性的保证是仅次于形式验证的。
五、三次作业总结
5.1 第九次作业
5.1.1 实现方案
本次作业需要实现的是Path和PathContainer。
对于Path类,其存在的操作仅为查询。对根据下标查询的操作,选用基于数组的ArrayList可以达到O(1)复杂度;对查询节点是否存在/不重复节点个数的操作,选用HashSet可以达到一次生成后每次查询都为O(1)复杂度的目标。
对于外部函数可以通过iterator()返回的迭代器修改Path的问题,在这里我记录了每一次ArrayList的hash码,当进行HashSet相关查询操作时,首先比较当前ArrayList的hash码是否与先前保存的hash码,若相等则可以认为很大概率该Path未经过修改,否则重新构建HashSet。
我在其中使用了一些提高效率的小trick,比如HashSet的构建只有在进行相关查操作时才开始,这样可以省去一些进行无用且耗时的HashMap构建操作的时间。
对于PathContainer类,进行的是少量的增删操作和大量的查操作。为此,需要将查操作尽可能优化到O(1)复杂度。我采用了idToPath,pathToId双HashMap以优化二者之间的双向查找;与此同时,使用一个单独的HashMap记录每个节点的出现次数,这样在查询不重复节点时只需返回该HashMap的size即可。
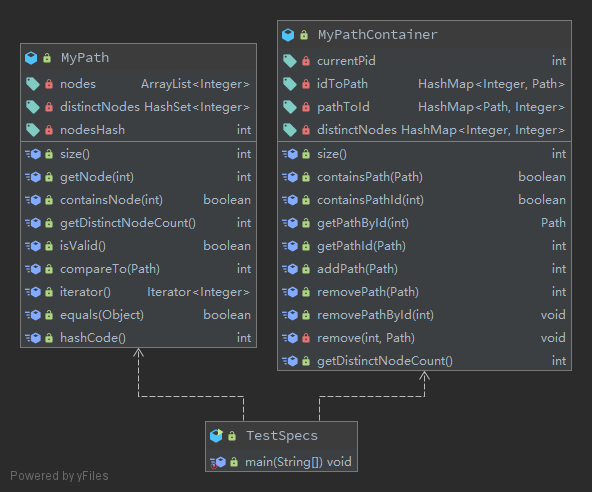
本次作业的UML类图如下:
5.1.2 出错分析
本次作业强测满分。高工不参加互测。
5.2 第十次作业
5.2.1 实现方案
本次作业中将PathContainer升级为了需要计算节点间路径长度的Graph。原本Path和PathContainer的操作依然保持不变。
在本次作业中我本应让MyGraph继承上次的MyPathContainer的,但当时我对于继承时private字段的处理方式理解不到位,所以没有用这种方式,而是直接将MyPathContainer的代码复制了过来。现在想来实在是非常不应该。
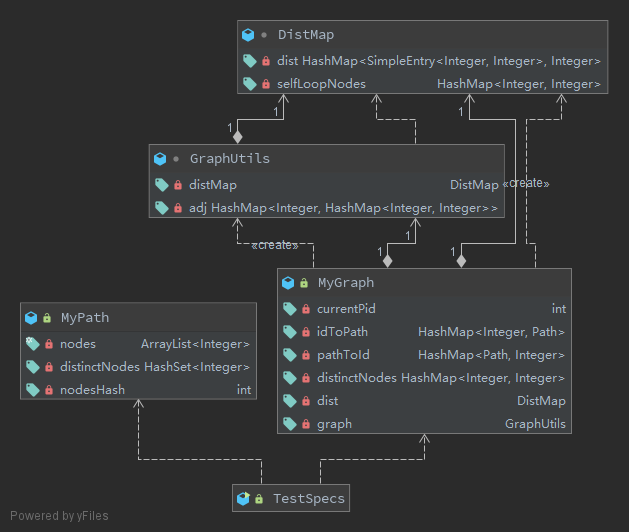
新增的操作全部是基于两点间最短距离的,所以计算最短路径成为了本次作业的核心。为此我新建了两个辅助类:用于压缩记录每两个节点间距离的DistMap和应用图算法的GraphUtils。
在DistMap中,我将每对节点的距离记录在了一个HashMap<AbstractMap.SimpleEntry<Node, Node> Integer>的数据结构中(此处Node实际上是Integer,这样写是为了理解方便;此外AbstractMap.SimpleEntry是java.util中自带的Pair类型)。由于需要存储的图是无向图,其距离矩阵应为对称阵,故为了节约存储空间 ,存入和查询时的SimpleEntry都应保证其key<=value,这样可以将距离矩阵压缩一半。
在GraphUtils中,采用基于优先队列的堆优化的Dijkstra算法。为此需要在该类中维护一个邻接矩阵HashMap<Node, HashMap<Node, Integer>>(此处Node实际上是Integer,这样写是为了理解方便),其中内层的Integer为这两个Node的邻接次数,这样可以在一些删除重复边的情况下忽略其影响。
在使用优先队列时,实际上可以用一种更简单的方式进行初始化。我的优先队列中存储的均为AbstractMap.SimpleEntry<Node, Distance>的形式,故堆的比较依据为该SimpleEntry的value。此处可以使用Java 1.8中新增的双冒号写法以简化代码:
PriorityQueue<SimpleEntry<Integer, Integer>> remainDist = new PriorityQueue<>(Comparator.comparingInt(SimpleEntry::getValue));
计算所有的距离后,所有新增的查操作都可以通过判断两点之间距离的方式达成。需要注意的一点是,有些结点可能存在自环,所以对这样的结点判断自己和自己间是否存在边时应返回true。因此,需要维护一个记录存在自环的结点的数据结构。
本次作业的UML类图如下:
5.2.2 出错分析
本次作业强测满分。高工不参加互测。
值得一提的是,由于作业中需要进行n次SSSP计算全图距离,所以原本的想法是建立一个线程池,多线程运行这些Dijkstra算法。然而,线程池全部线程运行结束的判断比较复杂,再加上需要优化的并非实际运行时间而是CPU时间,所以在发现错误之后果断地回归了单线程模式。
5.3 第十一次作业
5.3.1 实现方案
本次作业中将Graph升级为了需要计算换乘距离/连通分量个数的RailwaySystem。原本``Path和Graph`的操作依然保持不变。本次作业我依然错误地没有使用继承,检讨检讨。
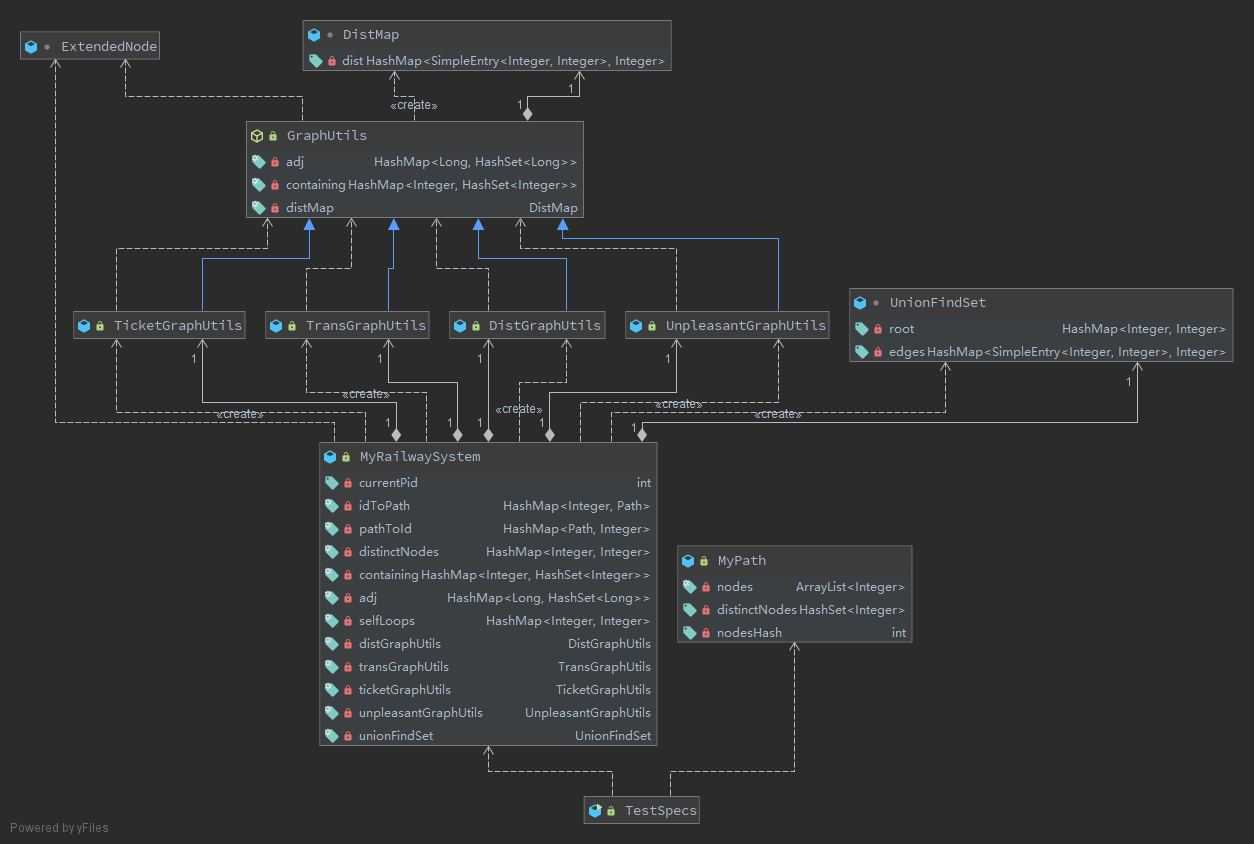
本次作业新增了三种需要考虑线路换乘的距离计算问题,这三种问题实质上使用的是同一种算法,不一样的只有边权和换乘权重。因此,我将先前的图计算类GraphUtils改造为了一个抽象类,保留了Dijkstra算法,而边权和换乘权重变为了两个抽象方法normalCost()和transferCost(),而不同的距离计算只需要新建不同的图计算子类override这两个方法即可。
为了解决线路换乘的判断问题,我采用了拆点法,将不同线路上的相同节点视为不同结点,这样每个点的邻接点被分为两类:在同一条Path上的相邻点和在不同Path上的相同点。为此,需要:
- 对点进行扩展编号,在其中保存点编号和线路号两重信息;
- 对每个点记录其所在的Path集合方便遍历;
- 邻接表中存储的均为点的扩展编号,只有在同一Path上相邻的点才在邻接表中进行记录。
对于扩展编号,我采用了一些小trick。由于增删Path的指令最多只有50个,因此,不需要建立复杂的数据结构,只需要通过一个最低三位记录线路号,高位记录节点号的long类型数即可。我建立了静态类ExtendedNode,通过(long) nodeId * 100 + pathId的方法获得扩展编号;从扩展编号逆推原来的点编号和路径号时,只需进行除100或模100操作即可,省去了很多IO时间。
相比于上一次作业每做一次增删路径操作都重新计算全图的所有距离,本次我采用了查一个算一个的策略,发现所查询距离没有时则跑一次对应图的SSSP,也可以节省一些时间。
对于连通分量个数,采用带路径压缩的并查集完成。在删除结点后,需要重新对并查集进行计算。
本次作业的UML类图如下:
5.3.2 出错分析
本次作业强测满分。高工不参加互测。出乎意料的是这次作业居然是弱测带强测一次过,或许是这种清晰的继承结构带来的方便吧。
六、感想
在第一单元时,我就听闻单元测试对于程序验证的重要性,然而单元测试从何开始设计一直都是我的困惑。在接触了规格之后,这一问题得到了解决:单元测试应该是面向一个模块应该完成的所有工作的,而规格刚好为测试的设计提供了依据。有了规格之后,无论是单元测试还是场景测试都能很快地定位到出错位置。
此外,规格还能成为顶层设计与底层实现之间的桥梁。在开发大型项目时,设计架构过后需要将任务分摊到每个不同的模块中,撰写代码规格有助于理清每个模块所需实现的功能,从而更好地耦合;而程序员则不需要考虑模块与模块之间的调用逻辑,只需要想办法完整实现规格即可。
同时,在我看来规格也是依赖反转的体现之一。实际上方法的调用者需要的是一个被调方法的功能,而不关心其背后的具体实现,这有点类似于接口的用处。有了规格之后,背后的实现方式的更新或是算法的优化都有了不出错的保证(实际上是根据规格所撰写的完整的单元测试保证了这样的改写依然有效)。
在本次作业中,由于指导书的描述和函数名已经给予了足够清晰的函数功能定义,所以实际上并不需要完全理解规格的内涵就可以完成任务,这样看来应该是程序文档对程序员的帮助更大一些,毕竟自然语言更贴合人的思维。然而,规格的规范性能够让程序设计者明确一些边界情况应该如何处理,以及多数情况下规格本身就是一个方法功能的最简单实现,有了文档和规格的双重保证才能让程序设计者能够更快更好地实现功能。
规格的撰写的确是一大难事,有很大一部分原因是JML规格并没有提供代码高亮和自动补全,而JML Editing插件也是在写本次总结的时候才了解到的,所以每敲一下键盘都要怀疑自己写的对不对,甚至括号匹配都会成一个大问题。不过JML的优势在于其贴近Java的语法,所以抱着用最浅显的算法去实现功能的想法反而能很容易地写出规格。
最后需要吐槽一下JML的工具链:除了OpenJML依然在持续更新外,其他工具都已经完全跟不上时代了,甚至还有JMLUnitNG这种历史悠久的半成品直接发布出来让人用,实在是体验极差。这次博客的撰写比之前任何一次代码作业都让人崩溃,其中数次想要放弃,但依然坚持住跑完了所有工具,实属不易。(在这里感谢湊あくあ等国际友人在这些天里提供的精神支持)或许这说明了契约式设计并不是当前的主流设计模式,诸如利用assert进行契约规范或是TTD等模式要比撰写复杂而不易懂的规范来的简单直接的多。
最后感谢此次讨论区的各位算法dalao提供的算法思路,这次由于没对问题分析透彻的缘故,在讨论区提供了一个错误的算法,还好及时发现了错误。这样的探究在当下还是有意义的,让我对SSSP问题有了更清晰的认识。同时也感谢此次提供了各种JML相关工具的dalao,没有你们这篇博客也就不会是这个样子了。