学习日志-2021.10.24
硕士论文第二部分复现
复杂网络上的合作行为演化研究 ——基于 Q-learning 算法
源码地址:RL_for_Gaming_to_choose_action(Q-Learning)
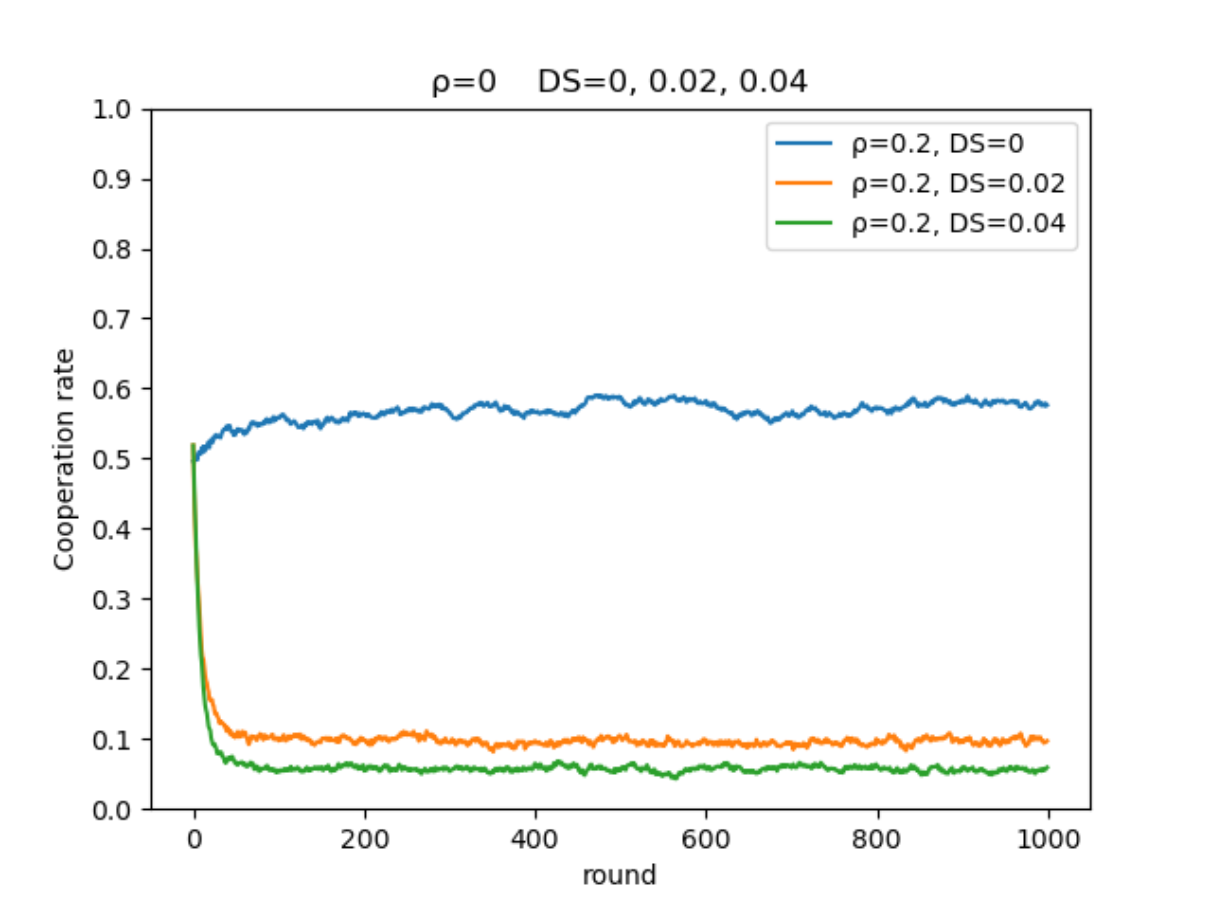
在相同智能体比例,不同困境强度下的演化:
- 合作率演化图:
-
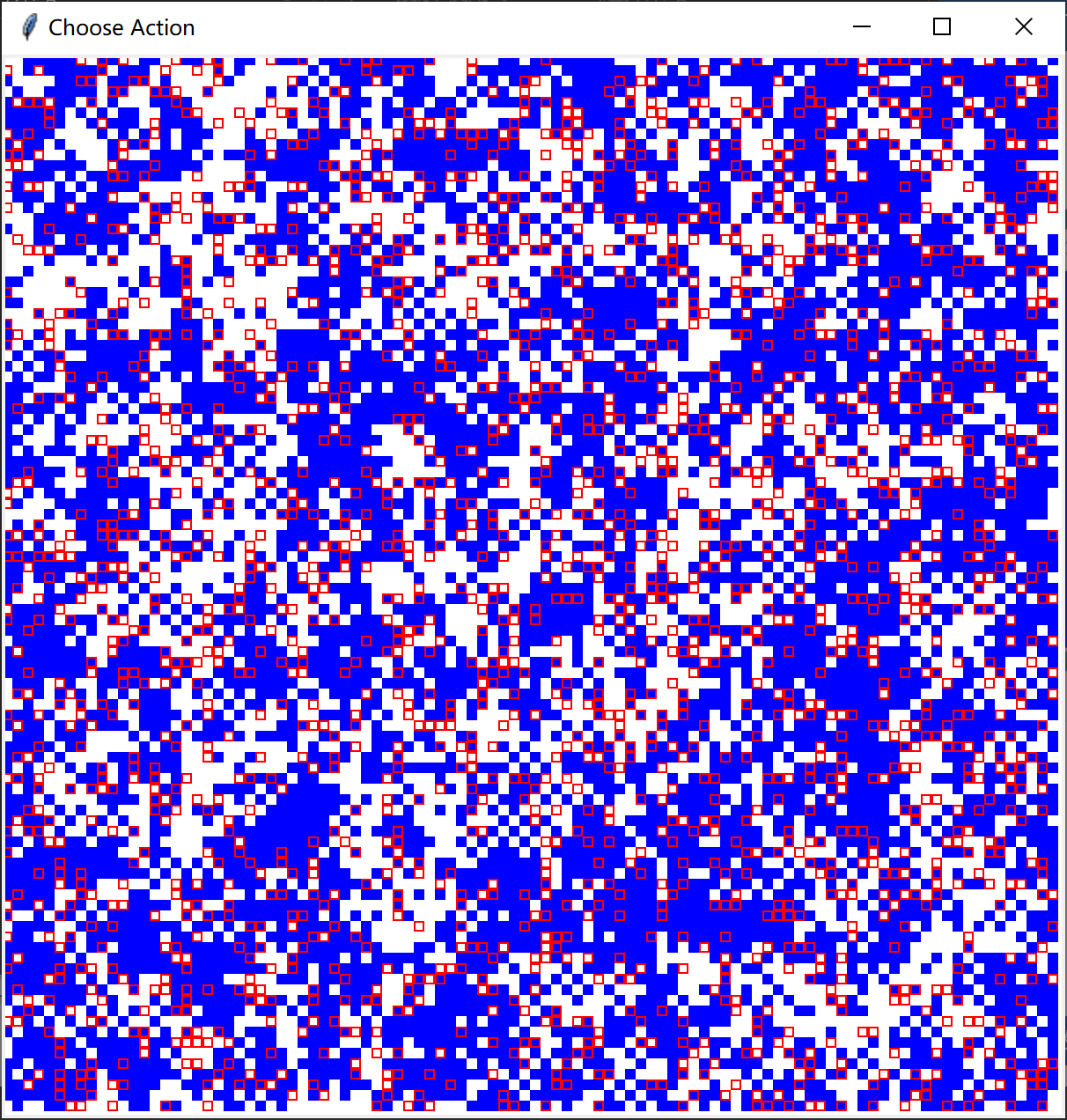
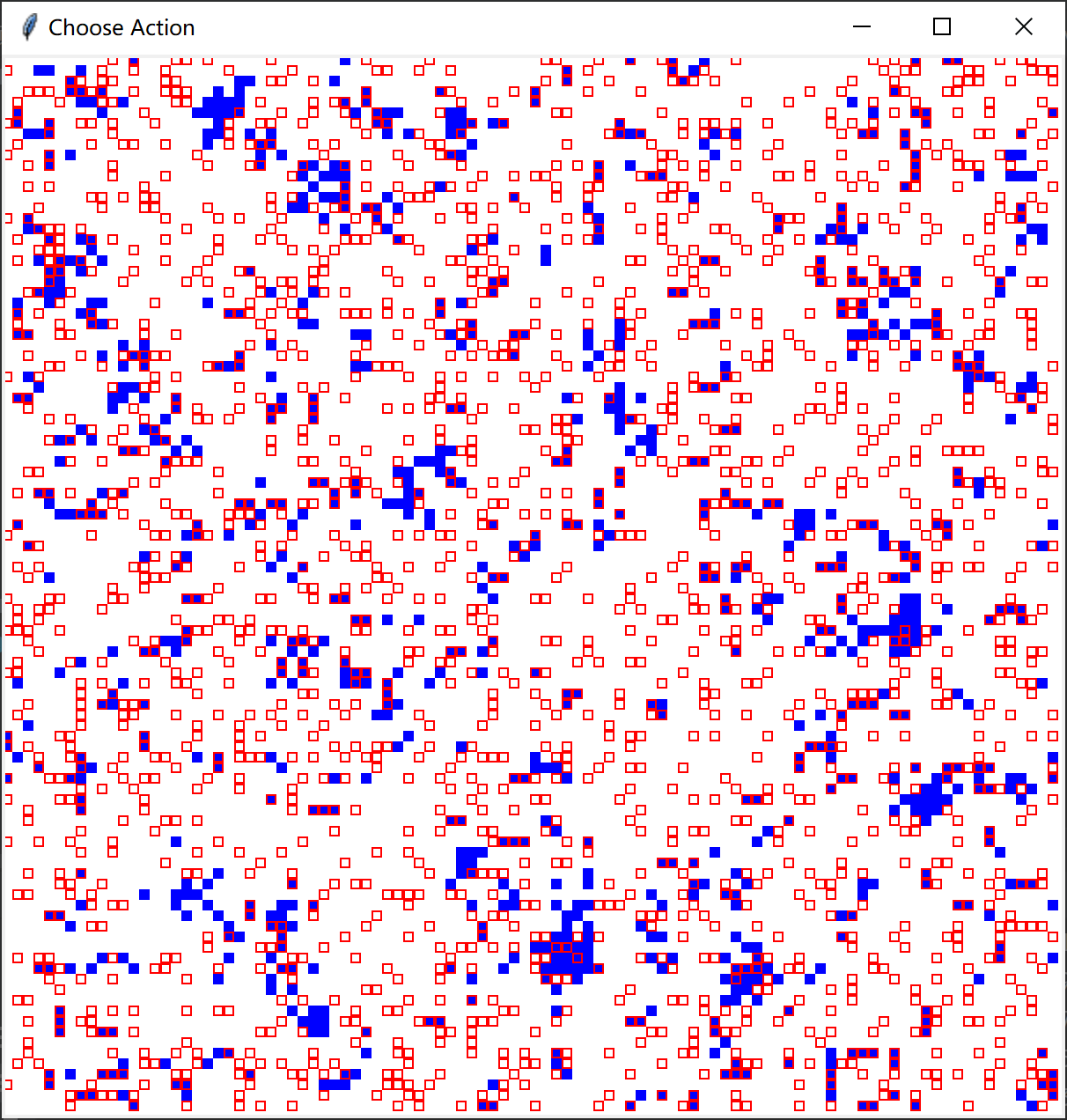
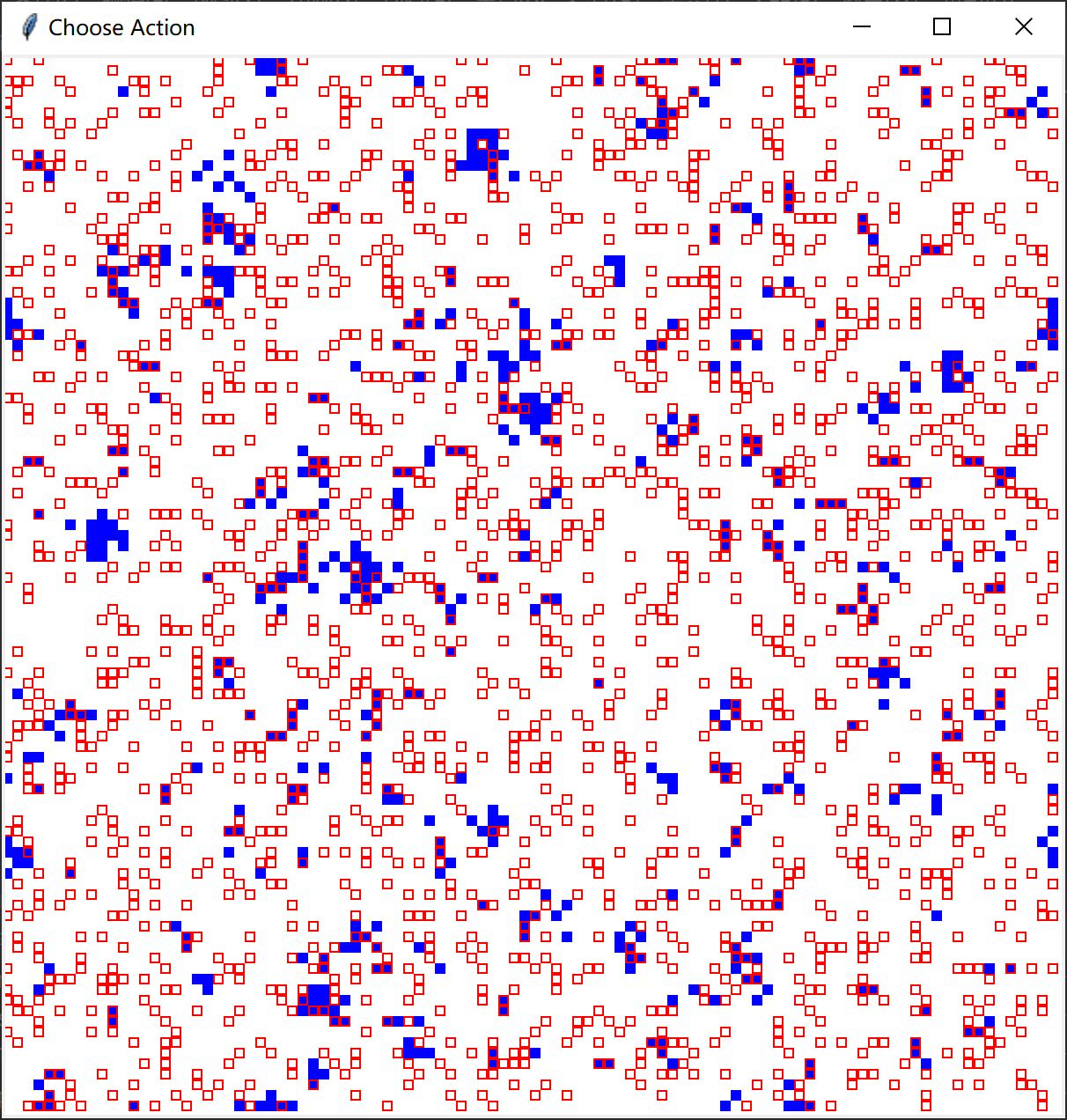
从左至右困境强度 ((DS))分别为0、0.02、0.04演化后的最终结果:
图中方块边缘为红色代表为智能体(占比约为0.2)
智能体使用Q-Learning决定策略,非智能体使用费米更新规则决定策略(阈值为 ([0,1]) 上的随机数,模拟均匀分布)
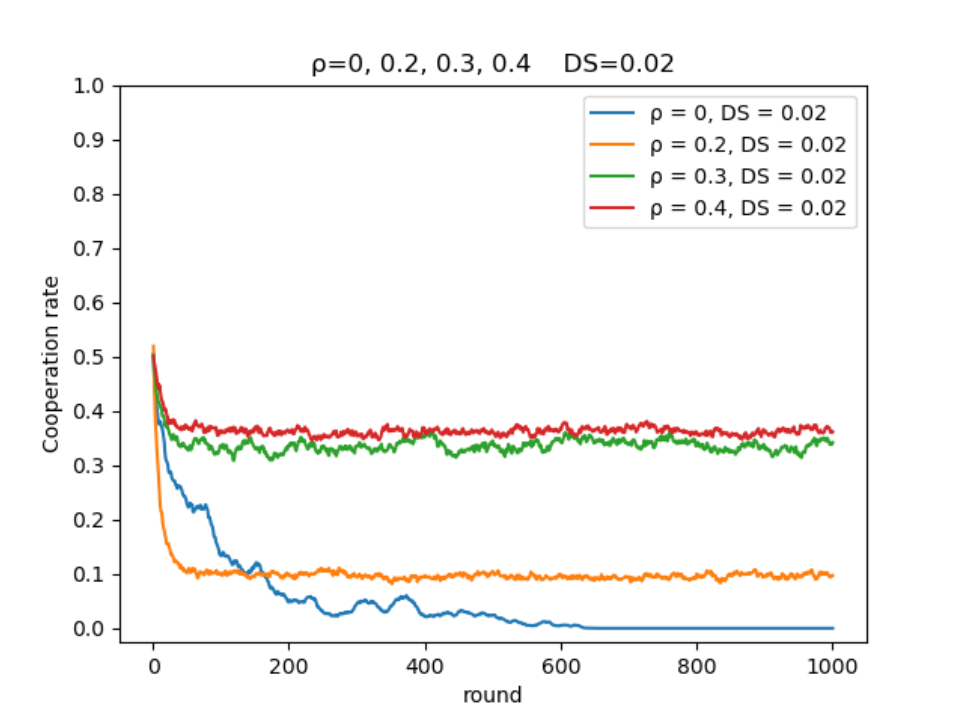
在不同智能体比例,相同困境强度下的演化:
- 根据仿真结果智能体占比的提高在一定范围内会使合作率提高,根据论文内容的描述在智能体比例达到0.7时,合作率会达到最高水平。
结果分析
- 本次仿真使用的网络规模为 (100×100) ,进行的轮次为1000轮,论文中的规模为 (200×200) ,进行的轮次为1000000次。可能由于本次仿真设置的轮次较少,并没有观察到后续合作率曲线上升的过程,分析原因可能是使用Q-Learning算法的智能体可能还处在“学习阶段”,智能体的Q表还未收敛。
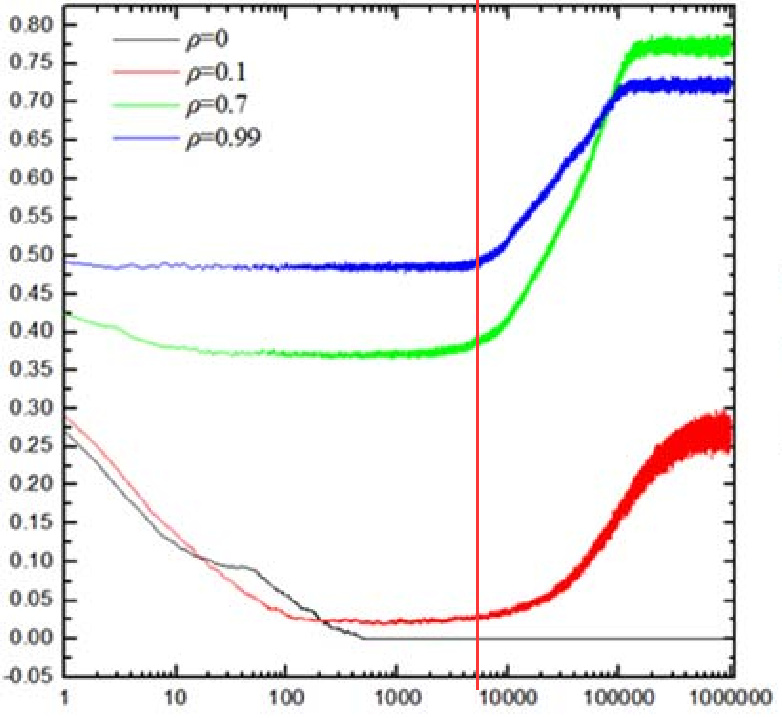
- 虽然并没有完美地复现出论文内容,但也可以得出:在一定范围内,随着使用Q-Learning算法智能体占比的提升,网络的合作率也会随之提升。