通用的线程生命周期基本上可以用下图这个“五态模型”来描述。这五态分别是:初始状态、可运行状态、运行状态、休眠状态和终止状态。
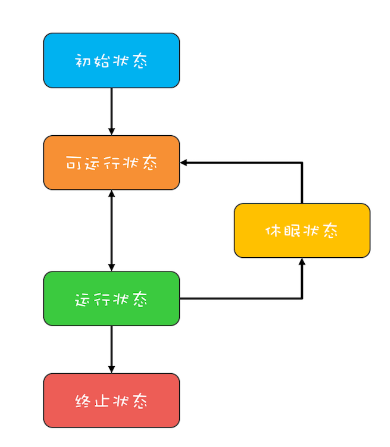
- 初始状态,指的是线程已经被创建,但是还不允许分配 CPU 执行。这个状态属于编程语言特有的,不过这里所谓的被创建,仅仅是在编程语言层面被创建,而在操作系统层面,真正的线程还没有创建。
- 可运行状态,指的是线程可以分配 CPU 执行。在这种状态下,真正的操作系统线程已经被成功创建了,所以可以分配 CPU 执行。
- 当有空闲的 CPU 时,操作系统会将其分配给一个处于可运行状态的线程,被分配到 CPU 的线程的状态就转换成了运行状态。
- 运行状态的线程如果调用一个阻塞的 API(例如以阻塞方式读文件)或者等待某个事件(例如条件变量),那么线程的状态就会转换到休眠状态,同时释放 CPU 使用权,休眠状态的线程永远没有机会获得 CPU 使用权。当等待的事件出现了,线程就会从休眠状态转换到可运行状态。
- 线程执行完或者出现异常就会进入终止状态,终止状态的线程不会切换到其他任何状态,进入终止状态也就意味着线程的生命周期结束了。
Java 中线程的生命周期
Java 语言中线程共有六种状态,分别是:NEW(初始化状态)RUNNABLE(可运行 / 运行状态)BLOCKED(阻塞状态)WAITING(无时限等待)TIMED_WAITING(有时限等待)TERMINATED(终止状态)
BLOCKED(阻塞状态)WAITING(无时限等待)TIMED_WAITING(有时限等待)对应的就是上面的休眠状态
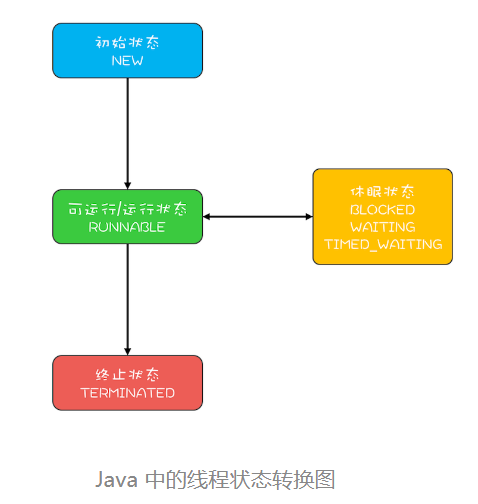
1. RUNNABLE 与 BLOCKED 的状态转换
只有一种场景会触发这种转换,就是线程等待 synchronized 的隐式锁。synchronized 修饰的方法、代码块同一时刻只允许一个线程执行,其他线程只能等待,这种情况下,等待的线程就会从 RUNNABLE 转换到 BLOCKED 状态。而当等待的线程获得 synchronized 隐式锁时,就又会从 BLOCKED 转换到 RUNNABLE 状态。
这个状态只针对JVM,在JVM眼中等待CPU和进行IO操作都是一样的,都属于RUNABLE状态
2. RUNNABLE 与 WAITING 的状态转换
第一种场景,获得 synchronized 隐式锁的线程,调用无参数的 Object.wait() 方法。会进入等待队列
第二种场景,调用无参数的 Thread.join() 方法。其中的 join() 是一种线程同步方法,例如有一个线程对象 thread A,当调用 A.join() 的时候,执行这条语句的线程会等待 thread A 执行完,而等待中的这个线程,其状态会从 RUNNABLE 转换到 WAITING。当线程 thread A 执行完,原来等待它的线程又会从 WAITING 状态转换到 RUNNABLE。
第三种场景,调用 LockSupport.park() 方法。其中的 LockSupport 对象,也许你有点陌生,其实 Java 并发包中的锁,都是基于它实现的。调用 LockSupport.park() 方法,当前线程会阻塞,线程的状态会从 RUNNABLE 转换到 WAITING。调用 LockSupport.unpark(Thread thread) 可唤醒目标线程,目标线程的状态又会从 WAITING 状态转换到 RUNNABLE。
3. RUNNABLE 与 TIMED_WAITING 的状态转换
调用带超时参数的 Thread.sleep(long millis) 方法;
获得 synchronized 隐式锁的线程,调用带超时参数的 Object.wait(long timeout) 方法;
调用带超时参数的 Thread.join(long millis) 方法;
调用带超时参数的 LockSupport.parkNanos(Object blocker, long deadline) 方法;
调用带超时参数的 LockSupport.parkUntil(long deadline) 方法。
这里你会发现 TIMED_WAITING 和 WAITING 状态的区别,仅仅是触发条件多了超时参数。
4. 从 RUNNABLE 到 TERMINATED 状态
线程执行完 run() 方法后,会自动转换到 TERMINATED 状态,当然如果执行 run() 方法的时候异常抛出,也会导致线程终止。有时候我们需要强制中断 run() 方法的执行,例如 run() 方法访问一个很慢的网络,我们等不下去了,想终止怎么办呢?Java 的 Thread 类里面倒是有个 stop() 方法,不过已经标记为 @Deprecated,所以不建议使用了。正确的姿势其实是调用 interrupt() 方法。
stop() 方法会真的杀死线程,不给线程喘息的机会,如果线程持有 ReentrantLock 锁,被 stop() 的线程并不会自动调用 ReentrantLock 的 unlock() 去释放锁,那其他线程就再也没机会获得 ReentrantLock 锁,但是隐式锁可以被释放。
interrupt() 方法仅仅是通知线程,线程有机会执行一些后续操作,同时也可以无视这个通知。被 interrupt 的线程,是怎么收到通知的呢?一种是异常,另一种是主动检测。
当线程 A 处于 WAITING、TIMED_WAITING 状态时,如果其他线程调用线程 A 的 interrupt() 方法,会使线程 A 返回到 RUNNABLE 状态,同时线程 A 的代码会触发 InterruptedException 异常。上面我们提到转换到 WAITING、TIMED_WAITING 状态的触发条件,都是调用了类似 wait()、join()、sleep() 这样的方法,我们看这些方法的签名,发现都会 throws InterruptedException 这个异常。这个异常的触发条件就是:其他线程调用了该线程的 interrupt() 方法。
public void interrupt() {
//安全检测
if (this != Thread.currentThread())
checkAccess();
//互斥锁来实现
synchronized (blockerLock) {
Interruptible b = blocker;
if (b != null) {
interrupt0(); // Just to set the interrupt flag
b.interrupt(this);
return;
}
}
interrupt0();
}
还有一种是主动检测,如果线程处于 RUNNABLE 状态,并且没有阻塞在某个 I/O 操作上,例如中断计算圆周率的线程 A,这时就得依赖线程 A 主动检测中断状态了。如果其他线程调用线程 A 的 interrupt() 方法,那么线程 A 可以通过 isInterrupted() 方法,检测是不是自己被中断了。
public class demo9 implements Runnable {
@Override
public void run() {
System.out.println("进入了多线程模式");
Thread th = Thread.currentThread();
while (true){
if(th.isInterrupted()) {
break;
}
System.out.println("进入了循环体");
try {
Thread.sleep(100);
}catch (InterruptedException e){
Thread.currentThread().interrupt();
System.out.println("进行了中断");
e.printStackTrace();
}
}
}
public static void main(String[] args) {
demo9 demo9 = new demo9();
Thread thread = new Thread(demo9);
thread.start();
for (int i = 0; i < 1000000; i++) {
int j = i;
System.out.println(j);
}
thread.interrupt();
}
}
//
进行了中断
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at demo9.run(demo9.java:19)
at java.lang.Thread.run(Thread.java:748)
创建多少线程合适?
首先要思考为什么要使用多线程?多线程的应用场景有哪些?
如何度量性能?
提到多线程一般的想法就是快,那么快在哪里呢?
下面一段代码比较下,这是还没有加锁的情况下
public class demo10 implements Runnable {
int i = 0;
@Override
public void run() {
while (i<1000000){
i++;
System.out.println(Thread.currentThread().getName() + " "+i);
}
}
public static void main(String[] args) throws InterruptedException {
demo10 demo10 = new demo10();
Thread A = new Thread(demo10);
Thread B = new Thread(demo10);
long startMili=System.currentTimeMillis();
A.start();
B.start();
A.join();
B.join();
long endMili=System.currentTimeMillis();
System.out.println("/**总耗时为:"+(endMili-startMili)+"毫秒");
}
}
/**总耗时为:8359毫秒
单线程情况下:
/**总耗时为:6644毫秒
也就是说多线程不一定会比单线快,问题在于这是要个CPU密集型,全程都在进行计算,进行上下文切换反而会拉低性能,如果再加锁就更加慢。
度量性能的指标有很多,但是有两个指标是最核心的,它们就是延迟和吞吐量。延迟指的是发出请求到收到响应这个过程的时间;延迟越短,意味着程序执行得越快,性能也就越好。 吞吐量指的是在单位时间内能处理请求的数量;吞吐量越大,意味着程序能处理的请求越多,性能也就越好。这两个指标内部有一定的联系(同等条件下,延迟越短,吞吐量越大),但是由于它们隶属不同的维度(一个是时间维度,一个是空间维度),并不能互相转换。
延迟和吞吐量在极限情况下应该是对冲的,延迟低。10核同时计算,那么吞吐量就会低。目的是处于一个平衡的状态。
要想“降低延迟,提高吞吐量”,对应的方法呢,基本上有两个方向,一个方向是优化算法,另一个方向是将硬件的性能发挥到极致。前者属于算法范畴,后者则是和并发编程息息相关了。那计算机主要有哪些硬件呢?主要是两类:一个是 I/O,一个是 CPU。简言之,在并发编程领域,提升性能本质上就是提升硬件的利用率,再具体点来说,就是提升 I/O 的利用率和 CPU 的利用率。
再看上面的例子,如果一个任务是多次IO的,如下图,那么使用多线程的作用还是比较显著的,蓝色的部分可以执行别的任务。对于蓝色部分越长,效果则越好。但是凡是不绝对,如果上面的代码是在多核情况下拆分计算的,线程A计算1到50000,B计算50001到100000。那么就会快。
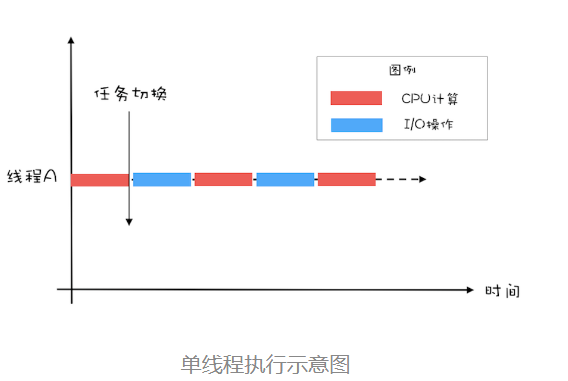
创建多少线程合适,要看多线程具体的应用场景。我们的程序一般都是 CPU 计算和 I/O 操作交叉执行的,由于 I/O 设备的速度相对于 CPU 来说都很慢,所以大部分情况下,I/O 操作执行的时间相对于 CPU 计算来说都非常长,这种场景我们一般都称为 I/O 密集型计算;和 I/O 密集型计算相对的就是 CPU 密集型计算了,CPU 密集型计算大部分场景下都是纯 CPU 计算。I/O 密集型程序和 CPU 密集型程序,计算最佳线程数的方法是不同的。
对于 CPU 密集型计算,多线程本质上是提升多核 CPU 的利用率,所以对于一个 4 核的 CPU,每个核一个线程,理论上创建 4 个线程就可以了,再多创建线程也只是增加线程切换的成本。所以,对于 CPU 密集型的计算场景,理论上“线程的数量 =CPU 核数”就是最合适的。不过在工程上,线程的数量一般会设置为“CPU 核数 +1”,这样的话,当线程因为偶尔的内存页失效或其他原因导致阻塞时,这个额外的线程可以顶上,从而保证 CPU 的利用率。
对于 I/O 密集型的计算场景,比如前面我们的例子中,如果 CPU 计算和 I/O 操作的耗时是 1:1,那么 2 个线程是最合适的。如果 CPU 计算和 I/O 操作的耗时是 1:2,那多少个线程合适呢?是 3 个线程,如下图所示:CPU 在 A、B、C 三个线程之间切换,对于线程 A,当 CPU 从 B、C 切换回来时,线程 A 正好执行完 I/O 操作。这样 CPU 和 I/O 设备的利用率都达到了 100%。
最佳线程数 =1 +(I/O 耗时 / CPU 耗时)