写在最前面,本文完全基于 【网络爬虫】爬取神奇宝贝Pokemon图鉴图片大全 编写
前言
最近在学习Vue.js和微信小程序,作为实践,决定用uni-app以vue.js的方式写微信小程序,加上最近在switch上玩“数码宝贝网络侦探骇客追忆”,发现还没有和口袋妖怪一样的图鉴小程序,决定做一个“数码宝贝图鉴”小程序,苦于没有数据也没有图片,决定现场学习python,自己去数码兽数据库爬数据。
效果图
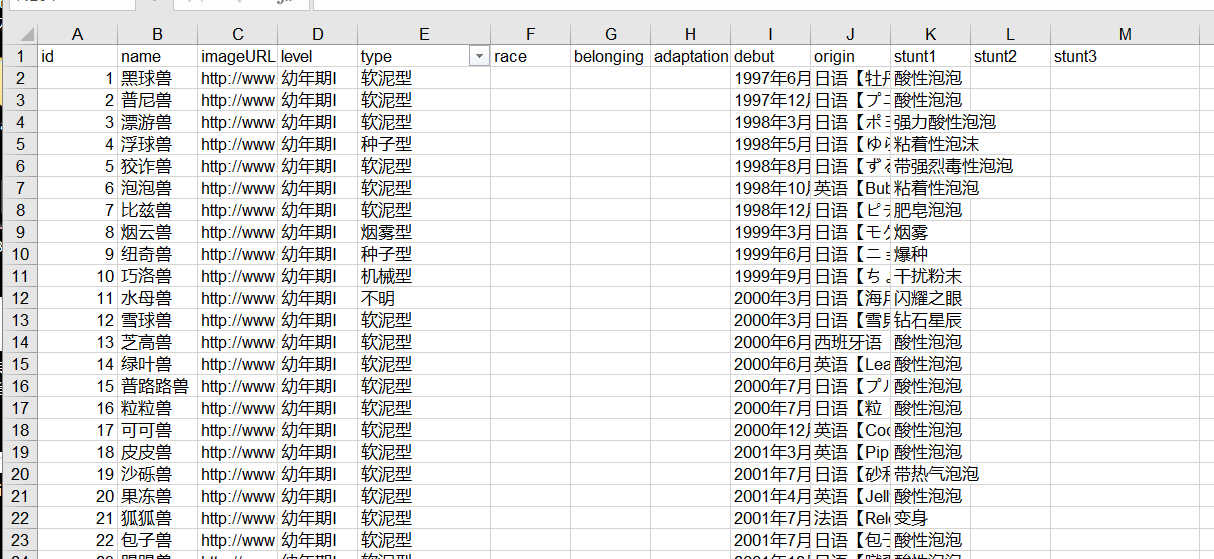
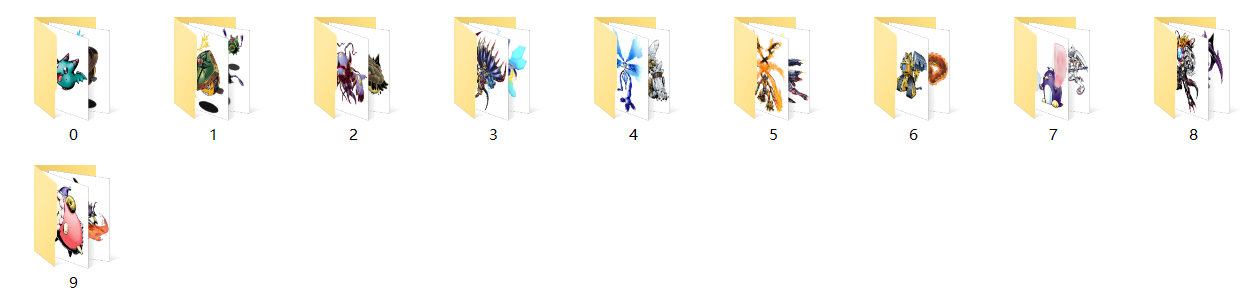
准备工作
- 学习Python基本语法,学习地点 Python基础教程
- 了解爬虫方式、库,直接从【网络爬虫】爬取神奇宝贝Pokemon图鉴图片大全中的代码看着学习,结合 Python爬虫实战教程:批量爬取某网站图片的视频来综合改进
- 请教已有的图鉴类小程序的创作者,特别鸣谢微信小程序“FGO素材规划”作者,问了才知道数据都是自己去找的,没有API
代码
由于是第一次写Python,第一次写爬虫,可能下载慢,可能内存爆掉,见谅
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
from xlwt import Workbook
import requests
import os
class downloader(object):
def __init__(self):
self.target = r'http://www.digimons.net/digimon/chn.html' # 首页
self.root = 'http://www.digimons.net/digimon/' # 数码兽们的根目录
self.digimon = [] # 存放数码宝贝名和属性
self.names = [] # 数码宝贝的名字
self.urls = [] # 数码宝贝的链接
self.level = [] # 数码宝贝的等级
self.divs = [] # 不同等级的class属性
self.palces = ['幼年期Ⅰ', '幼年期Ⅱ', '成长期', '成熟期',
'完全体', '究极体', '装甲体', '混合体', '不明', '无(-)']
self.levelClass = ['c_1','c_2','c_3','c_4','c_5','c_6','c_7','c_8','c_9','c_10']
self.image = [] # 数码宝贝的图片地址
self.down = [] # 图片地址及编号
self.datas = [] # 数码宝贝数据
self.tableName = 'digimons'
self.tableHeader = ['序号', '名字', '图片链接', '等级', '类型',
'属性', '所属', '适应领域', '首次登场', '名字来源', '必杀技1', '必杀技2']
def first_process(self):
r = requests.get(self.target)
r.encoding = r.apparent_encoding
html = r.text
div_bf = BeautifulSoup(html, features='html.parser')
for place in self.palces:
if place == self.palces[0]:
name = self.levelClass[0]
elif place == self.palces[1]:
name = self.levelClass[1]
elif place == self.palces[2]:
name = self.levelClass[2]
elif place == self.palces[3]:
name = self.levelClass[3]
elif place == self.palces[4]:
name = self.levelClass[4]
elif place == self.palces[5]:
name = self.levelClass[5]
elif place == self.palces[6]:
name = self.levelClass[6]
elif place == self.palces[7]:
name = self.levelClass[7]
elif place == self.palces[8]:
name = self.levelClass[8]
else:
name = self.levelClass[9]
self.divs.append(div_bf.find_all('li', class_=name))
print("等级共有:", len(self.divs))
self.get_Pokemon()
def get_digimon_data(self):
k = 0
for i, url in enumerate(self.urls):
try:
k = k+1
print('获取图片地址中…… {}%'.format(k*100/len(self.urls)), end='
')
r = requests.get(url[0])
r.encoding = r.apparent_encoding
html = r.text
div_bf = BeautifulSoup(html, features='html.parser')
# 获取页面资源完毕,获取图片链接开始
imageDiv = div_bf.find('div', class_='digimon_img')
image = imageDiv.find('img')
if image == None:
print(url[1], "没找到图片")
image_address = url[0][0:url[0].rfind(
'/')+1] + image.get('src')
self.image.append((image_address, url[1]))
self.down.append((image_address, k-1))
# 获取图片链接完毕,获取数据资源开始
datas = div_bf.find_all('tr')
tmp_datas = []
for i in range(len(datas)):
tmp_datas.append(datas[i].find('td').get_text())
self.datas.append(tmp_datas)
except Exception as e:
print(e)
with open('urls.txt', 'w') as f:
for item in self.down:
f.write(str(item) + '
')
def get_Pokemon(self):
print("get_Pokemon")
for index, adiv in enumerate(self.divs):
l = []
k = 0
if(index == 0):
level = self.palces[0]
elif(index == 1):
level = self.palces[1]
elif(index == 2):
level = self.palces[2]
elif(index == 3):
level = self.palces[3]
elif(index == 4):
level = self.palces[4]
elif(index == 5):
level = self.palces[5]
elif(index == 6):
level = self.palces[6]
elif(index == 7):
level = self.palces[7]
elif(index == 8):
level = self.palces[8]
else:
level = '"数码兽第六部"'
print('获取 '+level+' 数码宝贝信息中')
for li in adiv:
# print('获取'+level+'数码宝贝信息中…… {} %'.format(k*100/len(adiv)), end='
')
k = k+1
tmp = []
tmp_url = []
tmp_level = []
label = li('a')
tmp.append(label[0].get_text())
tmp_url.append(label[0].get('href'))
tmp_level.append(level)
l.append(tmp)
try:
if tmp[0] not in self.palces and tmp[0] != None:
self.urls.append((self.root + tmp_url[0], tmp[0]))
self.level.append(index)
self.names.append(tmp[0])
except Exception as e:
print(e)
self.digimon.extend(l)
print("数码宝贝总数:", len(self.digimon))
print("url数:", len(self.urls))
self.get_digimon_data()
with open('names.txt', 'w') as f:
for item in self.names:
f.write(item+'
')
print(len(self.image))
def get_image(self):
print("获取图片中")
imageRoot = './image'
k = 0
for index, url in enumerate(self.image):
k = k+1
address = url[0]
name = url[1]
levelPath = imageRoot + '/' + str(self.level[index])
picture = levelPath + '/' + name + '.jpg'
try:
if not os.path.exists(imageRoot):
os.mkdir(imageRoot)
if not os.path.exists(levelPath):
os.mkdir(levelPath)
if not os.path.exists(picture):
r = requests.get(address)
with open(picture, 'wb') as f:
f.write(r.content)
print('图片保存成功,{}%'.format(k*100/len(self.image)))
else:
print('文件已存在')
except Exception:
print('爬取失败')
def save_as_xlsx(self):
# TODO 解决“必须当前没有digimons.xls才可以保存”的问题
print("保存数码宝贝数据中")
file = Workbook(encoding='utf-8')
table = file.add_sheet(self.tableName)
for i, item in enumerate(self.tableHeader):
table.write(0, i, item)
for i, data in enumerate(self.datas):
table.write(i+1, 0, i+1)
table.write(i+1, 1, self.names[i])
table.write(i+1, 2, self.down[i][0])
for j, cell in enumerate(data):
table.write(i+1, j+3, cell)
file.save(self.tableName+'.xls')
if __name__ == "__main__":
target = downloader()
target.first_process()
target.get_image()
target.save_as_xlsx()
这里使用了beautifulsoup来解析网页
分析
我决定按照等级(成长期、完全体等)把数码宝贝分类,而不是按照网页里的首次登场年份分类
分析网页
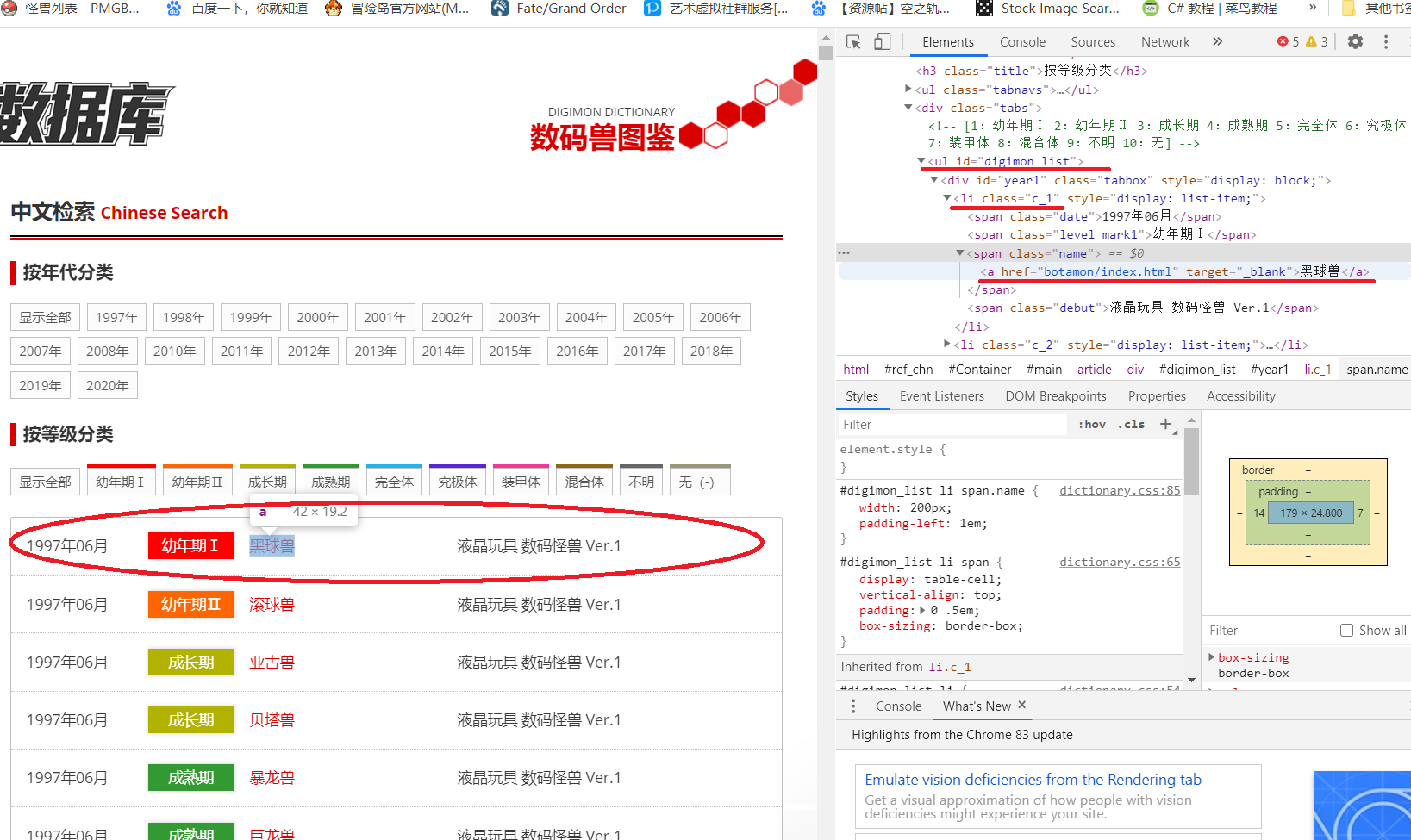
可以看到,所有数码宝贝都放在了一个 id="digimon_list"的ul里,按照年份分成了一个个块,每一个数码宝贝都在li标签中,li标签里的class属性保存了数码兽的等级,a标签里保存了这个数码兽的详细链接和名字。
所以我们首先要得到id="digimon_list"的ul标签,在其中找到所有的li标签,在li标签中找到数码兽的详细链接、名字、等级。我们进入到数码兽详细页面
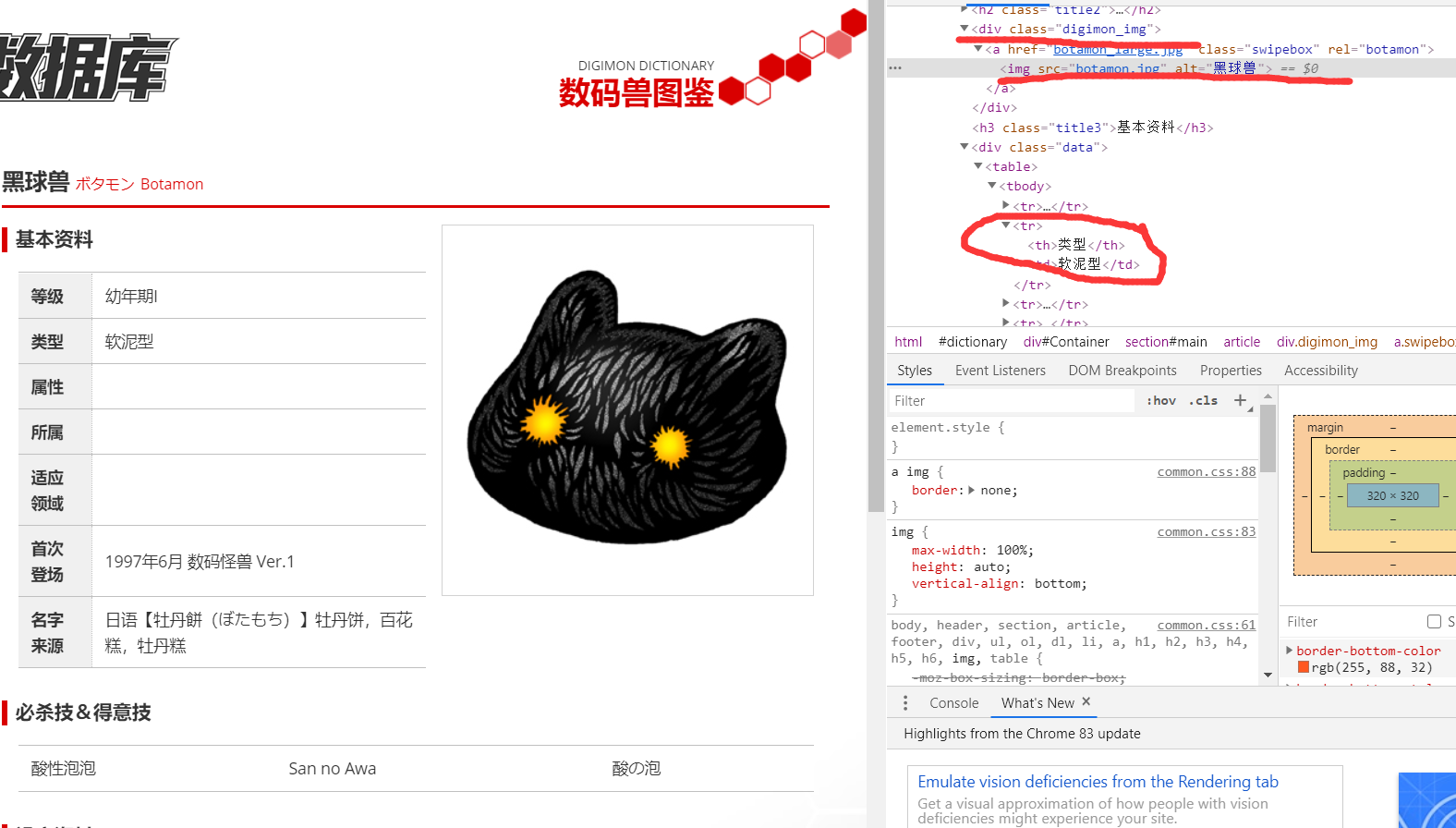
可以看到,数码兽图片链接放在了id="digimon_img"的div里的img标签里,然后所有信息都放在tr标签里,所以我们页面里的相应div和tr就可以了。
步骤
- 解析主页,获取数码宝贝列表里各自单独的详细资料链接
- 分别解析数码宝贝图片地址,各种资料
- 下载图片并保存
- 保存资料和图片链接
总结
通过各种百度,玩玩自己想做的东西还挺开心的。
参考资料
- 【网络爬虫】爬取神奇宝贝Pokemon图鉴图片大全 by.Memory逆光
- 数码兽数据库(数据来源)
- Python基础教程
- Python爬虫实战教程:批量爬取某网站图片 UP-python学习者