参考官网:
https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/table/connectors/kafka.html
https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/table/connectors/upsert-kafka.html
Flink 1.12.0 已经发布了有一段时间了, 这段时间都比较忙,很少尝试新版本的功能,之前升级,只是修改了 flink 的版本号,把一些报错、不适用的代码从项目中移除,一直没有试用新的功能,今天刚好试用下 upsert-kafka connector,之前每个版本都自己实现,也是麻烦。
使用 sqlSubmit 提交之前的 kafka upsert sql
CREATE TABLE user_log ( user_id VARCHAR ,item_id VARCHAR ,category_id VARCHAR ,behavior VARCHAR ,ts TIMESTAMP(3) ) WITH ( 'connector.type' = 'kafka' ,'connector.version' = 'universal' ,'connector.topic' = 'user_behavior' ,'connector.properties.zookeeper.connect' = 'localhost:2181' ,'connector.properties.bootstrap.servers' = 'localhost:9092' ,'connector.properties.group.id' = 'user_log' ,'connector.startup-mode' = 'group-offsets' ,'connector.sink-partitioner' = 'fixed' ,'format.type' = 'json' ) CREATE TABLE user_log_sink ( user_id VARCHAR ,max_tx BIGINT ,primary key (user_id) not enforced ) WITH ( 'connector.type' = 'upsert-kafka' ,'connector.version' = 'universal' ,'connector.topic' = 'user_behavior_sink' ,'connector.properties.zookeeper.connect' = 'localhost:2181' ,'connector.properties.bootstrap.servers' = 'localhost:9092' ,'connector.properties.group.id' = 'user_log' ,'connector.startup-mode' = 'group-offsets' ,'connector.sink-partitioner' = 'fixed' ,'format.type' = 'json' )
执行 sql
~/sqlSubmit$ /opt/flink-1.12.0/bin/flink run -m yarn-cluster -ynm sqlDemo -c com.rookie.submit.main.SqlSubmit original-sqlSubmit-3.0.jar -sql ~/git/sqlSubmit/src/main/resources/sql/connector/kafka_upsert_demo.sql ------------------------------------------------------------ The program finished with the following exception: org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: findAndCreateTableSink failed. at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:330) at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:198) at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:114) at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:743) at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:242) at org.apache.flink.client.cli.CliFrontend.parseAndRun(CliFrontend.java:971) at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:1047) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729) at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1047) Caused by: org.apache.flink.table.api.TableException: findAndCreateTableSink failed. at org.apache.flink.table.factories.TableFactoryUtil.findAndCreateTableSink(TableFactoryUtil.java:94) at org.apache.flink.table.factories.TableFactoryUtil.lambda$findAndCreateTableSink$0(TableFactoryUtil.java:121) at java.util.Optional.orElseGet(Optional.java:267) at org.apache.flink.table.factories.TableFactoryUtil.findAndCreateTableSink(TableFactoryUtil.java:121) at org.apache.flink.table.planner.delegation.PlannerBase.getTableSink(PlannerBase.scala:353) at org.apache.flink.table.planner.delegation.PlannerBase.translateToRel(PlannerBase.scala:220) at org.apache.flink.table.planner.delegation.PlannerBase$$anonfun$1.apply(PlannerBase.scala:164) at org.apache.flink.table.planner.delegation.PlannerBase$$anonfun$1.apply(PlannerBase.scala:164) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.Iterator$class.foreach(Iterator.scala:891) at scala.collection.AbstractIterator.foreach(Iterator.scala:1334) at scala.collection.IterableLike$class.foreach(IterableLike.scala:72) at scala.collection.AbstractIterable.foreach(Iterable.scala:54) at scala.collection.TraversableLike$class.map(TraversableLike.scala:234) at scala.collection.AbstractTraversable.map(Traversable.scala:104) at org.apache.flink.table.planner.delegation.PlannerBase.translate(PlannerBase.scala:164) at org.apache.flink.table.api.internal.TableEnvironmentImpl.translate(TableEnvironmentImpl.java:1267) at org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:675) at org.apache.flink.table.api.internal.StatementSetImpl.execute(StatementSetImpl.java:97) at com.rookie.submit.main.SqlSubmit$.main(SqlSubmit.scala:89) at com.rookie.submit.main.SqlSubmit.main(SqlSubmit.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:316) ... 11 more Caused by: org.apache.flink.table.api.NoMatchingTableFactoryException: Could not find a suitable table factory for 'org.apache.flink.table.factories.TableSinkFactory' in the classpath. Reason: Required context properties mismatch. The matching candidates: org.apache.flink.streaming.connectors.kafka.KafkaTableSourceSinkFactory Mismatched properties: 'connector.type' expects 'kafka', but is 'upsert-kafka' The following properties are requested: connector.properties.bootstrap.servers=localhost:9092 connector.properties.group.id=user_log connector.properties.zookeeper.connect=localhost:2181 connector.sink-partitioner=fixed connector.startup-mode=group-offsets connector.topic=user_behavior_sink connector.type=upsert-kafka connector.version=universal format.type=json schema.0.data-type=VARCHAR(2147483647) NOT NULL schema.0.name=user_id schema.1.data-type=BIGINT schema.1.name=max_tx schema.primary-key.columns=user_id schema.primary-key.name=PK_-147132882 The following factories have been considered: org.apache.flink.streaming.connectors.kafka.KafkaTableSourceSinkFactory org.apache.flink.table.sinks.CsvBatchTableSinkFactory org.apache.flink.table.sinks.CsvAppendTableSinkFactory at org.apache.flink.table.factories.TableFactoryService.filterByContext(TableFactoryService.java:322) at org.apache.flink.table.factories.TableFactoryService.filter(TableFactoryService.java:190) at org.apache.flink.table.factories.TableFactoryService.findSingleInternal(TableFactoryService.java:143) at org.apache.flink.table.factories.TableFactoryService.find(TableFactoryService.java:96) at org.apache.flink.table.factories.TableFactoryUtil.findAndCreateTableSink(TableFactoryUtil.java:91) ... 37 more
竟然用了 KafkaTableSourceSinkFactory , 没有用 UpsertKafkaDynamicTableFactory
查看 flink lib 目录
/opt/flink-1.12.0/lib$ ls flink-connector-kafka_2.11-1.12.0.jar flink-dist_2.11-1.12.0.jar flink-shaded-zookeeper-3.4.14.jar flink-table-blink_2.11-1.12.0.jar log4j-1.2-api-2.12.1.jar log4j-core-2.12.1.jar flink-csv-1.12.0.jar flink-json-1.12.0.jar flink-table_2.11-1.12.0.jar kafka-clients-2.4.1.jar log4j-api-2.12.1.jar log4j-slf4j-impl-2.12.1.jar
flink-connector-kafka_2.11-1.12.0.jar 在里面啊
查看 jar 包里的 spi 文件, 在 flink-connector-kafka_2.11 中看到 2 个 文件
org.apache.flink.table.factories.Factory
org.apache.flink.streaming.connectors.kafka.table.KafkaDynamicTableFactory
org.apache.flink.streaming.connectors.kafka.table.UpsertKafkaDynamicTableFactory
org.apache.flink.table.factories.TableFactory
org.apache.flink.streaming.connectors.kafka.KafkaTableSourceSinkFactory
UpsertKafkaDynamicTableFactory 在文件中
本地 debug TableFactoryService 查看加载 factory 部分,发现只加载了 TableFactory, 没有加载 Factory , UpsertKafkaDynamicTableFactory 是 Factory 的子类:
private static List<TableFactory> discoverFactories(Optional<ClassLoader> classLoader) { try { List<TableFactory> result = new LinkedList<>(); ClassLoader cl = classLoader.orElse(Thread.currentThread().getContextClassLoader()); ServiceLoader .load(TableFactory.class, cl) .iterator() .forEachRemaining(result::add); return result; } catch (ServiceConfigurationError e) { LOG.error("Could not load service provider for table factories.", e); throw new TableException("Could not load service provider for table factories.", e); } }
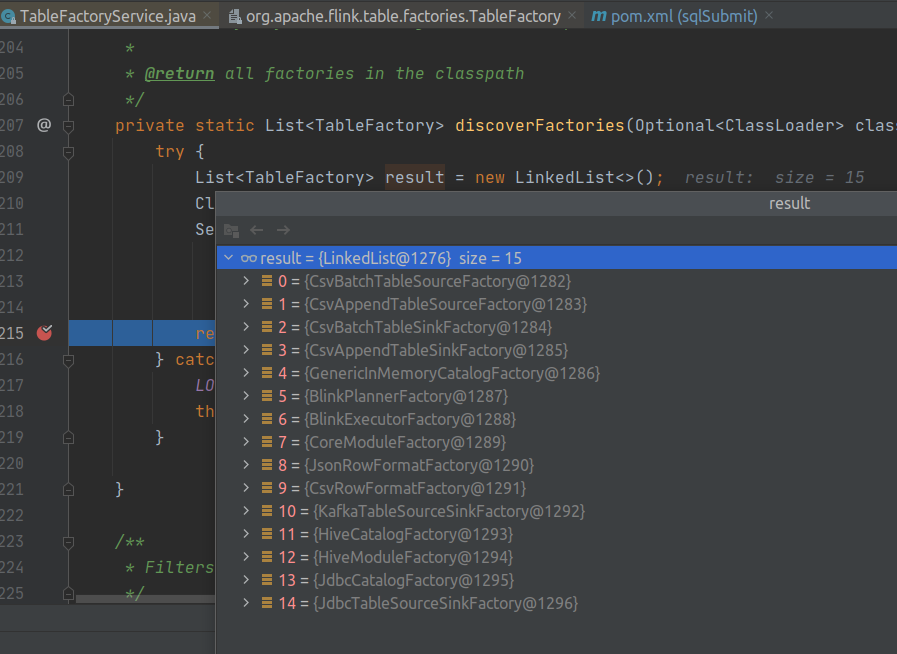
debug 发现,Factory 的工厂类的加载在执行 sql 的时候 创建 TableSink/TableSink(CatalogSourceTable.createDynamicTableSource/PlannerBase.getTableSink) 的时候调用 FactoryUtil.discoverFactories 动态加载的
FactoryUtil.discoverFactories
private static List<Factory> discoverFactories(ClassLoader classLoader) { try { final List<Factory> result = new LinkedList<>(); ServiceLoader .load(Factory.class, classLoader) .iterator() .forEachRemaining(result::add); return result; } catch (ServiceConfigurationError e) { LOG.error("Could not load service provider for factories.", e); throw new TableException("Could not load service provider for factories.", e); } }

其中 sink 会在 PlannerBase.getTableSink 中判断是否是 Legacy 的sink, 老的就用 TableFactory 的工厂类, 新的就用 Factory 的工厂类
private def getTableSink( objectIdentifier: ObjectIdentifier, dynamicOptions: JMap[String, String]) : Option[(CatalogTable, Any)] = { val lookupResult = JavaScalaConversionUtil.toScala(catalogManager.getTable(objectIdentifier)) lookupResult .map(_.getTable) match { case Some(table: ConnectorCatalogTable[_, _]) => JavaScalaConversionUtil.toScala(table.getTableSink) match { case Some(sink) => Some(table, sink) case None => None } case Some(table: CatalogTable) => val catalog = catalogManager.getCatalog(objectIdentifier.getCatalogName) val tableToFind = if (dynamicOptions.nonEmpty) { table.copy(FlinkHints.mergeTableOptions(dynamicOptions, table.getProperties)) } else { table } val isTemporary = lookupResult.get.isTemporary if (isLegacyConnectorOptions(objectIdentifier, table, isTemporary)) { val tableSink = TableFactoryUtil.findAndCreateTableSink( catalog.orElse(null), objectIdentifier, tableToFind, getTableConfig.getConfiguration, isStreamingMode, isTemporary) Option(table, tableSink) } else { val tableSink = FactoryUtil.createTableSink( catalog.orElse(null), objectIdentifier, tableToFind, getTableConfig.getConfiguration, Thread.currentThread().getContextClassLoader, isTemporary) Option(table, tableSink) } case _ => None } }
注: 新版的 sql table source/sink table properties 注意参考官网的写法,upsert-kafka 不能添加属性,如: scan.startup.mode format
例: 添加 'format' = 'json' 属性,报错如下 (注意: Unsupported options 和 Supported options):
Exception in thread "main" org.apache.flink.table.api.ValidationException: Unable to create a sink for writing table 'default_catalog.default_database.user_log_sink'. Table options are: 'connector'='upsert-kafka' 'format'='json' 'key.format'='json' 'key.json.ignore-parse-errors'='true' 'properties.bootstrap.servers'='localhost:9092' 'properties.group.id'='user_log' 'topic'='user_behavior_sink' 'value.fields-include'='ALL' 'value.format'='json' 'value.json.fail-on-missing-field'='false' at org.apache.flink.table.factories.FactoryUtil.createTableSink(FactoryUtil.java:166) at org.apache.flink.table.planner.delegation.PlannerBase.getTableSink(PlannerBase.scala:362) at org.apache.flink.table.planner.delegation.PlannerBase.translateToRel(PlannerBase.scala:220) at org.apache.flink.table.planner.delegation.PlannerBase$$anonfun$1.apply(PlannerBase.scala:164) at org.apache.flink.table.planner.delegation.PlannerBase$$anonfun$1.apply(PlannerBase.scala:164) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.Iterator$class.foreach(Iterator.scala:891) at scala.collection.AbstractIterator.foreach(Iterator.scala:1334) at scala.collection.IterableLike$class.foreach(IterableLike.scala:72) at scala.collection.AbstractIterable.foreach(Iterable.scala:54) at scala.collection.TraversableLike$class.map(TraversableLike.scala:234) at scala.collection.AbstractTraversable.map(Traversable.scala:104) at org.apache.flink.table.planner.delegation.PlannerBase.translate(PlannerBase.scala:164) at org.apache.flink.table.api.internal.TableEnvironmentImpl.translate(TableEnvironmentImpl.java:1267) at org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:675) at org.apache.flink.table.api.internal.StatementSetImpl.execute(StatementSetImpl.java:97) at com.rookie.submit.main.SqlSubmit$.main(SqlSubmit.scala:89) at com.rookie.submit.main.SqlSubmit.main(SqlSubmit.scala) Caused by: org.apache.flink.table.api.ValidationException: Unsupported options found for connector 'upsert-kafka'. Unsupported options: format Supported options: connector key.fields-prefix key.format key.json.fail-on-missing-field key.json.ignore-parse-errors key.json.map-null-key.literal key.json.map-null-key.mode key.json.timestamp-format.standard properties.bootstrap.servers properties.group.id property-version sink.parallelism topic value.fields-include value.format value.json.fail-on-missing-field value.json.ignore-parse-errors value.json.map-null-key.literal value.json.map-null-key.mode value.json.timestamp-format.standard at org.apache.flink.table.factories.FactoryUtil.validateUnconsumedKeys(FactoryUtil.java:324) at org.apache.flink.table.factories.FactoryUtil$TableFactoryHelper.validate(FactoryUtil.java:554) at org.apache.flink.table.factories.FactoryUtil$TableFactoryHelper.validateExcept(FactoryUtil.java:573) at org.apache.flink.streaming.connectors.kafka.table.UpsertKafkaDynamicTableFactory.createDynamicTableSink(UpsertKafkaDynamicTableFactory.java:148) at org.apache.flink.table.factories.FactoryUtil.createTableSink(FactoryUtil.java:163) ... 18 more
最后的 sql 如下:
-- kafka source CREATE TABLE user_log ( user_id VARCHAR ,item_id VARCHAR ,category_id VARCHAR ,behavior VARCHAR ,ts TIMESTAMP(3) ) WITH ( 'connector' = 'kafka' ,'topic' = 'user_behavior' ,'properties.bootstrap.servers' = 'localhost:9092' ,'properties.group.id' = 'user_log' ,'scan.startup.mode' = 'group-offsets' ,'format' = 'json' ); -- kafka sink CREATE TABLE user_log_sink ( user_id varchar ,max_tx bigint ,primary key (user_id) not enforced ) WITH ( 'connector' = 'upsert-kafka' ,'topic' = 'user_behavior_sink' ,'properties.bootstrap.servers' = 'localhost:9092' ,'properties.group.id' = 'user_log' ,'key.format' = 'json' ,'key.json.ignore-parse-errors' = 'true' ,'value.format' = 'json' ,'value.json.fail-on-missing-field' = 'false' ,'value.fields-include' = 'ALL' -- ,'format' = 'json' );
注: timestamp(3) 改成: 2017-11-26 01:00:00 (以前是: 2017-11-26T01:00:01Z)
sqlSubmit 地址和完整 sql 见: https://github.com/springMoon/sqlSubmit
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文
