JVM
1、JVM
Runtime data area,运行时数据区。包含5个区域,分别为method area、heap、java stack、native method stack、program counter register。
图示如下:

1.1 方法区
用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译后的代码等信息。方法区是线程间共享的,当两个线程同时需要加载一个类型时,只有一个类会请求ClassLoader加载,另一个线程会等待。
1.2 堆区
虚拟机中用于存放对象与数组实例的地方,垃圾回收的主要区域就是这里(还可能有方法区)。如果垃圾收集算法采用按代收集(目前大都是这样),这部分还可以细分为新生代和老年代。新生代又可能分为Eden区,From Survivor区和To Survivor区,主要是为了垃圾回收。所有的线程共享Java堆,在这里还可以划分线程私有的缓冲区(Thread Local Allocation Buffer,TLAB)。
1.3 java stack
虚拟机栈也是线程私有的,每创建一个线程,虚拟机就会为这个线程创建一个虚拟机栈,虚拟机栈表示Java方法执行的内存模型,每调用一个方法,就会生成一个栈帧(Stack Frame)用于存储方法的本地变量表、操作栈、方法出口等信息,当这个方法执行完后,就会弹出相应的栈帧。
栈帧分为三部分:局部变量区(Local Variables)、操作数栈(Operand Stack)和帧数据区(Frame Data)。
如果请求的栈的深度过大,虚拟机可能会抛出StackOverflowError异常,如果虚拟机的实现中允许虚拟机栈动态扩展,当内存不足以扩展栈的时候,会抛出OutOfMemoryError异常。
1.4 native method stack
与虚拟机栈类似,只是是执行本地方法时使用的。
1.5 program counter register
类似于PC寄存器,是一块较小的内存区域,通过程序计数器中的值寻找要执行的指令的字节码,由于多线程间切换时要恢复每一个线程的当前执行位置,所以每个线程都有自己的程序计算器。这一个区域不会有OutOfMemeryError。当执行Java方法时,这里存储的执行的指令的地址,如果执行的是本地方法,这里的值是Undefined
2、JVM从堆角度划分
2.1 堆、非堆、离堆
-
堆
堆用来存放所有的对象和数组,在堆内空间又分为年轻代和年老代。
-
年轻代
年轻代分为伊甸区和幸存区。所有对象诞生于伊甸区,然后回收后经过幸存区。
-
伊甸区
所有对象诞生于伊甸区。
-
幸存区
之所以使用两个幸存区,是为了在每次回收对象后,可以进行内存碎片整理。以利用更有效使用内存。一区和二区也称为from区和to区,每次有一个区的空间是空的。但对象回收期间每个幸存区只经过一次。
- 幸存一区
- 幸存二区
-
-
年老代
-
-
非堆
非堆是JVM内在堆外部分的内存,主要包含代码缓存区、压缩类空间和元数据区。JDK1.8之前称为永久区。
-
离堆
离堆是操作系统内JVM之外的内存空间。java可以直接操纵jvm之外的内存空间。
2.2 参数调整
jdk1.8之后,没有永久代的概念了,改成了元空间的叫法。而且官方文档上说不会再出现永久区的溢出问题,比如在使用maven进行编译时常常导致的问题。
| 参数 | 解释 | 示例 | 备注 |
|---|---|---|---|
| -Xms | 初始堆大小 | -Xms100m | |
| -Xmx | 最大堆设置 | -Xmx100m | |
| -Xmn | 年轻代设置 | -Xmn100m | |
| -XX:OldSize | 年老代初始容量 | -XX:OldSize=200m | |
| -XX:NewSize | 年轻代大小 | -XX:NewSize=100m | not work |
| -XX:MaxNewSize | 年轻代最大值 | -XX:MaxNewSize=100m | |
| -XX:NewRatio | 年老代是年轻代的倍数 | -XX:NewRatio=3,默认2 | |
| -XX:SurvivorRatio | 伊甸区是单个幸存区的倍数 | -XX:SurvivorRatio=1,默认6 | |
| -XX:MetaspaceSize | 元空间大小 | -XX:MetaspaceSize=1g | not work |
| -XX:MaxMetaspaceSize | 最大元空间 | -XX:MaxMetaspaceSize=2g | not work |
| -XX:CompressedClassSpaceSize | 压缩类空间 | -XX:CompressedClassSpaceSize=2g | not work |
| -Xverbosegclog | 记录gc详细日志到文件 | -Xverbosegclog:/home/1.log | WAS(Websphere application server)中使用 |
| -Xloggc | 记录gc日志 | -Xloggc:/home/1.log | JDK非标选项 |
3、JVM相关工具
3.1 jvisualvm

3.2 jconsole

3.3 jmap

3.4 jstat
-
jstat查看帮助
$>jstat
-
查看jstat选项
$>jstat -options
-
查看jstat的gc情况
#1秒钟1采样,采样100个样本,数字是进程id $>jstat -gc 143316 1s 100
-
各字段含义
列名 说明 S0C 幸存一区容量(Survivor,Capacity,KB) S1C 幸存二区容量 S0U 幸存一区使用的大小(Utility,KB) S1U 幸存二区使用的量 EC 伊甸区容量 EU 伊甸区使用量 OC 年老代容量 OU 年老代使用量 MC 方法区容量 MU 方法区使用量 CCSC 压缩类空间容量 CCSU 压缩类空间使用量 YGC 年轻代gc次数 YGCT 年轻代gc时间 FGC Full GC次数 FGCT Full GC时间 GCT GC总时间,FCCT + YGCT
4、gc
gc是garbage collection的缩写,即垃圾回收。gc时,除了gc所需要的线程外,app的所有线程都会暂停,直到gc过程结束。因此有stop-the-world一次的说法。对gc的优化,很多时候也是指要减少stop-the-world的时间。
java程序中显式将对象置为null是个不错的操作,起码保证了对象被回收的前提条件,但是显式调用System.gc()会显著降低系统性能。
年轻代上发生的gc称为minor gc。java程序中,大部分的对象是“夭折”的,意思就是对象在minor gc的时候就被回收掉了,没有多少对象会进入到年老代。
年老代上发生gc称为full gc或major gc,minor gc没有回收掉的对象会拷贝到年老代中。
元空间(jdk1.8之前称为永久代),也就是方法区存放的是类常量以及字符串常量。该区域也会发生gc,并且这部分的gc也算作major gc。
gc的回收过程是伊甸区已满,向幸存区的to区回收,同时幸存区的from区也会向to进行回收,注意幸存区有两个,同一时刻只有一个幸存区是空的,from区和to区会交替进行角色交换,但是对象在回收过程中只经过一次从from到to的过程,如果对象仍没有回收掉,就会进入到年老代。

JDK7一共有5中GC类型:
-
Serial GC
串行gc,配置参数为-XX:+UseSerialGC,采用“mark-sweep-compact”算法,mark是标记依然存活的对象,sweep清理掉回收的对象,compact是压紧内存空间,可以理解为内存碎片整理。
-
Parallel GC
并行gc,配置参数为-XX:+UseParallelGC,串行gc使用一个线程执行gc,并行gc使用多个线程执行gc,因此在多核或是内存充足的情况下可以使用。串行gc很少使用。
-
Parallel Old GC
在JDK5之后才出现的算法,配置参数为-XX:+UseParallelOldGC。与并行gc算法的不同是针对年老代gc的算法采用的是“mark-summary-compact”。summary和sweep的不同是将gc之后幸存的对象放置到gc预先处理好的不同区域,算法相对sweep来讲稍微复杂些。
-
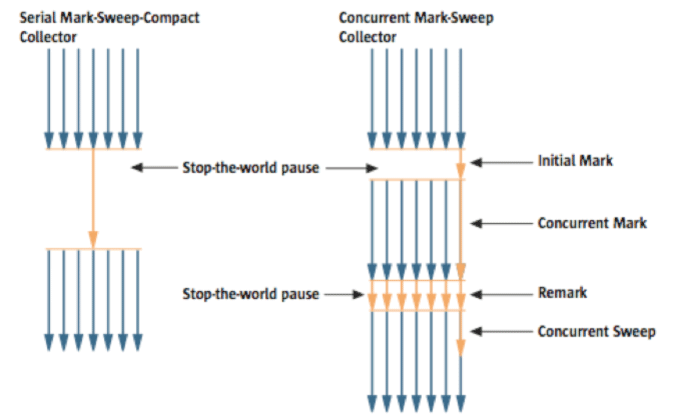
CMS GC
并行gc,该算法相较于之前的gc算法复杂得多。配置参数是-XX:+UseConcMarkSweepGC过程是“mark-sweep”阶段,没有了compact阶段。而且mark阶段又分成了initial mark和mark,其中initial mark需要stop-the-world,但是时间非常短,这一步主要是查找那些距离类加载器非常近的对象。之后的mark阶段是可以并行,即不需要stop-the-world,该步骤中,所有被幸存对象引用的对象会被确认是否已经被追踪和校验。remark阶段正如其名称一样,再一次检查那些在并行标记中增加或删除的对象,相当于验证过程。最后的并行sweep阶段开始执行gc过程,一旦采用该中gc,由gc导致的暂停时间非常短暂。因此CMS GC也叫低延迟gc,常用对响应时间非常苛刻的场景下。但CMS GC也有缺点:
- 占用更多的内存和cpu
- 默认不支持compact操作
如果因为碎片过多,导致不得不执行compact操作时,stop-the-world时间要比其他任何gc都要长,需要考虑compact任务的发生频率和执行时间。
-
G1 GC
G1类型是垃圾回收优先类型,在jdk1.7才正式发布的一个算法。配置参数为-XX:UseG1GC。G1的结构如图:

在该类型下,不再有年轻代和年老代的概念。如图所示,每个对象被分配到不同的格子,随后执行gc。一个区域装满后,对象被分配到另一个区域,并执行gc。中间不再有从年轻代到年老代转移的三个步骤了。该类型为替代CMS类型而创建,因为CMS在长时间持续运行时导致很多问题。
G1的最大好处是性能,他比任何一种GC都快,但是一定要在成熟的jdk版本上使用它。
-
不同gc算法评测
执行10000次,每次分配60k空间,代码如下:
class Hello { public static void main(String[] args) throws Exception { int count = Integer.parseInt(args[0]) ; int size = Integer.parseInt(args[1]) ; for (int i = 0 ; i<= count ; i++) { byte[] bytes = new byte[size] ; } } } // @Test public void testProcess() throws Exception { //5中gc算法 String[] gcs = { "UseSerialGC" , "UseParallelGC" , "UseParallelOldGC" , "UseConcMarkSweepGC" , "UseG1C" } ; Runtime r = Runtime.getRuntime(); for(String gc :gcs){ System.out.print(gc + " : "); for(int i = 0 ; i < 3 ; i ++){ String javapc = String.format("java -Xms500m -Xmx500m -XX:NewSize=7m -XX:MaxNewSize=7m -XX:SurvivorRatio=5 -XX:+%s -cp d:/java Hello 10000 60000" , gc) ; long start = System.nanoTime() ; Process p = r.exec(javapc); p.waitFor(); System.out.print((System.nanoTime() - start) + " "); } System.out.println(); } }结果如下:
算法 时间1(ns) 时间2(ns) 时间3(ns) UseSerialGC 185,413,126 164650097 183464706 UseParallelGC 1063,575,715 161432700 157594978 UseParallelOldGC 167,484,871 160564410 158637748 UseConcMarkSweepGC 259,620,169 217630613 238550879 UseG1C 11977076 12847009 12079300