一面:
hashMap的几个方法,put,扩容

首先是一个put方法,把key的hash值和key都穿进去。
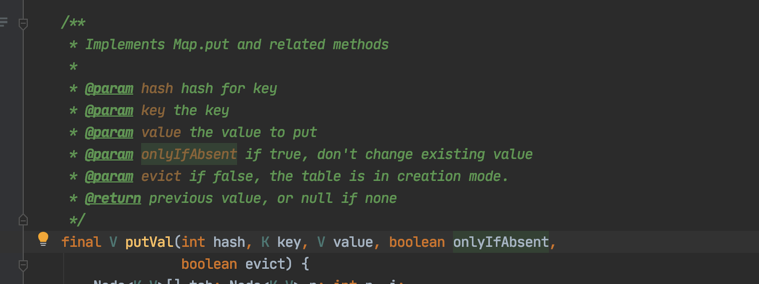
下面看一下参数描述:
- hash: hash for key:key的hash值
- key: the key:key
- value: the value to put:要放的值
- onlyIfAbsent: if true, don't change existing value 是否覆盖原先的值,如果是true,不改变原来的值
- evict: if false, the table is in creation mode. 如果是false,则表处于创建模式
- return:previous value, or null if none 返回上一个值,如果没有的,就返回null
evict参数afterNodeInsertion方法用到了:
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
源码中其实已经说了,这个三个方法都是为了继承HashMap的LinkedHashMap类服务的。
LinkedHashMap 是 HashMap 的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用 LinkedHashMap。
LinkedHashMap中被覆盖的afterNodeInsertion方法,用来回调移除最早放入Map的对象
下面贴出来源码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断当前table是否有值,如果没有,resize一下就行
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果当前
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
下面逐步分析: