DW/BI(数据仓库和商业智能)
数据仓库是为了把操作型数据集中到统一的环境中,以提供决策型数据访问,把越来越复杂的业务数据转化为对于业务运营、业务分析来说简单易用的数据形式;其目标是让数据应用人员使用数据仓库里的数据,创造更多信息与价值。
BI是分析数据并获取洞察力、从而帮助企业做出决策的一系列方法、技术和软件。BI中海包含了数据挖掘、数据可视化、多维分析、标签分类等方面。
可以说,数据仓库是BI背后的引擎(或管道)。
企业数据仓库总线架构
企业价值链
每家机构都有一个由关键业务过程组成的潜在价值链,这个价值链确定机构主体活动的自然逻辑流程。数据仓库建设就是围绕着价值链建立一致化的维度和事实。
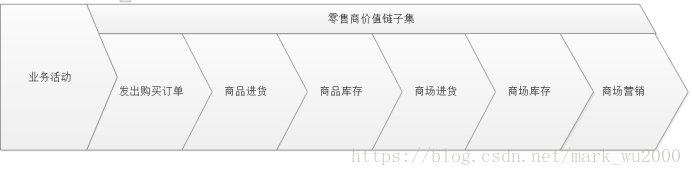
数据总线
这些业务过程都会共用一些维度,形成了企业数据仓库的总线,一致化维度和事实看作一组标准的应用程序连接口,可以看作一个数据仓库的总线架构。它可以将新的业务过程引入数据仓库中,该业务过程从总线获得动力,并且和其他已经存在的业务过程和谐共存。

数据总线矩阵
矩阵的每一行都对应机构中的一个业务过程,每一列都和一个业务维度相对应,用叉号填充显示的是和每一行相关的列。业务过程应该先从耽搁数据源系统开始,然后再进行多数据源的合并。
企业数据仓库总线矩阵是DW/BI系统的一个总体数据架构,提供了一种可用于分解企业数据仓库规划任务的合理方法,开发团队可以独立的,异步的完成矩阵的各个业务过程,迭代的去建立一个集成的企业数据仓库。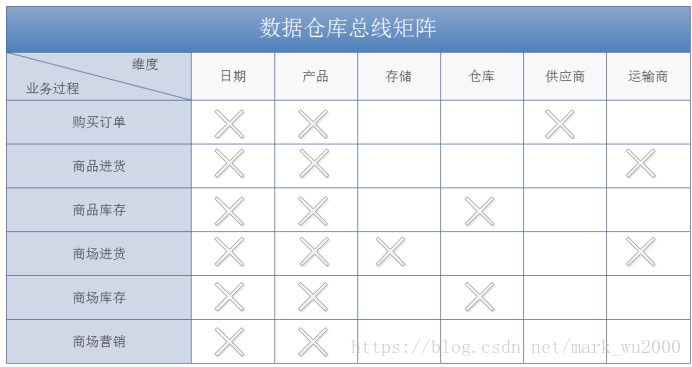
数据仓库模型
数据仓库架构分层:sd(源数据层)、ods(中间存储层)、dw(多维数据层)、dm(数据集市层)、app(应用层)。
源数据层:源数据一般具有多来源、多类型特征,可能使用多种数据库,甚至是非结构化数据。
中间存储层:中间存储层和源数据基本保持一致,保存着最细粒度的数据。
多维数据层:多维数据层是经过清洗的,有价值的数据。多维数据层是在存储层的基础上清洗脏数据、删选有价值数据,并且对存储层的事实维度表进行事实维度分离。
数据集市层:它是面向主题轻度汇总的数据,针对某主题的最细粒度数据,能满足该主题所有需求。数据集市是按照某一主题汇总,既可以由多维数据层汇总,也可以是其他集市表进一步汇总。
应用层:各种报表,一般都是在数据集市基础上按照各种特定维度汇总的结果。
ETL
ETL,Extraction-Transformation-Loading的缩写,中文名称为数据抽取、转换和加载。其贯穿于数据仓库的各个层次环节。
数据抽取:把源数据的数据抽取到ODS或者DW中。
源数据包括:关系型数据库,如Oracle,MySQL,SqlServer等;文本文件,如用户浏览网站产生的日志文件,业务系统以文件形式提供的数据等。
数据清洗:把不需要的,和不符合规范的数据进行处理。数据清洗最好放在抽取的环节进行,这样可以节约后续的计算和存储成本。
数据转换(刷新):用ODS中的增量或者全量数据来刷新DW中的表。
数据加载:每insert数据到一张表,都可以称为数据加载。
常用的ETL工具有:Datastage,Informatica,Kettle,微软SSIS。
大数据技术体系
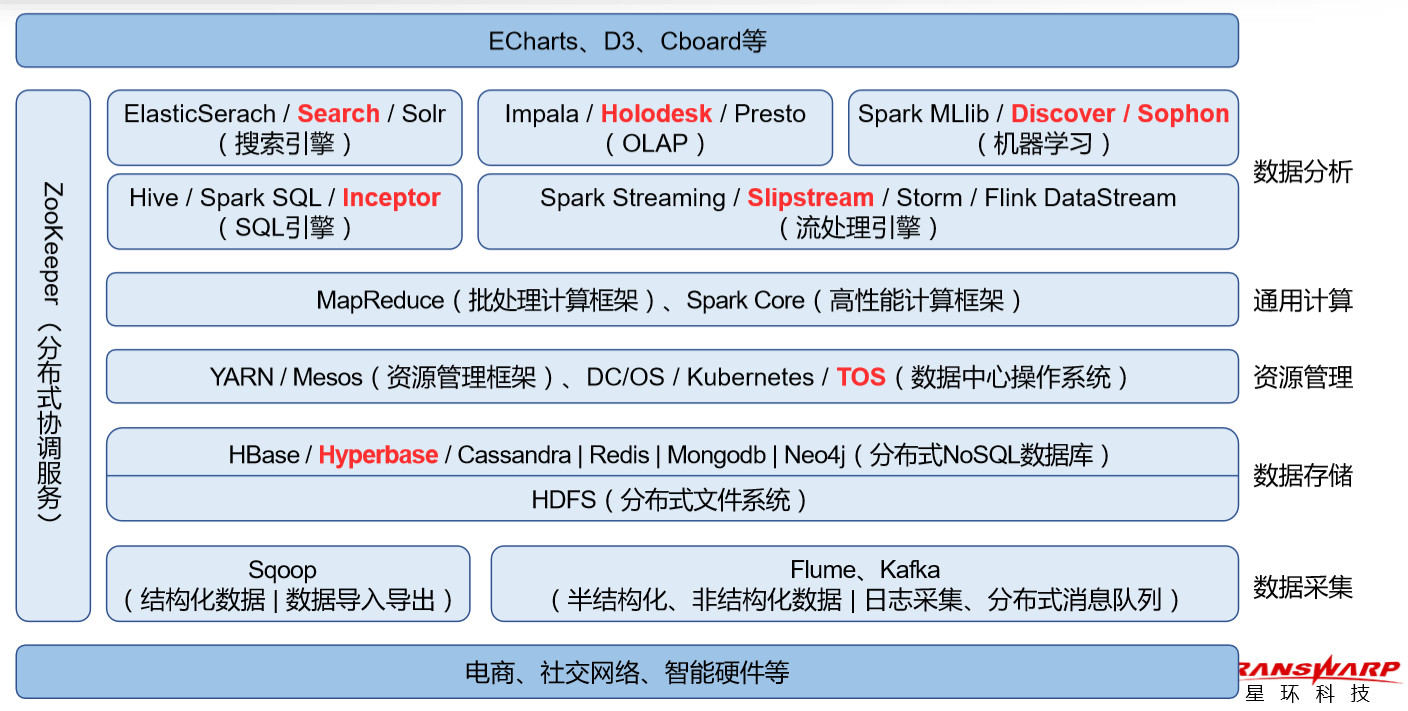
HDFS
- Hadoop分布式文件系统(Hadoop Distributed File System)
- 在开源大数据技术体系中,地位无可替代
- 高容错、高可用、高扩展
- 简单一致性模型:一次写入、多次读取,支持追加,不允许修改
MapReduce
- 面向批处理的分布式计算框架
- 高容错:任务失败,自动调度到其他节点重新执行
- 高扩展:计算能力随着节点数增加
- 适用于海量数据的离线批处理
Spark
- 高性能分布式通用计算引擎
YARN
- Yet Another Resource Negotiator,另一种资源管理器
- 专注于资源管理和作业调度
- 通用:适用于各种计算机框架,如MapReduce、Spark
- HDFS高可用
Hive
- Hadoop数据仓库
- 采用HDFS或HBase为数据存储
- 采用MapReduce或Spark为计算框架
- 采用Hive SQL查询语句
HBase
- Hadoop DataBase
- 分布式NoSQL数据库
- 列式存储:主要用于半结构化、非结构化数据
- 采用HDFS为文件存储系统
结构化数据指可以使用关系型数据库表示和存储,表现为二维形式的数据。一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。
半结构化数据是结构化数据的一种形式,它并不符合关系型数据库或其他数据表的形式关联起来的数据模型结构,但包含相关标记,用来分隔语义元素以及对记录和字段进行分层。常见的半结构数据有XML和JSON。
非结构化数据是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。包括所有格式的办公文档、文本、图片、各类报表、图像和音频/视频信息等等。
ElasticSearch
- 开源的分布式全文检索引擎
- 基于Lucene实现全文数据的快速存储、搜索和分析
- 首选的分布式搜索引擎
Sqoop
- 主要在Hadoop和关系数据库之间进行批量数据迁移的工具
- 面向大数据集的批量导入导出:将输入数据集分为N个切片,然后启动N个Map任务并行传输
- 支持全量、增量两种传输方式
Flume
- 分布式海量数据采集、聚合和传输系统
- 支持重读重写,保证消息传递的可靠性
Kafka
- 基于发布/订阅的分布式消息系统
- 消息持久化、高吞吐、高容错、易扩展
- 同时支持离线、实时数据处理
参考链接
星环大数据平台架构