github:https://github.com/LimBee/NTIRE2017
摘要
本文主要是用了残差学习,这篇论文也就使用了残差结构超分网络使得效果大大超越SOTA
移除传统残差网络中不必要的模块 。多尺度的超分(MDSR)和训练方法。
也是NTIRE2017超分挑战的冠军
1、Introduction:
(1)网络结构微小的改动对重构效果影响很大。(对resblock的BN改进)
相同的网络在不同的初始化和训练技巧下会有不同的结果。网络结构的设计和优化方法是重要的。
Second, most existing SR algorithms treat superresolution of different scale factors as independent problems without considering and utilizing mutual relationships among different scales in SR. As such, those algorithms require many scale-specific networks that need to to be trained independently to deal with various scales.
(2)现有的超分方法都是将不同的尺度因子单独处理,单独训练各自尺度的网络:
VDSR:缺点 将双三次插值的图像作为输入增加内存和运算量
SRResNet直接用了resnet的结构,但resnet是为解决high-level视觉任务。直接用于low-level的任务(超分)不是最优的。
2、RelatedWork
学习低分图ILR 和高分图HR之间的映射函数
Advanced works aim to learn mapping functions between I LR and I HR image pairs.
3、Proposed Method
均方误差或L2损失是广泛用于图像恢复,但有实验表明使用L1训练相比L2效果更好。
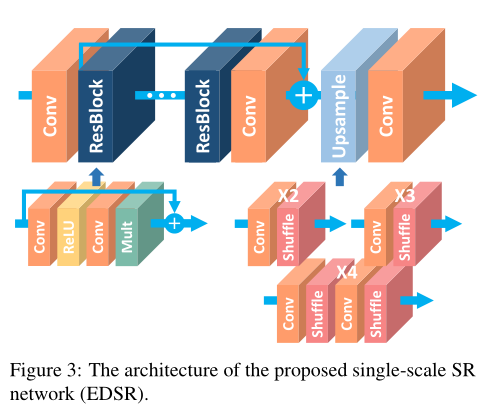
网络结构整体上是一个residual in residual 如图3所示:
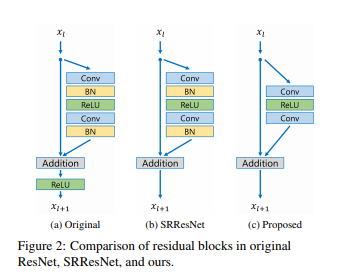
Since batch normalization layers normalize the features, they get rid of range flexibility from networks by normalizing the features, it is better to remove them. We experimentally show that this simple modification increases the performance substantially as detailed in Sec. 4.
(最早是在去模糊网络移除BN层)BN层是对特征进行规范化,这样就让网络输出的范围固定,移除BN,减少了40%的显存使用,这样就能有限的计算资源下训练更大的网络。
移除BN的block输出, 响应值范围比减均值除方差要广 如下图
3.1 、Single scale model单尺度的网络
B代表网络的深度,F代表特征的通道数,(BF2)的参数量占O(BF)的GPU显存,因此有限的计算资源下增加F能比B更大提升模型的表达能力(参数越多表达能力)
但是过多增加特征通道数是会影响训练不稳定, 但网络与SRResNet不同的是,在resblock外没有relu。
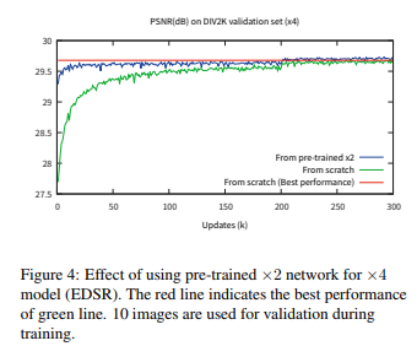
训练x3,x4的网络时,我们使用x2的网络作为初始化。预训练的方法加速网络训练和提升效果。
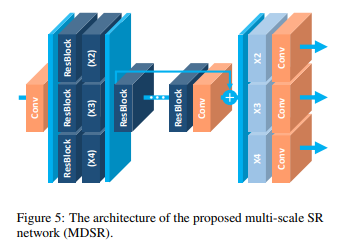
3.2、多尺度的模型
4、Experiment
4.1、DIV2K 800张训练集 100张验证集 和100张测试集。测试集的gt没公布所以在验证集上对比。还有4个benchmark:Set5,Set14,BSD100,Urban10
4.2、训练细节:
对训练数据进行随机水平翻转和90旋转,输入低分图的大小固定48x48。预处理减去了DIV2K数据集的均值。Adam优化器的参数β1 = 0.9, β2 = 0.999,batchsize设为16.
学习率初始化为1e-4,每2e5 minibatch 学习减半。
本文用的L1损失而非L2。L2相当于是最大化PSNR,但实验表明L1比L2有更好的收敛。
4.3、Geometric Self-ensemble几何自集成的方法:
测试阶段通过翻转和旋转得到7张增强的输入低分图像,然后使用对应的逆变换。最终8张输出图像取均值得到最终结果。
自集成的方法相较于其他方法不需要额外的模型。这就使得当模型很大或者训练时间很久的情况很有效。虽然self-ensemble 比起传统的模型集成方法。表中使用了自集成方法加了+后缀。 自集成仅在是像双三次下采样的方法有效?
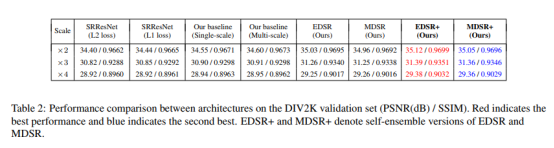
4.4. Evaluation on DIV2K
Table2 . SRResNet 使用了L1 比原先使用L2在所有scale上都取得更好的结果。修改了BN占用更少的GPU显存。
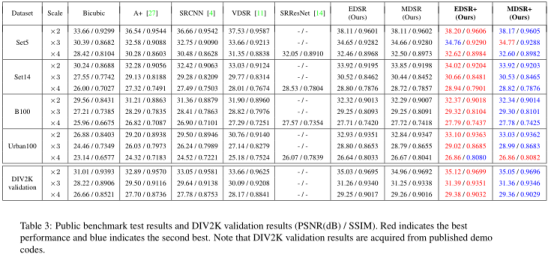
5、比赛:
本文工作是为了NTIRE2017超分竞赛提出, 有两个赛道(双三退化和未知的退化),输入图像不仅是下采样了还严重模糊。
比赛排名如下: