1. 背景
大规模视觉识别有三大方向:
1)对网络结构改造,加深网络,增加每层网络的神经元数量。
2)做迁移学习:例如学习到的1000类分类器用在500类(大用在小)。
3)多个CNN结合:多个1000类分类器来识别10000类(小用在大)。——本文的方向
Deep Mixture :深度混合,对多个CNN在FC8层的输出进行融合。
Diverse experts:多个专家,有多个CNN,每个CNN负责不同的任务空间。
两层本体的构造
(1) 估计类间的的语义关系,产生关系矩阵Ψ
(2) 根据语义信息将原子类(不可再分)划分到不同的大类
对于两个原子类ci,cj它们的语义关系定义如下;

在这个语义关系矩阵上进行谱聚类,矩阵Ψ被分成一些小块,每个块对应一个大类节点。
2.核心内容
A划分任务组
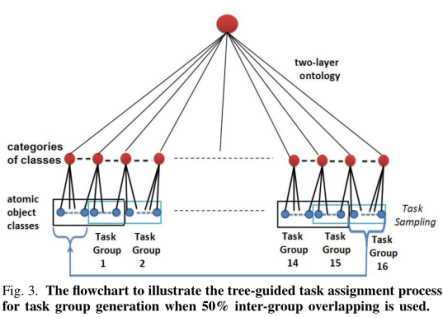
每M个类别划分到一组,根据重叠率将上一组右边一部分类别也放入到当前组中。
每个任务组都包含M个原子目标类别,外加一个“不在此组”的类别
(1)建立 组间相关,使得不同组之间的信息可以进行传递(deep CNNs)
(2)可以避免在当前任务组里不相关的目标预测值太均衡以至于无法区分
B.每个任务组中的多任务学习。
单个deep CNN联合目标函数如下
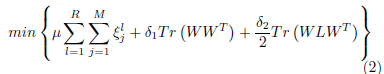
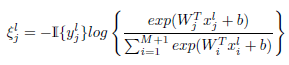
R为每个原子类的训练图像数,L是视觉相似矩阵S的拉普拉斯矩阵;(S相当于邻接矩阵)
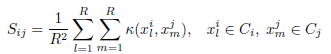
AlexNet的深度特征先用来初始化矩阵S,我们的基础CNN获得的特征再进一步更新视觉相似矩阵S
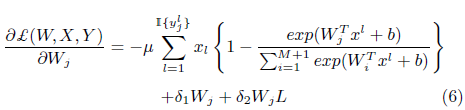
类间的视觉相似度是用来估计任务间(inter-task)的相关性,正则项Tr(WLWT)
用来使相关性高的两个类别的模型参数W有很大部分是相同的。
区分同任务下语义相似的原子类别。
(1)将相同的预测部分提取出来Wj=W0+Vj。
(2)联合优化模型参数W=(W1,…,WM)
(3)使用类别‘专属’成分Vj来区分同任务下的类别。
C.合并多个CNN预测的函数(Stacking Function for Fusing Diverse Predictions)
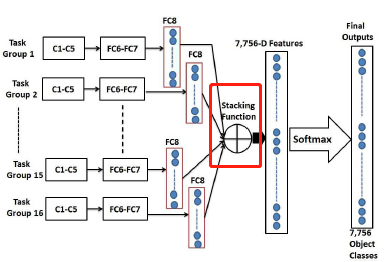
Stacking函数使用不同的CNN得到7756个类别的预测得分来生成图像语义表征的高级特征。7756维的特征再放入softmax得到7756个输出。
关于stacking函数3个因素:
1)预测得分:
给定一张图,对应的类别可能是不存在的或者只在其中一个CNN里(只在一个task中,任务无重叠),或在个别几个CNN里,其他不相关的CNN还是可以提供预测,如下式表示第j个CNN中第i个输出(原文:pj(ci) is the ith output (for the ith atomic object class ci) in
the jth base deep CNN)
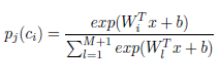
2)组间冲突:
当一张图得到来自不同CNN的预测发生冲突时,就需要用stacking函数
3)组间的重叠率 :
任务组的重叠百分比越大,每个原子类别就分配到更多的任务组。

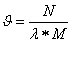 任务组的个数.
任务组的个数.
第一部分: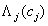 ,ci类别在第j个任务组里的话,值为1;反之,为lambda。
,ci类别在第j个任务组里的话,值为1;反之,为lambda。

测试的时候怎么做呢?又不知道是什么类别,怎么判断是不是在这个任务组里呢?
第二部分:第j个CNN中第i个输出。
第三部分: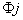 为该图像不在第j个任务组里的概率,在任务组的话,这个值就会很小,使这个项很大。
为该图像不在第j个任务组里的概率,在任务组的话,这个值就会很小,使这个项很大。
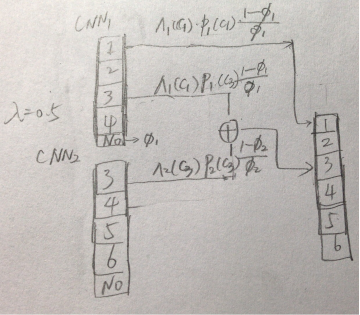
7756维的Softmax目标函数如下所示


这个梯度反向传播进而优化1)7756维softmax的模型参数;
2)任务组里的softmax;
3)Deep CNNS的节点权值。
3.实验部分
数据集:ImageNet10K(10184,7756个原子类别)
(1) 是否Deep CNNs的个数和任务重叠的百分比;
(2) 是否多任务学习算法能用类间视觉相似度学习到显著的CNN 和更能区分同任务下类别多任务softmax。
(a)深度混合算法的有效性。
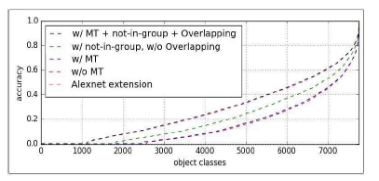
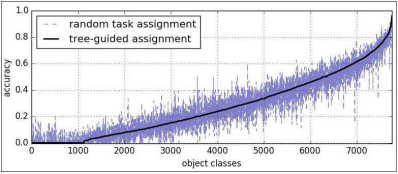
AlexNet Extension:直接扩展,将1000个输出的softmax层换成7756个输出的softmax;
Random assignment:不考虑类别相关性随机选取M个别组成一个任务组;

(b)多任务学习的有效性

横轴为类别的序号,下面的图都是,而不是随类别数增加,精度增加(不再解释)
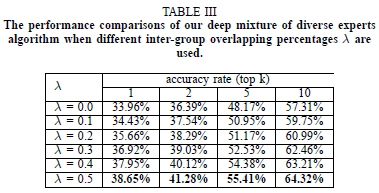
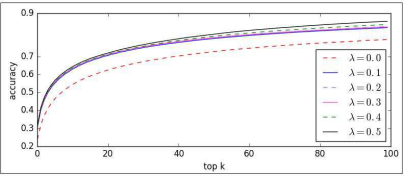
(c)不同的重叠率的对比:
通过实验,发现重叠率在50%的时候,模型表现是最好的。
(d)不同树结构对任务分配的影响。
目前任务分配有两种方法:两层本体和标签树视觉树,

实验对比后可以发现本体思想效果更好,原因可能如下 (1)预训练的1000类CNN不足以7756类别显著的表征信息,学习视觉相似度也比较困难。(2)不够精确的视觉相似度也就让学习的视觉树不够准确。(3)使用不准确的视觉树也就可能让相似的类别分配到不同组。
(e)不同的stacking函数:
Stack1:是本文所采用的方法。
Stack2:修改了第一小部分指示函数和第三部分,如下两个公式
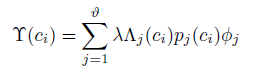
第一部分:指示函数如下
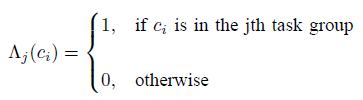
感觉有点像 NMS和soft-NMS的思想,但第三部分直接用‘不在此组’的概率,若在第j个任务组里,第三部分的值按理趋近于0,整个值不就很小吗?

(f)早融合和后融合
Late fusion:在FC8层融合,本文所使用的。
Early fusion:在FC7层结合。每个CNN在FC7层的4096维特征无缝合并为32768维特征(8个CNN),作为softmax的输入。两种方法的效果对比如表4所示:

(1) 后融合能有效限制每个CNN的错误的负面影响。
(2) 能充分利用重叠部分和‘不在此组’标签,在CNN之间传递重要的信息。是不同的CNN的预测可以进行比较。
(g) 困难的目标类别:
有哪些是难识别的;为什么这些类别难识别;有什么潜在的方法可以加强这些类别的区分度。
(1)难识别的类别通常是细粒的,彼此间很难区分;
(2)
(h)级联的CNN。
一些难识别的类别可能是因为有更高的学习复杂性,只用一个CNN来识别困难类别和简单类别可能不是最优的方法,简单的类别识别精度高,但困难的类别精度很低。
级联是广泛使用的方法来学习更好的分类器,训练两个CNN:第一个用来提高在简单的目标类别上的精确度,第二用来提高困难类别上的精确度。对应的stacking函数变为如下:

第一部分:

第二部分: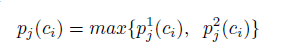
第三部分:两个CNN对‘不在此组’的输出取平均。
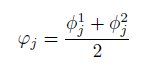


(i)使用不同类型的深度网络作为基础CNN:
分别使用了VGG,GoogleNets,ResNet,可以看出ResNet的效果最好。

(j)与两个基准的对比:
与使用标签关系图的学习算法比较如下
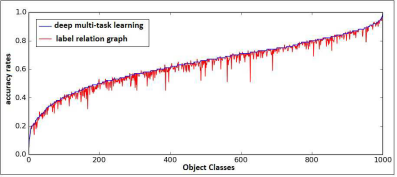
与MixDCNN比较如下

ImageNet10K每个原子类别没有大量的训练图像,无法使MixDCNN方法产生多个有充足图像的子集。
最后对比网络参数的数量,提出的深度混合多专家算法使用n个深度CNNN,因此网络,参数比率为n,(n是任务组的个数)。