导读:
本文为CVPR2018论文《Deep Adversarial Subspace Clustering》的阅读总结。目的是做聚类,方法是DASC=DSC(Deep Subspace Clustering)+GAN(Generative Adversarial Networks)。本文从以下四个方面来对论文做个简要整理:
背景:简要介绍与本文密切相关的基础原理,DSC,GAN。
方法:介绍论文使用的方法和细节。
实验:实验结果和简要分析。
总结:论文主要特色和个人体会。
一、背景
论文方法DASC(深度对抗聚类)是基于DSC(深度子空间聚类)和GAN(生成对抗网络)的,所以,在介绍论文方法之前,对DSC和GAN做个简要介绍。
1.DSC
1)原理(LRR)
首先要明确的是,整个论文的大方向是做聚类。做聚类以往已经有非常多的方法,最近几年比较流行也即DSC所采用的理论基石是低秩表示(LRR)。
LRR理论基本思想是,对于一个数据(如图像或图像特征等)可以表示为干净数据部分和噪声部分,其中干净数据部分又可以采用字典和系数表示的形式,此时要求干净数据的系数表示部分是低秩的,噪声部分是稀疏的。此时,如果用数据本身作为字典,那么其系数部分就可以描述原始数据间的相似度。用数学公式表示如下:
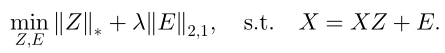
其中,X=[x1,x2,...xn]∈Rd*n表示原始输入数据(一般是图像的特征),Z∈Rn*n表示系数部分,E∈Rd*n表示噪声。
那么这个式子与聚类有什么关系呢?关系是,假设待聚类的数据分布于多个线性子空间,那么通过求解上述式子的最小化问题,我们可以得到数据X间的相似度矩阵Z,有了相似度矩阵我们就可以对输入数据X=[x1,x2,...xn]进行聚类。
因此,实现对多个d维数据xi的聚类,LRR方法采用的方法是,将xi按列组合成X,然后通过优化上述式子,得到Z,最后将Z输入到谱聚类算法中,就可以得到最终的聚类结果。
2)方法(网络)
一般来说,对于图像做聚类,我们采用的方法是,对图像提取特征,然后得到特征表示,组成X,然后采用LRR原理进行聚类。但是这种先提取特征再进行聚类的缺点是一个两阶段的过程,两者不能互相促进。
因此DSC将特征提取和相似度矩阵的学习融入到一个网络中进行统一学习。重新定义符号表示,用X表示输入数据,Z表示特征,θ表示待学习的参数相似度矩阵,那么DSC的学习是最优化下面的式子:
min ||Z-Zθ||F+λ||θ||F,以求得参数Z和θ。
网络整体结构如下:

上图所示,输入图像X,经过两层编码器进行编码(即特征转换),得到特征表示Z,然后将Z reshape成一个列向量,然后与后面变量Zθ进行全连接,再将Zθ重新reshape成与前面相对应的大小,再经过两个解码层,得到恢复出的图像。即,原图->编码得特征->解码得原图。
3)设计
DSC重点主要是Loss的设计,Loss由重建损失、参数正则损失、自表示损失几部分组成:
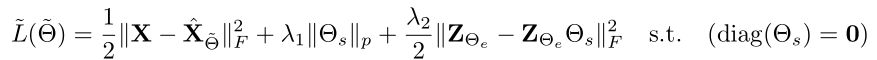
2.GAN
1)原理
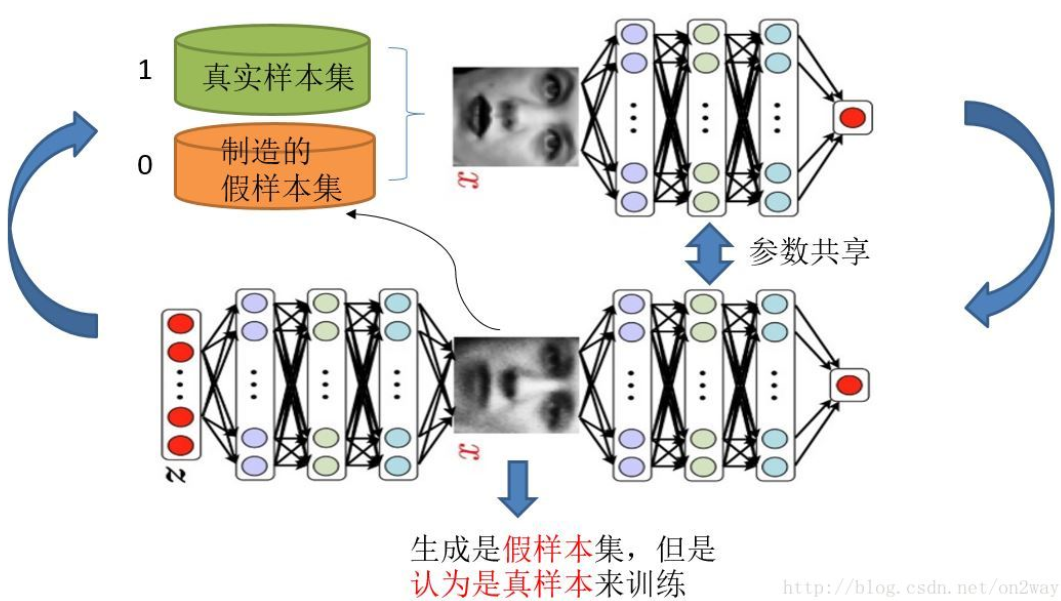
GAN由一个生成器和一个判别器组成。其中,生成器负责生成数据,从真实的数据中生成假的数据,期望假的数据越逼真越好。判别器负责判断接收到的数据是真实的还是产生的,即一个二分类器,期望效果比较好,也就是说真实的数据判别为真的概率更大,假的数据判别为真的概率更小。所以,在生成器期望生成的数据逼真到能够欺骗判别器而判别器期望判别能力强的情况下,通过两者的博弈,来达到生成数据能够模拟真实数据的效果。
2)设计
实现GAN主要是通过Loss的设计,D的输出为数据被判定为真实数据的概率,整体Loss如下:
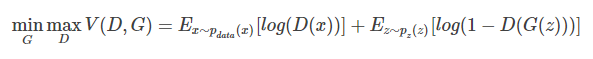
优化D: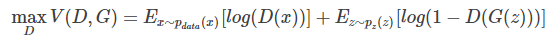
优化G: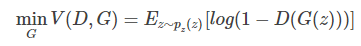
对于上述Loss的解释是,优化判别器D时,希望D判别能力强,那么就希望真实数据被判定为真的概率大,所以Ex~Pdata(x)[log(D(x))]应该比较大,D(G(Z))比较小,Ez~Pz(z)[log(1-D(G(z)))]应该比较大,所以是最大化V(D,G)。优化产生器时,期望伪造数据比较真,那么就希望Z为伪造品时,D(G(Z))比较大,也即Ez~Pz(z)[log(1-D(G(z)))]比较小。
更多关于GAN的解释可见其他博客,这里不做更详细的解释。
3)作用
使得伪造的数据足够逼真,比如从噪声数据,逐步学习,得到人脸数据等。
3.DASC
上面介绍完了DAC和GAN,我们知道DSC已经可以做聚类了,而且聚类算比较好的了,那么还能不能再提高呢?答案是可以。
我们知道,DSC是一步一步训练得到Z来做聚类,其中有个问题是,我们并不确定迭代到多少次效果比较好,也不能确定下次迭代就比上次得到的Z好,那么有没有什么方法能够指导无监督网络DSC的学习,让网络的训练每次都朝着效果更好的方向训练呢?
这就是DASC所做的工作了,基础思想是,用GAN来指导DSC的学习,使其每次都朝着效果更好的方向发展。
二、方法
本章介绍DASC的方法,从原理、生成器、判别器、训练这四个部分分别进行探讨。
1)原理
用GAN指导DSC的学习,就需要明确下面两个问题。
一是,把处于同一子空间的数据,进行线性组合得到新的数据,那么新的数据依然处于该子空间。反之,处于不同子空间的数据,进行线性组合得到的数据跟原始数据处在不同子空间。(可以从下图看出)
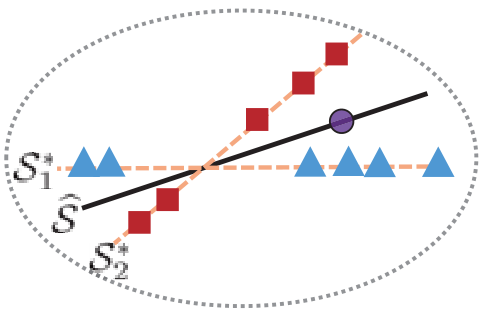
二是,处在同一子空间的数据,判别器(即分类器)分辨不出是真实数据还是伪造的数据,即输出概率为0.5。
通过一二知,聚类效果比较好->新数据依然处于该子空间->判别器无法判别真假。即,判别器越无法判断真假数据,说明聚类效果越好。
所以,我们要做的任务就是,通过生成器得到正(真实数据)次(线性组合得到的伪造数据)品,输入到判别器中,经过对抗学习,得到更好的相似度矩阵θ和特征表达Z,从而来得到最终的聚类结果。
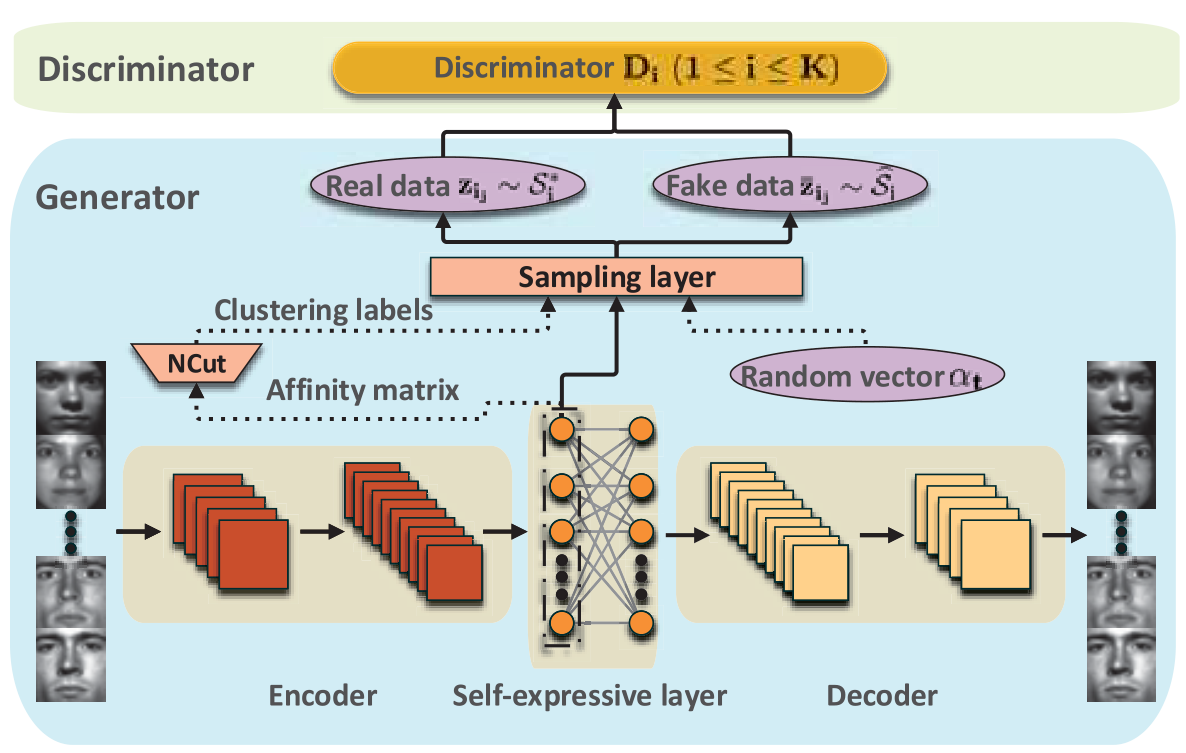
其中,生成器G包括DSC和正次品采样层。下面的DSC得到中间聚类结果后,将Z输入给采样层,采样层得到正次品输入给判别器D。
2)生成器
生成器的操作步骤是:
11)聚类得到Ci和特征表示zi。
22)计算类Ci中zi到相对应的子空间Si的投影残差Lr。其中Si是由投影矩阵Ui来表示的,Ui(或者说Si)是判别器学习得到的,与生成器的学习无关。
![]()
33)选择投影残差Lr最小的80%~90%的Ci中的数据作为正品。(因为经过DSC大部分的数据已经是正确的。这里还可以起到去噪的作用)
44)随机线性组合计算得到与正品同样数量的次品。其中α来于[0-1]中的随机数。
![]()
55)将正次品输给判别器D。

3)判别器
11)学习的参数
学习的参数为子投影矩阵Ui(代表子空间Si),用子空间来判别是正品还是次品。原则是,投影残差Lr越小,说明是正品(文章中说能量越小)的概率越大,对判别器来说Loss的输出也应该越小。反之Loss就越大。所以投影残差Lr即与Loss成反比。
![]()
22)优化
经过上述分析,直接给出Loss优化如下。
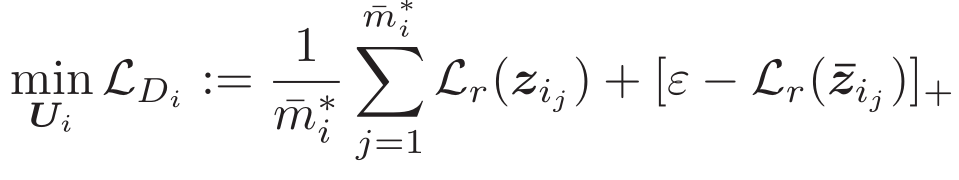
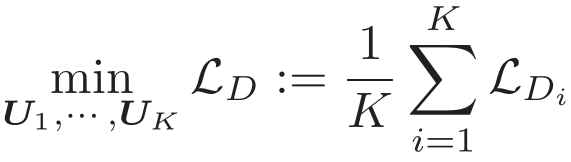
![]()
![]()
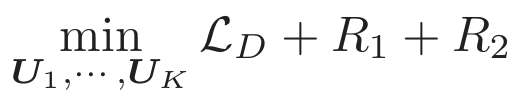
33)细节
投影矩阵Ui和类簇Ci并不是一一对应的关系,因为每次更新都需要找一下是否子空间投影矩阵是否有变化,所以需要Ci进行竞争Ui。竞争的方式是,对每个类簇计算平均投影残差,然后选择具有最小平均残差的Ui作为自己的投影矩阵。如果该Ui具有更小平均投影残差的类簇,那么原类簇则采用对Z进行QR分解来得到自己的Ui。
判别器采用两层全连接感知机。
4)训练
11)DSC预训练初始化DASC网络。
22)用Zi的QR分解初始化Ui。
33)联合交替更新DASC中的D和G,其中D更新五次,G更新一次。
三、实验
直接贴结果吧。


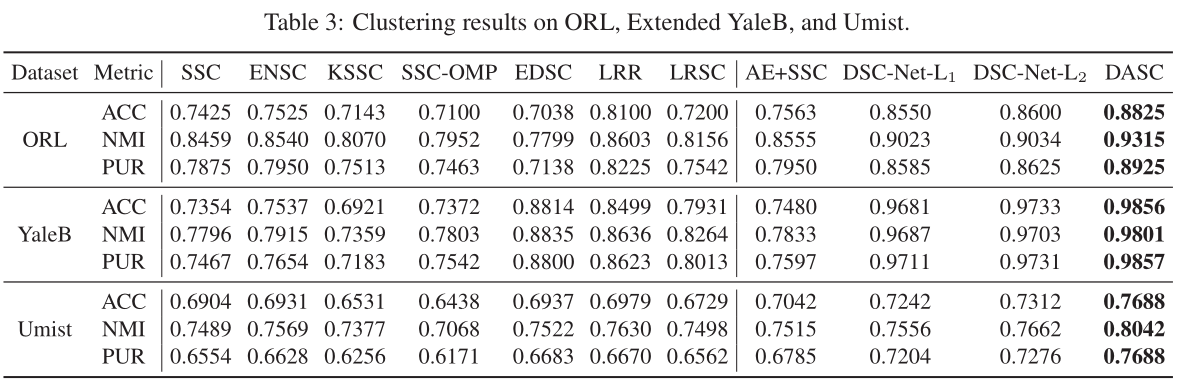
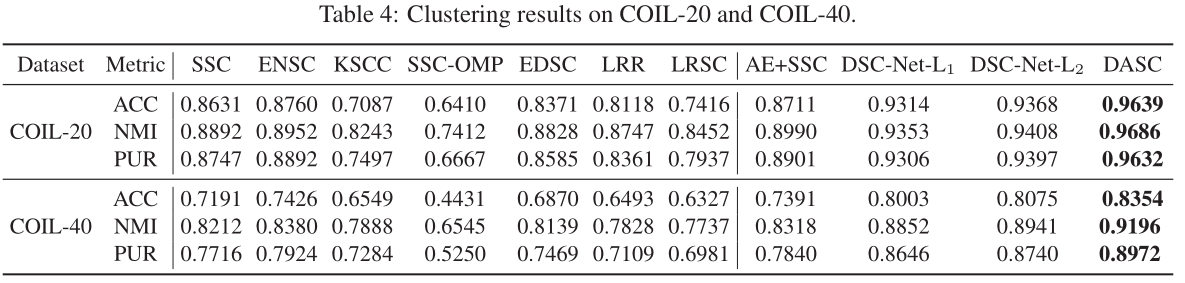
四、总结
1.该文章采用了DSC+GAN的方式,是GAN在无监督聚类上的首次成功运用。
2.文章对无监督的聚类进行了定性的评估:线性组合在同一子空间(不能被判别器正确识别)说明聚类效果好。
3.文章对无监督聚类进行了定量的评估:据子空间的投影残差越小说明属于真实数据的概率越大。
4.在写作方面,文章采用比较新颖刁钻的方式。比如,把投影距离称为能量大小,把线性组合称为新子空间采样。换汤不换药,还显得很好喝,就比较骚了。
---------------------------出自403实验室,链接:https://www.cnblogs.com/EstherLjy/p/9840016.html