An end-to-end TextSpotter with Explicit Alignment and Attention

论文下载:http://cn.arxiv.org/pdf/1803.03474
代码下载:https://github.com/tonghe90/textspotter
1方法概述
1.1主要思路
将文字检测和识别整合到一个端到端的网络中,检测使用PVAnet,识别使用RNN,其中加入一个Text-alignment layer和字符attention和mask机制,通过利用Text-alignment layer中的抽样网格将文字区域固定为64*8大的feature map,再输入双向LSTM进行识别。
1.2文章亮点
·提出Text alignment layer,用网格抽样方案代替RoI Pooling,处理多方向的文本区域
·增加字符attention和mask机制,使用字符的空间信息作为额外的监督,指导decode过程
·提出一个新颖的training strategy
1.3主要流程

·整个端到端识别主要有三个步骤:
·检测:用PVAnet代替ResNet50的EAST框架,得到任意方向的文本区域
·Test alignment:将四边形区域统一映射为大小为64*8的feature map
·识别:Test alignment得到的feature map经过encode-decode得到最终结果
2 方法细节
·检测
·检测的框架是用PVAnet代替ResNet50的EAST框架,通过调节IoU损失实现一个多任务预测。
·最终得到两个分支:第一个子分支返回文本分类概率。第二个子分支返回bounding box的五个参数,分别是当前点到上下左右边的距离以及倾斜角度。
·识别
上述得到的四边形将被输入RNN分支。
·Text-alignment layer:
·这步的目的:
·它可以将任意方向的region proposal固定为统一大小的feature map,精确地跟每个像素对齐
·为什么不用RoI Pooling
·RoI Pooling进行量化,不可避免地在原始RoI区域和提取出来的特性之间引入了misalignment。
·RoI Pooling是为矩形区域设计的,只能够定位水平region proposal。

·Text-alignment layer做什么
·给定一个四边形区域,首先在feature map中建立一个64*8大的采样网格,在这个区域内生成等间距的采样点,Vp代表每个采样点p空间位置(px,py)的特征向量,这个特征向量通过bilinear sampling计算,公式如下:

·Vpi是p周围的四个点,g(m,n)是双线性插值函数
·最终输出固定大小为64*8的文本区域
·Character Attention
·识别流程
·经过Text-Alignment Layer得到的feature map,经过多个inception模块,最终大小变为1*64,然后经过双向LSTM操作,encode-decode操作后输出最终识别结果。
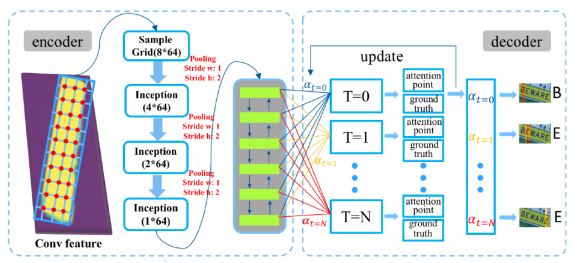
·Attention alignment
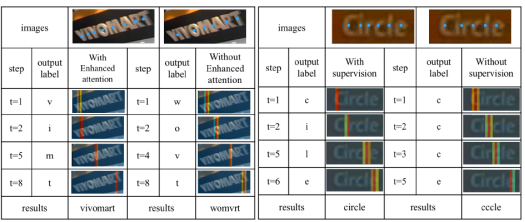
·这张图与传统的注意力机制不同的地方是在增加了字符的attention作为监督,引入了字符对齐的损失函数,指导decode过程。这就是图中update的由来
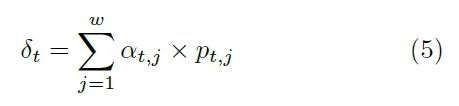
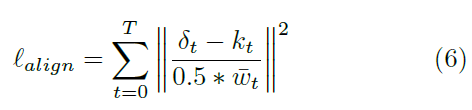
·即attention point,它应该尽可能和字符的中心点尽可能对齐;
·是第t个字符GT的中心坐标,是当前字符的GT宽度,T是一个序列的字符数
·这个损失函数表示归一化的attention
·Character mask
·增加了binary masks,引入,mask数等于字符label数
·Position embedding
·从attention向量中生成一个one-hot向量,然后直接将one-hot向量和上下文向量直接连接起来,得到一个新的带有额外one-hot注意力信息的特征表示。
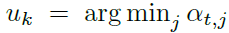
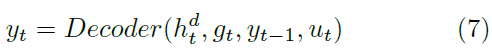
·Overall loss
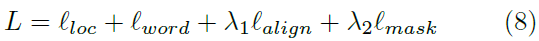
·Lloc是文本检测的loss,Lword是文字识别的loss,Lalign和Lmask是可选的loss,可以不使用。λ1,λ2是平衡因子,这里面的实验都设为0.1。
·Training Strategy
·从800K张合成图像张随机抽取600K张,固定检测部分,提供Ground trut文本框进行单词识别的训练,迭代120K次,只计算识别,字符对齐和mask的loss
·打开检测部分,仍然提供GT文本框,更新权重,迭代80K次,接下来用检测部分生成抽样网格,进行端到端训练,迭代20K次
·在ICDAR2013和2015数据集上进行端到端训练,迭代60K次。
3 实验结果
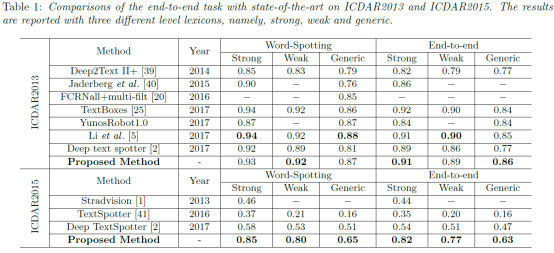
·在ICDAR2013上得到的数据与最先进的结果相当,而在ICDAR2015上,这篇文章的方法大大超过了最新的结果。
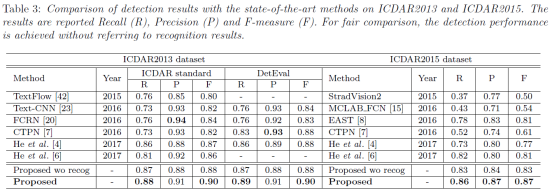
·使用这篇文章的方法,一些小的文字和大幅度倾斜的文字都能很好的被识别到。

4 总结和收获
·检测部分用PVAnet代替ResNet50的EAST框架
·用bilinear sampling代替RoI Pooling,处理多方向的文本区域
·在原有的attention中增加字符的对齐信息和mask作为额外的监督,指导decode过程
·一个新颖的training strategy