参考的有:Apache vlc ACE ftp
我主要需要其中的并发处理,内存管理,TCP/UDP.QoS,速度限制等方面的内容,所以着重说这几方面。
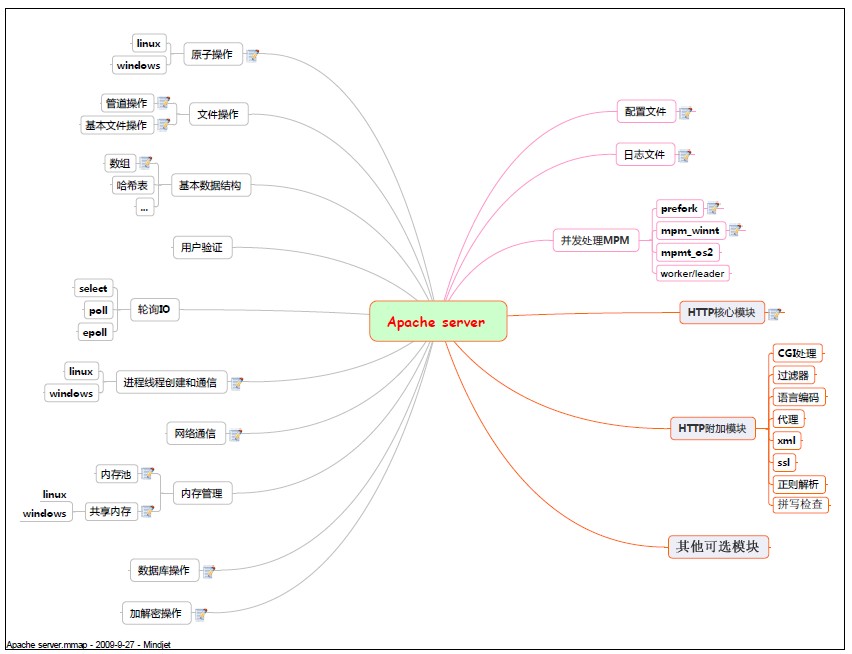
首先看一下Apache的基本框图,左边为APR。
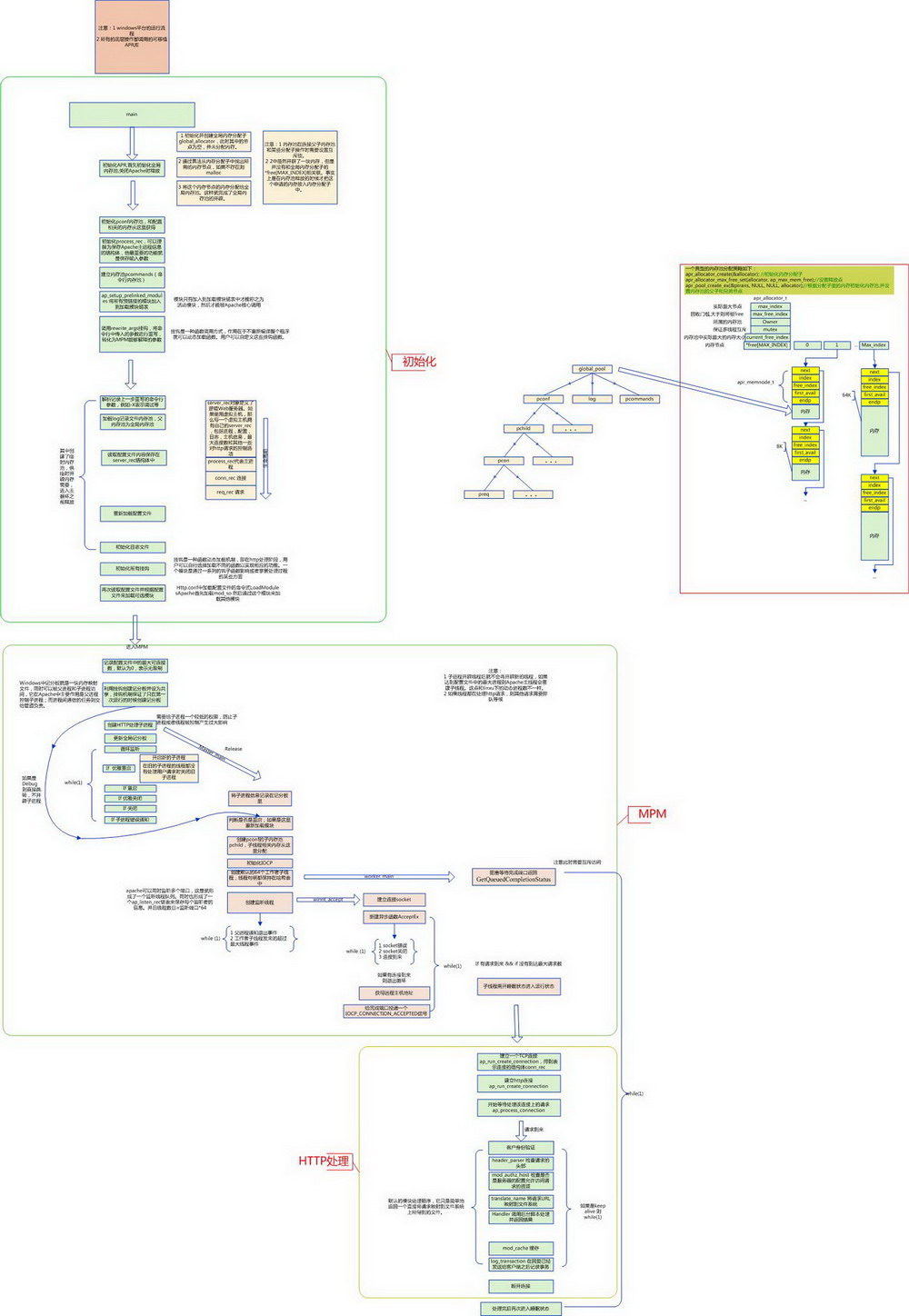
然后是Apache在windows下的运行流程
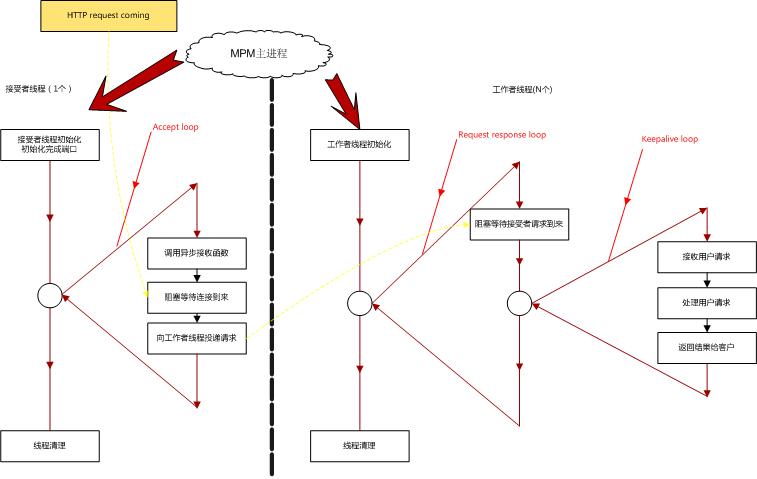
MPM的2种并发模式:
1、 Windows NT/2000下采用的是完成端口,采用生产者消费者模型。具体的原理为:N(N>=1)个接受者线程异步循环监听网络连接,N*64个工作者线程阻塞等待相应的接受者线程投递完成请求,如果有连接到来,接受者线程会投递完成请求,工作者线程收到这个请求之后就建立新的链路来进行数据收发。
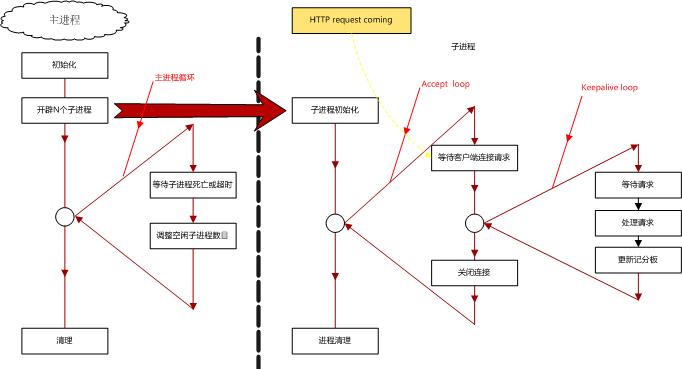
Unix下MPM运行流程
1) 主进程循环
主循环主要是控制进程池中空闲子进程的数目,即循环监控记分板,并根据记分板中子进程的状态作出反应。
2) 客户端请求/响应循环
这个循环只适合于子进程。在该循环中,子进程等待自己变为侦听者,然后等待客户端的连接,一旦获取到连接则变为工作者开始处理请求,同时进入Keep-alive循环中。
3) Keep-alive循环
Keep-alive循环主要是处理客户端的请求,该循环仅仅适合子进程。
4) 在退出之前进行清理工作
结论:每个平台有自己的特点,需要根据平台特性来设计不同的并发处理机制,例如这里Unix平台下使用进程作为处理请求的最小单元,而windows使用线程作为处理请求的最小单元;windows下的完成端口可以提供较高的效率,而Unix下的epoll也具有较高的效率,并且2者不能跨平台使用。
如果要设计一个UDP的并发处理机制,那么要注意以下几点:
(1) TCP是每个客户一个单独的连接,socket表示一个已建立的连接;而最简单的UDP服务器只需要一个socket即可完成对所有客户的操作,这里socket仅仅是单纯的socket,真正的目的地址需要指定。给出一个比较通用的UDP服务器架构,可以看出和TCP服务器设计的不同之处。
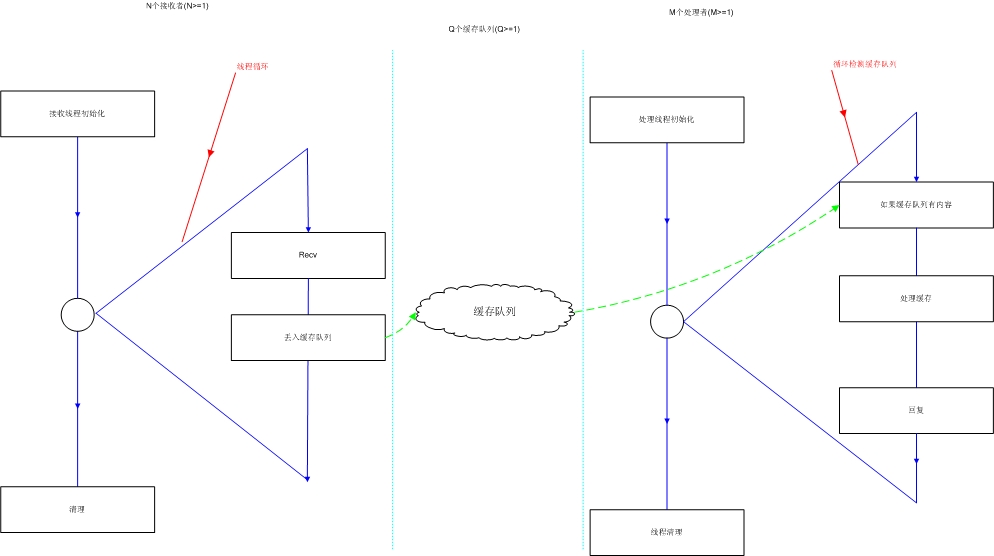
根据计算密集型和I/O密集型来合理控制接收者、缓存队列和处理者的数量就可以相对适应不用的平台。由于需要的是I/O密集型服务器,所以一种合理的假设是N=CPU数量,Q=1,M=50。
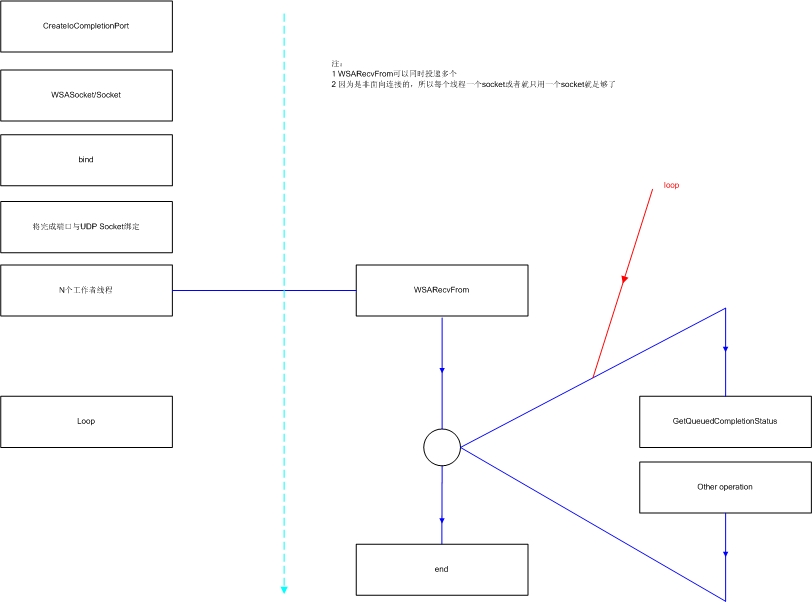
以上只是原理上的考虑,在真正实施上还是应该结合不同的平台利用不同的I/O模型来处理UDP的并发。下面是windows下最简单的IOCP的UDP模型
一、 UDP的质量保证和速度控制
有2种途径,分别是借鉴TCP的实现机制和采用QoS机制
1借鉴TCP
借鉴TCP的滑动窗口机制来控制速度以保证充分利用带宽
TCP的特点之一是提供体积可变的滑动窗口机制,支持端到端的流量控制。TCP的窗口以字节为单位进行调整,以适应接收方的处理能力。处理过程如下:
(1) TCP连接阶段,双方协商窗口尺寸,同时接收方预留数据缓存区;
(2) 发送方根据协商的结果,发送符合窗口尺寸的数据字节流,并等待对方的确认;
(3) 发送方根据确认信息,改变窗口的尺寸,增加或者减少发送未得到确认的字节流中的字节数。调整过程包括:如果出现发送拥塞,发送窗口缩小为原来的一半,同时将超时重传的时间间隔扩大一倍。
TCP的窗口机制保证了流量控制。但是这种控制并不能比较精确的控制速度,而只是更具网络情况来自行调整速度。如果要实现比较精确的限速,则可直接利用定时器函数,但是意义不大。
借鉴TCP的超时重传机制
TCP接收端每次收到数据之后都会发送一个ACK给发送端,发送端根据这个ACK可以来动态控制下次发送数据的时间间隔和发送数据大小。
如果发送端没有得到ACK,则根据丢包比例动态调节重传间隔并根据重传间隔来重传数据。
参考以上TCP机制,一种最简单的可靠并且可控的UDP流程如下: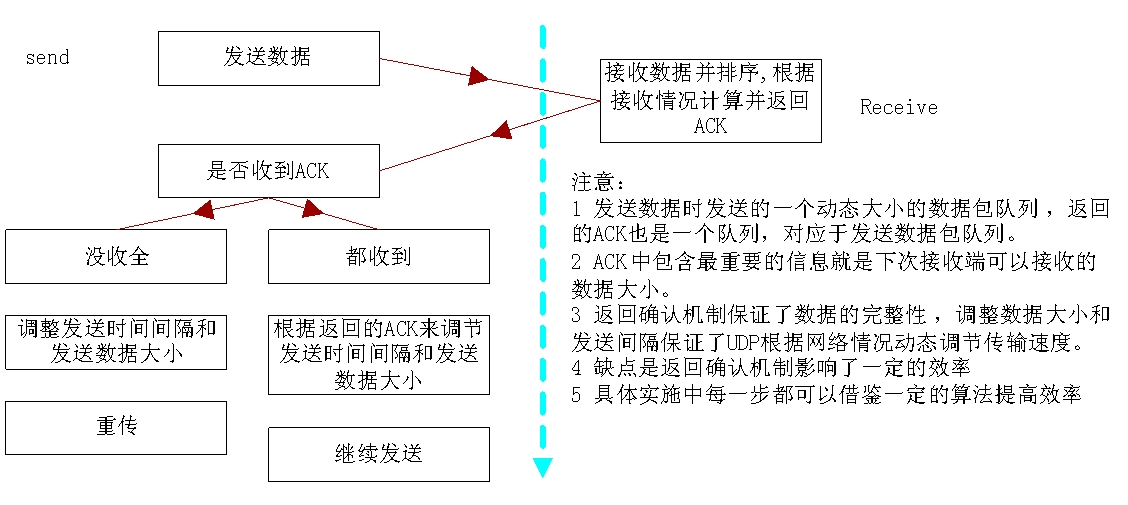
发送端收到的ACK越不全则下次发送的时间间隔越长、数据包越少。
图中用的是收到一个数据包组后返回确认信息。真实环境下可以在一定时间和收到一定数量的包后返回确认信息,当发送端收到这个确认消息之后就可以删除发送缓存队列了,并且改为在接收端一接收到不按顺序的包序后立刻请求发送端重传(发送协议中包含了下一次要发送的数据包序列号)。
优点:实现起来相对简单,并且可以很好的跨平台
缺点:这种方法的可靠性是建立在重传和限速的基础之上,并没有实现数据在主机和网络设备上的优先级处理,竞争处理和优先获取带宽。而这些正是QoS的优点。
2 QoS
QoS就是针对各种不同需求,提供不同服务质量的网络服务功能。和模拟TCP方式的UDP比较起来,使用QoS相对就比较完善,不仅在错误处理和速度控制上有规定,而且在其他很多地方也有优化(例如优先级策略、带宽保持策略等等)
要使用QoS,首先必须有相应的软硬件支持。
注:硬件支持指数据传输要经过的网络设备(如路由器、交换机)和本地工作站(可为自己引入的网络传输分派相应的优先级)的支持,网络设备可以注意到并解析QoS信息(这些信息是保存在RSVP资源预约协议中),并根据这些信息来运行分派调度策略。具体来说就是为使“端到端”的QoS能正常运作,两个端点之间的网络设备必须能对数据通信的优先级加以区分。网络设备对QoS分类的依据就是DSCP(different services code point :区别服务编码点)。而DSCP的数值是由COS或者TOS映射得到的。QOS通过DSCP就可以将非常的多的数据流,简单的规划分类为几个大的数据流。如果不用到QoS的分类,则DSCP等于0,表示一视同仁。
第二层:交换机内部协议ISL
|
ISL包头(26字节,3位用于COS) |
被封装的帧 |
FCS(4字节) |
第三层:路由器 IPV4
|
版本/长度 |
TOS(1字节) |
长度 |
ID |
标记 |
TTL |
协议 |
校验 |
IP-SA |
IP-DA |
数据 |
其中TOS的高3位表示IP优先级
软件支持:首先需要操作系统支持QoS,例如windows中的GQOS组件。如果在广域网下,就要使用RSVP协议,需要路由器支持。网卡要支持802.1p,这样才可以识别OS分配的以太网帧中的优先级位。
QoS的作用体现在:
1. 分类:将数据分为不同的优先级,区别对待。
2. 流量调节:采用一定的策略来控制流量。
3. 拥塞管理:某些特权数据可以插队,优先被转发。
4. 拥塞避免:拥堵时优先丢弃不重要的数据保留重要数据,而不是按照队列顺序丢弃数据。
QoS编程
QoS实现可以分为2大类,一种是IntServ(在基于IP的呼叫两端,先通过信令建立一条虚连接链路,然后呼叫双方的报文都经此链路传递,从而达到保证传输质量的目的),一种是DiffServ(它把流经路由器的数据包按照一定的优先级分类,然后按照优先级顺序将数据包转发至下一跳路由器)。2种方案都有缺陷,目前QoS技术还不成熟,对IntServ而言,当网络规模大到一定程度时,维护链路状态的工作将使核心网路由器不堪重负;如采用采用DiffServ,一旦网络发生拥塞,报文无论优先级多高,一样会被阻塞。
服务器端:可能为windows或linux。windows下有GQOS组件可供调用,该组件是基于RSVP(资源预留协议),该协议通过预留数据链路上节点的带宽来实现IntServ QoS。也可以和linux一样直接修改定制网络驱动层;linux下需要修改定制网络驱动层程序来实现DiffServ QoS,即在网卡发送数据之前先通过一定的策略对数据包进行分类、管理、检测拥堵和处理拥堵(和网络设备类似,内部一般使用多缓冲队列)。
中间层:只要在客户端和服务器端遵照网络层协议格式要求在制定规范中间件就可以自动识别和处理。这部分的编程一般由厂商完成。
客户端:和服务器端收发机制基本相同。