一、先说结论:
同一串字面量,不同编码表现为表示它们的十六进制不同
1.源码文件格式是UTF-8情况下(注意这个大前提,源码编码统一使用UTF-8,使用其他编码会很麻烦,后面会提到),
- 如何拿到字面量在当前源码编码下的十六进制(QByteArray)?
设有字面量"这是中文"
QByteArray localChinese = "这是中文";
qDebug()<<" "<<localChinese;//字面量在UTF-8编码下的十六进制:"xE8xBFx99xE6x98xAFxE4xB8xADxE6x96x87"
在实际编程中,手头拿到的往往是QString而不是QByteArray,所以需要QString转到上面这串QByteArray。
那么问题是,给定QString str = "这是中文",如何拿到它在不同编码下的十六进制(QByteArray)呢?
- 如何拿到字面量相应的QString在UTF-8编码下的十六进制(QByteArray)?有2种方法:
方法1、
str.toUtf8();
方法2、
QTextCodec *pUtf8 = QTextCodec::codecForName("UTF-8");
//fromUnicode可以拿到QString在相应编码下的QByteArray
qDebug()<<"pUtf8->fromUnicode(str):"<<pUtf8->fromUnicode(str);
- 如何拿到字面量相应的QString在GB18030编码下的十六进制(QByteArray)?
QTextCodec *pGBK = QTextCodec::codecForName("GB18030");
//fromUnicode可以拿到QString在相应编码下的QByteArray
qDebug()<<"pGBK->fromUnicode(str):"<<pGBK->fromUnicode(str);
std::string string = pGBK->fromUnicode(str).data();
std::cout<<string<<std::endl;
2、源码文件格式不是UTF-8情况下,建议把源文件拷贝到UTF-8中保存,然后按第1点处理
二、探究过程
分别把"这是中文"字面量以UTF-8和GB18030编码保存,使用BeyondCompare可见相应的十六进制
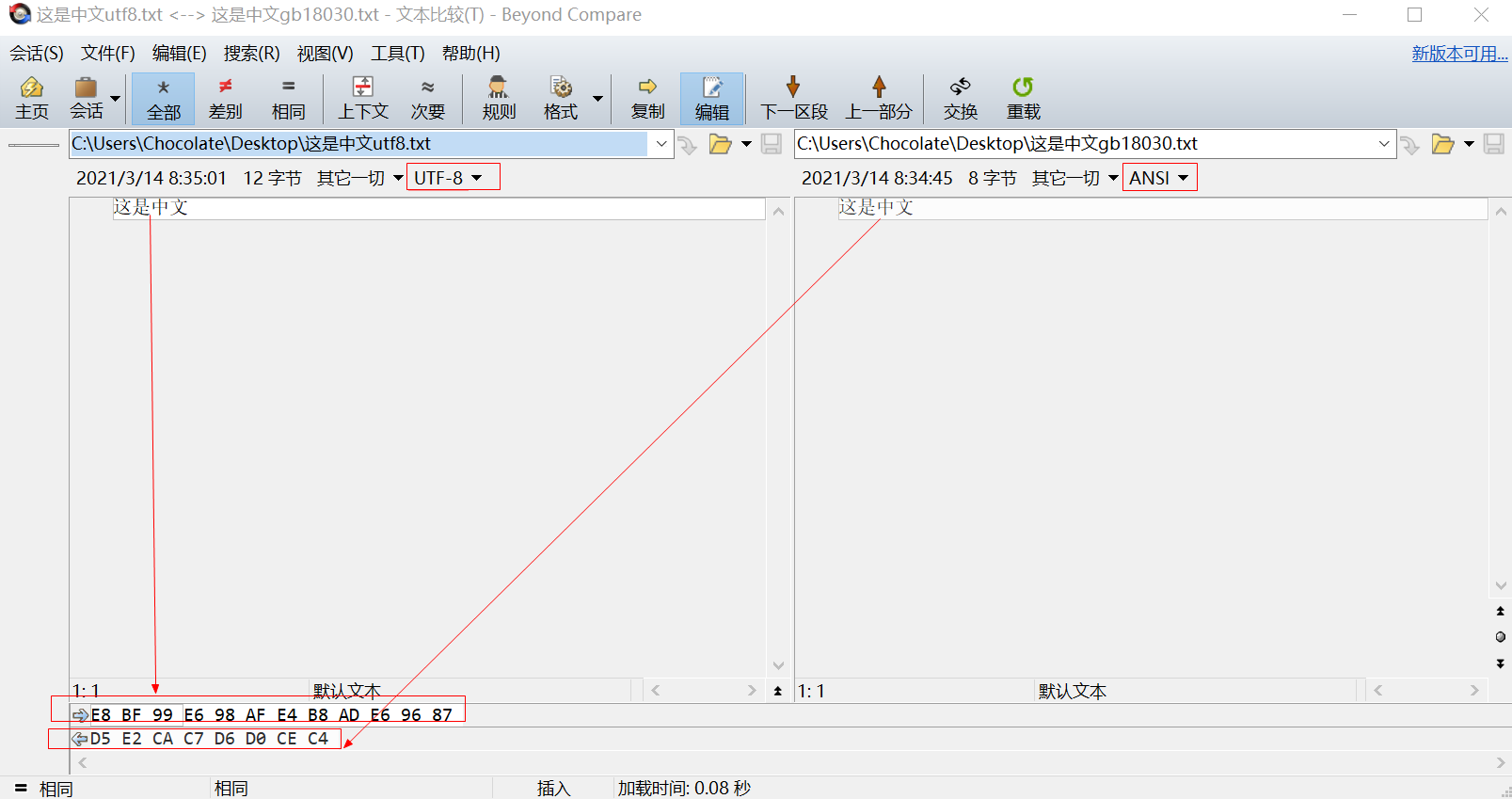
以上用工具(Notepad++ 和 BeyondCompare)做到了两件事:
第一件事是查看字面量在编码下的十六进制
第二件事是将字面量转为不同编码下的十六进制
那么,如何在Qt中做这两件事呢?
先以UTF-8编码下的源码为例,
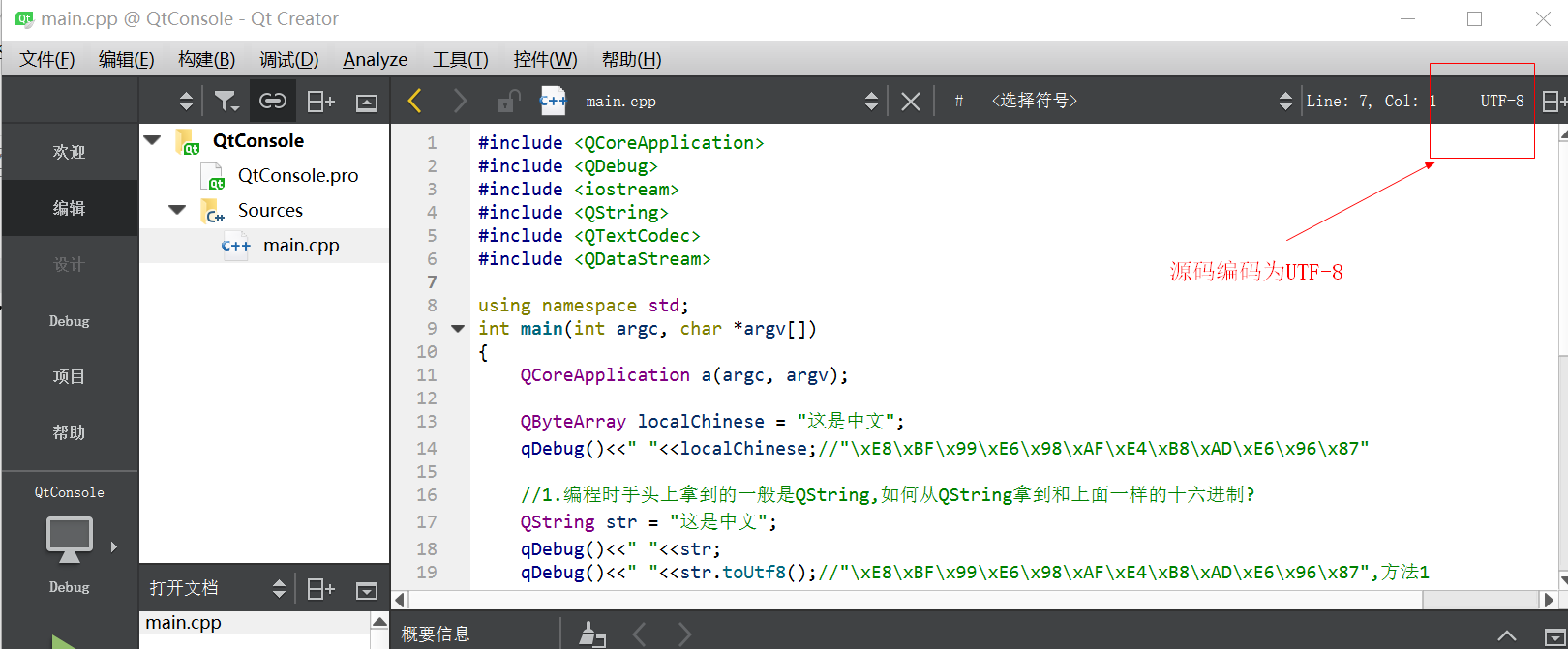
#include <QCoreApplication> #include <QDebug> #include <iostream> #include <QString> #include <QTextCodec> #include <QDataStream> using namespace std; int main(int argc, char *argv[]) { QCoreApplication a(argc, argv); QByteArray localChinese = "这是中文"; qDebug()<<" "<<localChinese;//"xE8xBFx99xE6x98xAFxE4xB8xADxE6x96x87" //1.编程时手头上拿到的一般是QString,如何从QString拿到和上面一样的十六进制? QString str = "这是中文"; qDebug()<<" "<<str; qDebug()<<" "<<str.toUtf8();//"xE8xBFx99xE6x98xAFxE4xB8xADxE6x96x87",方法1 qDebug()<<" "<<str.toLocal8Bit();//"xD5xE2xCAxC7xD6xD0xCExC4" qDebug()<<" "<<str.toLatin1(); QTextCodec *pUtf8 = QTextCodec::codecForName("UTF-8"); //fromUnicode可以拿到QString在相应编码下的QByteArray qDebug()<<pUtf8->fromUnicode(str);//"xE8xBFx99xE6x98xAFxE4xB8xADxE6x96x87",方法2 //2.如何拿到其他编码下的十六进制? QTextCodec *pGBK = QTextCodec::codecForName("GB18030"); //fromUnicode可以拿到QString在相应编码下的QByteArray qDebug()<<pGBK->fromUnicode(str);//方法非常简单,直接把源QString传进来,用相应编码QTextCodec调用fromUnicode即可得到 std::string string = pGBK->fromUnicode(str).data(); std::cout<<string; return a.exec(); }
如果源码编码不是UTF-8,那么这两件事就比较麻烦了。下面以源码编码为GB18030为例
#include <QCoreApplication> #include <QDebug> #include <iostream> #include <QString> #include <QTextCodec> #include <QDataStream> int main(int argc, char *argv[]) { QCoreApplication a(argc, argv); //要做编码转换,先从QByteArray转到Unicode QString,往往手头上拿到的是QString //那么首先要把QString转成相应编码格式下QByteArray //QString如何转到相应编码格式下的QByteArray,也就是十六进制 QByteArray localChinese = "这是中文"; qDebug()<<" "<<localChinese;//"xD5xE2xCAxC7xD6xD0xCExC4" //1.编程时手头上拿到的一般是QString,如何从QString拿到和上面一样的十六进制?(笔者目前尚未能够拿到) //和源文件为UTF-8编码下不同,源文件在GB18030编码下,QString自带的三个函数无法获得目标十六进制 QString str = "这是中文"; qDebug()<<" "<<str;//"????????" qDebug()<<" "<<str.toUtf8();//"xEFxBFxBDxEFxBFxBDxEFxBFxBDxEFxBFxBDxEFxBFxBDxEFxBFxBDxEFxBFxBDxEFxBFxBD" qDebug()<<" "<<str.toLocal8Bit();//"????????" qDebug()<<" "<<str.toLatin1();//"????????" //2.如何拿到其他编码下的十六进制?(笔者目前尚未能够拿到) //和源文件为UTF-8编码下不同,源文件在GB18030编码下,无法像前者那样简单的在不同的十六进制编码间切换 QTextCodec *pGBK = QTextCodec::codecForName("GB18030"); //"x84""1xA4""7x84""1xA4""7x84""1xA4""7x84""1xA4""7x84""1xA4""7x84""1xA4""7x84""1xA4""7x84""1xA4""7" qDebug()<<pGBK->fromUnicode(str); QTextCodec *pUtf8 = QTextCodec::codecForName("UTF-8"); //"xEFxBFxBDxEFxBFxBDxEFxBFxBDxEFxBFxBDxEFxBFxBDxEFxBFxBDxEFxBFxBDxEFxBFxBD" qDebug()<<pUtf8->fromUnicode(str); return a.exec(); }
从中可以看出,源码使用UTF-8编码的情况下,拿到字面量相应字符串在不同编码下的十六进制是很简单的事情。但如果源码未使用UTF-8的情况下,至少QString自带的三个toXXX函数都无法拿到想要的十六进制,如果源码使用了和QTextCodec::codecForLocale不同的编码,那么问题更加棘手。所以,先保证源码的编码为UTF-8前提下,再考虑QString到QByteArray的转换问题。