一、HDFS1.x架构图
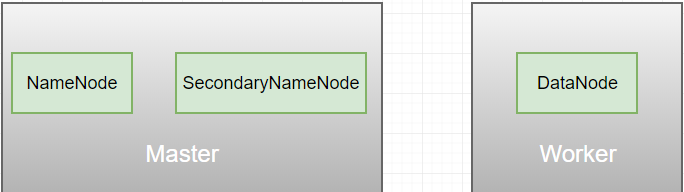
对于HDFS1.x来讲,它的架构图由三个组件组成:NameNode、SecondaryNameNode和DataBode。
稍微了解过hadoop1.x的同学,就会知道hadoop1.x集群里面的资源管理和作业调度及监控都是有NameNode负责,一个集群,只有一台机器(Master)有NameNode进程,这就出现一个问题,当这个NameNode进程,或者Master机器出现异常,那么整个集群的运作将会受到非常非常大的影响。
二、对于Hadoop1.x的单点问题解决
对于HDFS1.x的单点问题,一般有两种解决方案:
将hadoop元数据写入到本地文件系统的同时,再同步到一个远程挂载网络系统NFS(Network Files System);
运行一个SecondaryNameNode,通过合并镜像的方式保存NameNode元数据,当NameNode发生故 障时它会通过自己合并的命名空间镜像副本来恢复;
对于方案一,NFS相当于是另外的一个叫系统,如果要使用的话,就需要在hadoop集群上另外再搭建一个系统,这相对来说会麻烦一点,而且依赖性变高;
对于方案二,是hadoop自带提供的解决方案,NameNode中存储的是元数据,以及命名空间,进行元数据持久化时,在NameNode中存放元信息的文件是 fsimage。在系统运行期间 所有对元信息的操作都保存在内存中并被持久化到另一个文件 edits中。并且edits文件和fsimage文件会被 SecondaryNameNode周期性的合并。
SecondaryNameNode如何周期性的合并edits文件和fsimage文件呢?

hadoop1.x正常运作:当NameNode重启的时候,首先读取fsimage文件,然后将一些改动的操作记录写入到edits log文件里面。

随着时间的推移,edit logs文件存的改动操作数据就会越来越多,有可能溢出,或者加载读取时变得很慢,fsimage就会出现滞后性,为了保证NameNode在重启的时候能够读取到最新的fsimage数据,就出现了上面的结构。SecondaryNameNode会定时查询NameNode的edit logs文件,看是否有更新,集群运作的过程中,当DataNode有数据变动了,NameNode存储的元数据或者命名空间就会发生变化,一旦变化,就会触发NameNode对edit logs的写操作,此时,SecondaryNameNode发现NameNode的edit logs文件发生变化,就会将这些改动同步更新到自己的fsimage文件中,紧随着,就会将fsimage文件copy到NameNode节点的fsimage中,这样就可以让NameNode在重启时能够快速的读取fsimage文件,而且还减少了fsimage与edit logs文件的merge过程。
三、Hadoop2.x的HA原理
对于HDFS1.x来说,不管SecondaryNameNode的定时查询,还是快速读取fsimage文件也好,都会存在一个延时性。因此,HDFS2.x做了一个很大的变革——Hadoop HA。
HDFS的高可用性将通过在同一个集群中运行两个NameNode ( active NameNode & standby NameNode )来解决 。
- 在任何时间,只有一台机器处于Active状态;另一台机器是处于Standby状态 ;
- Active NN负责集群中所有客户端的操作;
- Standby NN主要用于备用,它主要维持足够的状态,如果必要,可以提供快速 的故障恢复。

现在的架构图变成上图这样子。Active NameNode和Standby NameNode分别位于不同的服务机器,处于Active状态的NameNode,承担着整个集群的所有对客户端的操作,相对的Standby NameNode则只是跟Active NameNode保持一个通信关系,进行数据同步,必要时转换为Active状态,为集群提供服务。
HDFS2.x官方架构图:

DN同步数据到NN的原理跟在HDFS1.x时的原理是一样的,同步命名空间,则借助QJM(共享文件系统,里面启动多个、奇数个的JournalNode),因为DN不存储命名空间的信息。对于QJM,为了保证数据的同步,至少需要3个JN进程,如果有2n+1个JN进程,最多允许挂掉n个JN进程。Active NameNode在JN里写入数据的时候,只要超过一半的JN写入成功,那么就认为写操作成功。
hadoop2.x是借用zookeeper实现HDFS2.x的HA,ZookeeperFileOverController(ZKFC)作为NN和zookeeper的中间件,建立它们的关系(非直接关系),ZKFC对NN的状态进行监控,可以理解为一个“开关”。为什么要使用ZKFC呢?假设没有ZKFC的时候,Active NN挂掉了,它里面的数据是异常的,但它仍然会对客户端提供服务,这很明显不合理,而处于Standby的NN没有得到“打开”的指令,它也不会对外提供服务,使得整个集群不可以正常运作。每个NN对应一个ZKFC,ZKFC分别监控各自的NN状态,Active NN的正常状态是Active,Standby NN的正常状态是Standby;如果某个NN对应的状态是Active,那么其对应的ZKFC会有(创建)一个临时节点,持有一把锁;对于Standby NN,会通过ZKFC不停地访问ZK,看是否存在这把锁,如果没有,就去创建,然后争取,如果争取不到,那么证明本地机器里面已经有NN处于Active。
避免分歧:任何情况下,NameNode只有一个Active状态,否则导致数据的丢 失及其它不正确的结果 。如果做到呢?这就需要借助数据库锁的机制去理解。
如上图,从左往右看,刚开始工作,会生成一个用于标记的值,假如是1,然后会同步复制到DN里面,然后Active NN与DNs开始进行交互,DNs会遵循一个机制:只处理大于等于DN存储值的NN的操作,也就是说,DN与NN交互前,会判断它当前存储的值是否等于或小于NN的值。某一时刻,Active NN挂了,原先是Standby状态的NN变成Active状态,如图的右侧。首先,会同步已经挂掉的NN存储标记值,并累加1,现在变成2了,然后与DNs进行交互,DNs发现自己的标记值比NN的标记值小,那么就允许交互,并同步新的标记值,覆盖旧的。如果一段时间后,挂掉的NN突然恢复正常了,而ZKFC具有一定的滞后性,没有立刻通知挂掉的NN已经不是Active状态,该NN仍然认为自己是Active,会继续给DNs提供服务,但是,DNs检测到该NN存储的标记值是1,比它们当前存储的标记值2要小,因此不与该NN进行交互,NN只好等待ZKFC通知它需要进入Standby状态。对于NN与QJM的交互,原理也是一样。