写在最前,本次环境搭建是在Hadoop2.6.1,Zookeeper3.4.11,三节点的基础上完成的。
(关于搭建Hadoop环境,可参考:https://blog.csdn.net/weixin_39400271/article/details/89057884
关于搭建zookeeper环境,可参考:https://blog.csdn.net/weixin_39400271/article/details/90552155
另外,本文最后用到flume测试,因此,flume环境搭建可参考:https://blog.csdn.net/weixin_39400271/article/details/90760537)
说明:
#master,表示在master节点上操作;
#master,#slave1,#slave2,表示在三个节点上都要操作;
还有一点需要注意的是,本篇文章介绍的是Hadoop+Zookeeper+Kafk。Kafka集群的启动需要依赖zookeeper集群。
一、准备工作
当官网下载Kafaka的tgz压缩包:http://mirror.bit.edu.cn/apache/kafka/0.10.2.1/kafka_2.11-2.2.0.tgz
scp命令远程分发到CentOS7的master机器指定目录上。
#master
解压:
tar -zxvf kafka_2.11-2.2.0.tgz
二、修改Kafka配置文件
#master
cd /usr/local/src/kafka_2.11-2.2.0/config/
vim server.properties
添加内容:
找到log.dir和zookeeper.connect两处地方进行修改,
log.dirs=/tmp/kafka-logs
zookeeper.connect=master:2181,slave1:2181,slave2:2181
三、配置环境变量
#Master、Slave1、Slave2
export KAFKA_HOME=/usr/local/src/kafka_2.11-2.2.0
export PATH=$KAFKA_HOME/bin:$PATH
刷新环境变量:
vim ~/.bashrc
四、分发文件
scp -r /usr/local/src/kafka_2.11-2.2.0 root@slave1:/usr/local/src/kafka_2.11-2.2.0
scp -r /usr/local/src/kafka_2.11-2.2.0 root@slave2:/usr/local/src/kafka_2.11-2.2.0
五、修改kafka的server.properties文件
cd /usr/local/src/kafka_2.11-2.2.0
#master
对于master,不需要修改,因为内容使用默认的;
#slave1
vim ./server.properties
找到下面位置:

修改为:

#slave2
vim ./server.properties
找到下面位置:
修改为:

六、启动Kafka集群
#master、slave1、slave2
1、 启动zookeeper
zkServer.sh start
2、配置启动项
cd /usr/local/src/kafka_2.11-2.2.0/bin/
vim ./start-kafka.sh
添加内容:
/usr/local/src/kafka_2.11-2.2.0/bin/kafka-server-start.sh /usr/local/src/kafka_2.11-2.2.0/config/server.properties
给启动文件添加权限:
chmod +x /usr/local/src/kafka_2.11-2.2.0/bin/start-kafka.sh
启动:
./start-kafka.sh
3、 查看进程
#master
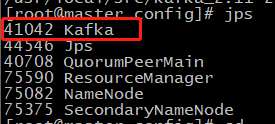
#slave1
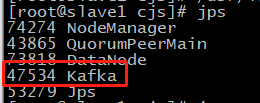
#slave2

4、 关闭集群
/usr/local/src/kafka_2.11-2.2.0/bin/kafka-server-stop.sh
zkServer.sh stop
/usr/local/src/hadoop-2.6.1/sbin/stop-all.sh
七、使用flume组合kafka
使用flume作为信息收集源,然后发送给kafka,再用kafka的consumer进行消费。
1、创建flume-kafka.conf文件
#master
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /usr/local/src/apache-flume-1.6.0-bin/data/hadoop/flume/test.txt
# 设置kafka接收器
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
# 设置kafka的brokerList地址和端口号
a1.sinks.k1.brokerList=192.168.112.10:9092
# 设置kafka的topic
a1.sinks.k1.topic = test
# 设置序列化的方式
a1.sinks.k1.serializer.class = kafka.serializer.StringEncoder
# Use a channel which buffers events inmemory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 1000
# bind a channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2、创建kafka的topic
三台机器的kafka都是启动状态,因为创建topic是在具有broker运行的状态下才可以,像下面的语句,则需要至少启动2台机器的kafka,
#master
cd /usr/local/src/kafka_2.11-2.2.0/
./bin/kafka-topics.sh --create --zookeeper master:2181 --replication-factor 2 --partitions 2 --topic test
3、启动flume
开启一个#master终端,
cd /usr/local/src/apache-flume-1.6.0-bin/
./bin/flume-ng agent -c conf -f conf/flume-kafka.conf -n a1 -Dflume.root.logger=INFO,console
4、开启kafka消费
再开启一个#master终端,
cd /usr/local/src/kafka_2.11-2.2.0/
./bin/kafka-console-consumer.sh --bootstrap-server master:9092 --topic test --from-beginning
5、手动产生消息
再开启一个#master终端,
echo 'hello kafka' >> /usr/local/src/apache-flume-1.6.0-bin/data/hadoop/flume/test.txt
查看kafka-consumer的终端:

顺便提一下,kafka的2.11-2.2.0版本和2.11-0.10.1版本在启动命令上有很大区别,譬如这里做测试的启动kafka-consumer的命令:
2.11-2.2.0版本
./bin/kafka-console-consumer.sh --bootstrap-server master:9092 --topic test --from-beginning
2.11-0.10.1版本
./bin/kafka-console-consumer.sh --zookeeper master:2181 --topic test --from-beginning
八、多producer——单topic——多consumer
kafka cluster由三台机器组成,分别是master,slave1和slave2。分别zookeeper和kafka,另外再开启3个master终端和3个slave1终端,分别命名为view:master、producer:master和consumer:master,以及view:slave1、producer:slave1和consumer:slave1。如下图:

查看zookeeper集群上有哪些kafka的topic,

这三条命令一样功能,因为都是属于2181集群,从上图可以看到目前之创建了一个topic,名字是“test1”.那么就用这个topic搞事情。
1、在producer:master和producer:slave1启动生产者进程:
./bin/kafka-console-producer.sh --broker-list master:9092 --topic test1
两台机器都是使用一模一样的命令,都是向master的9092端口,topic为test1发送消息;
2、在consumer:master和comsumer:slave1启动消费者进程:
consumer:master:
./bin/kafka-console-consumer.sh --zookeeper master:2181 --topic test1 --consumer-property group.id=group_test1
consumer:slave1:
./bin/kafka-console-consumer.sh --zookeeper master:2181 --topic test1 --consumer-property group.id=group_test2
对于consumer:master和consumer:slave1,分别指定了它们订阅了名为“test1”的topic,而且指定了它们是属于哪个Consumer Group,因为不同的consumer(consumer group)不可以命名为同一个consumer group name。
3、开始测试
在producer:master输入:
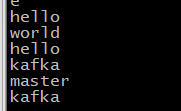
在producer:slave1输入:

分别查看consumer:master和consumer:slave1:
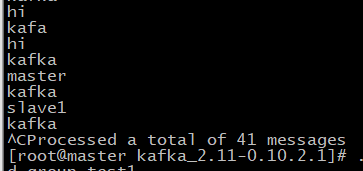
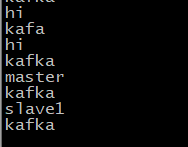
在producer:master发送了“master”、“kafka”,在producer:slave1发送了“slave1”、“kafka”,在两个consumer终端这四个消息都收到了。
在view:master和view:slave1查看offset等信息:
view:master:
./kafka-consumer-offset-checker.sh --zookeeper master:2181 --topic test1 --group group_test1 --broker-info

view:slave1:
./kafka-consumer-offset-checker.sh --zookeeper master:2181 --topic test1 --group group_test2 --broker-info

从信息上来看,也说明了对于offset,是由consumer自己保存管理的,当然zookeeper也会保存和管理,kafka集群的broker是属于无状态的。