https://blog.csdn.net/geekmanong/article/details/51559273
分治法的设计思想:将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以便各个击破,分而治之。凡治众如治寡,分数是也。——孙子兵法
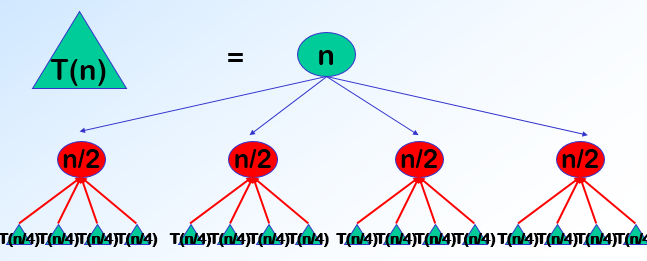
分治法所能解决的问题一般具有以下几个特征:
I. 该问题的规模缩小到一定的程度就可以容易地解决;
II. 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质
III. 利用该问题分解出的子问题的解可以合并为该问题的解;
IV. 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子问题。
注意:如果各子问题是不独立的,则分治法要做许多不必要的工作,重复地解公共的子问题,此时虽然也可用分治法,但一般用动态规划较好。
例子,快排,归并排序均属于分治法
#include <vector> #include <iostream> #include<queue> #include<set> #include <functional> // std::greater using namespace std; struct ListNode { int val; ListNode* next; }; struct cmp { bool operator()(ListNode* a, ListNode* b) { return a->val > b->val; } }; ListNode* merge_lists_by_heap(vector<ListNode*>& all_lists) { if (all_lists.size() == 0) { return nullptr; } //priority_queue<>默认是大根堆的,这是因为优先队列队首指向最后,队尾指向最前面的缘故! // cmp >相当于构建最小堆 priority_queue<ListNode*, vector<ListNode*>, cmp> heap; for(int i = 0; i < all_lists.size(); i++) { heap.push(all_lists[i]); } ListNode* head = nullptr; ListNode* current = nullptr; ListNode* pre = nullptr; while (!heap.empty()) { current = heap.top(); heap.pop();
if (head == nullptr) { head = current; pre = current; } else { pre->next = current; pre = current; }
ListNode* next = current->next;
if (next != nullptr) {
heap.push(next);
}
}
return head;
}
ListNode* merge_two_lists(ListNode* L1, ListNode* L2) { if (L1 == NULL && L2 == NULL) return NULL; else if (L1 == NULL) return L2; else if (L2 == NULL) return L1; ListNode* newHead = NULL; ListNode* p = NULL; if (L1->val < L2->val){ newHead = L1; p = L1; L1 = L1->next; } else{ newHead = L2; p = L2; L2 = L2->next; } while (L1 != NULL && L2 != NULL) { if (L1->val < L2->val) { p->next = L1; L1 = L1->next; } else { p->next = L2; L2 = L2->next; } p = p->next; } p->next = L1 ? L1 : L2; return newHead; } ListNode* merge_lists(vector<ListNode*> all_lists, int low, int high) { if (low == high) return NULL; if (high - low == 1) return all_lists[low]; if (high - low == 2) return merge_two_lists(all_lists[low], all_lists[high - 1]); int mid = (high + low) / 2; ListNode* a = merge_lists(all_lists, low, mid); ListNode* b = merge_lists(all_lists, mid, high); return merge_two_lists(a, b); } //方法二:分治法 //利用归并排序的思想,利用递归和分治法将链表数组划分成为越来越小的半链表数组, //再对半链表数组排序,最后再用递归步骤将排好序的半链表数组合并成为越来越大的有序链表 ListNode* merge_lists_by_divide(vector<ListNode*> all_lists, int K) { return merge_lists(all_lists, 0, K); } ListNode* CreateListNode(int value) { ListNode* pNode = new ListNode(); pNode->val = value; pNode->next = NULL; return pNode; } void DestroyList(ListNode* pHead) { ListNode* pNode = pHead; while (pNode != NULL) { pHead = pHead->next; delete pNode; pNode = pHead; } } void ConnectListNodes(ListNode* pCurrent, ListNode* pNext) { if (pCurrent == NULL) { printf("Error to connect two nodes. "); exit(1); } pCurrent->next = pNext; } int main() { vector<ListNode*> lists; ListNode* pNode1 = CreateListNode(1); ListNode* pNode2 = CreateListNode(2); ListNode* pNode3 = CreateListNode(3); ListNode* pNode4 = CreateListNode(4); ListNode* pNode5 = CreateListNode(2); ListNode* pNode6 = CreateListNode(3); ListNode* pNode7 = CreateListNode(4); ListNode* pNode8 = CreateListNode(5); ListNode* pNode9 = CreateListNode(6); ListNode* pNode10 = CreateListNode(7); ListNode* pNode11 = CreateListNode(8); ListNode* pNode12 = CreateListNode(9); ConnectListNodes(pNode1, pNode2); ConnectListNodes(pNode2, pNode3); ConnectListNodes(pNode3, pNode4); ConnectListNodes(pNode5, pNode6); ConnectListNodes(pNode6, pNode7); ConnectListNodes(pNode7, pNode8); ConnectListNodes(pNode9, pNode10); ConnectListNodes(pNode10, pNode11); ConnectListNodes(pNode11, pNode12); ListNode* L1 = pNode1; ListNode* L2 = pNode5; ListNode* L3 = pNode9; cout << "链表l1: "; while (L1) { cout << L1->val << " "; L1 = L1->next; } cout << endl; cout << "链表l2: "; while (L2) { cout << L2->val << " "; L2 = L2->next; } cout << endl; cout << "链表l3: "; while (L3) { cout << L3->val << " "; L3 = L3->next; } cout << endl; lists.push_back(pNode1); lists.push_back(pNode5); lists.push_back(pNode9); //ListNode* res = merge_lists_by_heap(lists); ListNode* res = merge_lists_by_divide(lists, 3); cout << "合并后链表: "; while (res) { cout << res->val << " "; res = res->next; } cout << endl; system("pause"); DestroyList(res); return 0; }